[Database] (쉬운 코드) group by, aggregate function, order by
쉬운 코드 강의 「데이터베이스」 내용을 바탕으로, SQL에서 group by, aggregate function, order by의 의미와 특징을 정리한 포스트 입니다.
아래의 내용은 MySQL 기준으로 작성한 것입니다. 다른 RDBMS의 SQL 문법은 조금씩 다를 수 있습니다.
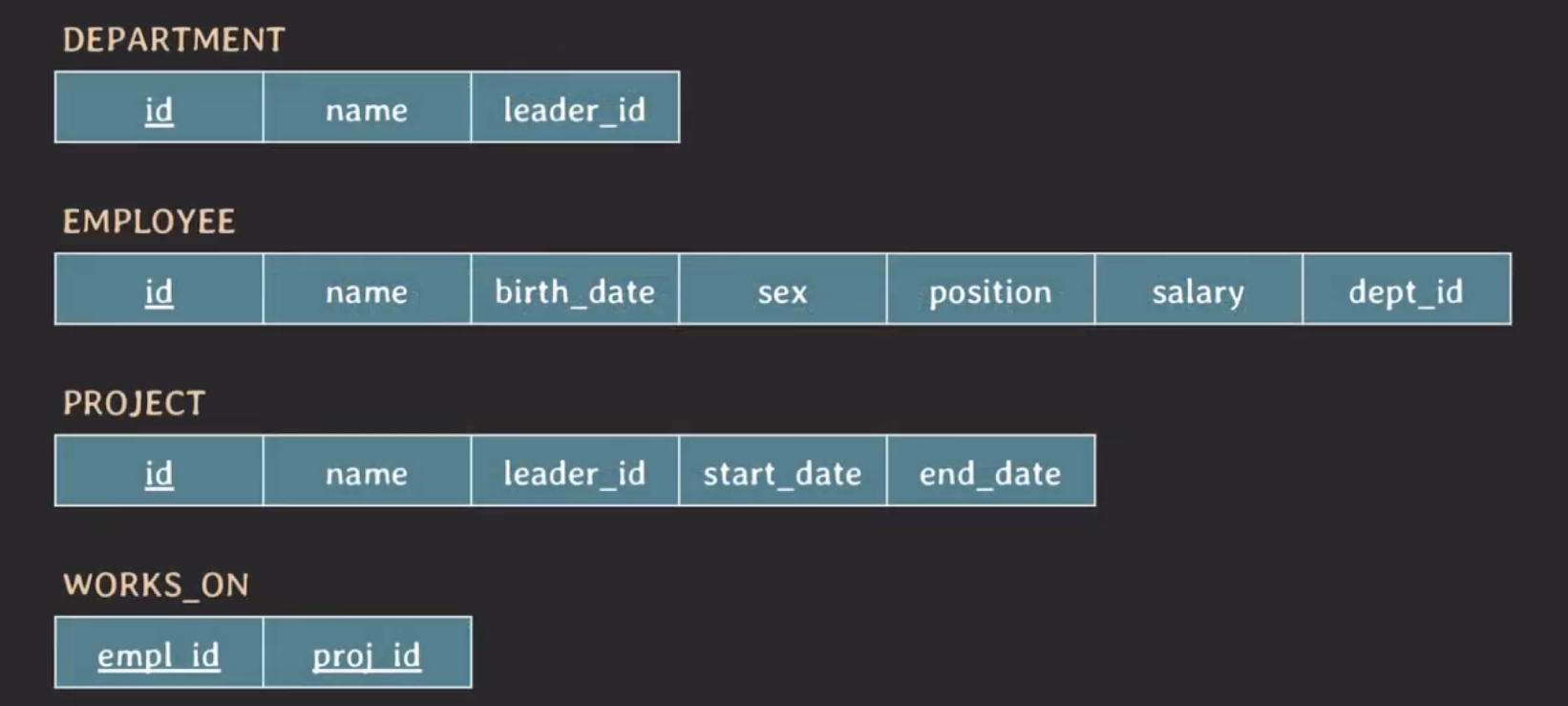
테이블 구조
우선 시작하기에 앞서 내용 이해에 필요한 테이블 구조입니다.
ORDER BY
ORDER BY는 조회 결과를 특정 attribute(s) 기준으로 정렬하여 가져오고 싶을 때 사용한다.
- default 정렬 방식은 오름차순이다.
- 오츰차순 정렬은
ASC로 표기한다. - 내림차순 정렬은
DESC로 표기한다.
ex. 임직원들의 정보를 연봉 순서대로 정렬해서 알고 싶다
1
2
3
4
5
-- 오름차순 --
SELECT * FROM employee ORDER BY salary;
-- 내림차순 --
SELECT * FROM employee ORDER BY salary DESC;
만약에 여기서 추가로 부서별로 묶어서 같은 부서 안에서 연봉별로 정렬을 하려면 어떻게 해야할까?
1
SELECT * FROM employee ORDER BY dept_id ASC, salary DESC;
aggregate function
aggregate function은 여러 tuple들의 정보를 요약해서 하나의 값으로 추출하는 함수로 대표적으로 COUNT, SUM, MAX, MIN, AVG 함수가 있다.
- 주로 관심있는 attribute에 사용된다.
- e.g. AVG(salary), MAX(birth_date)
- NULL 값들은 제외하고 요약 값을 추출한다.
ex. 임직원 수를 알고 싶다.
1
SELECT COUNT(*) FROM employee;
*: 튜플의 수
ex. 프로젝트 2002에 참여한 임직원 수와 최대 연봉과 최소 연봉과 평균 연봉을 알고 싶다.
1
2
3
SELECT COUNT(*), MAX(salary), MIN(salary), AVG(salary)
FROM works_on W JOIN employee E ON W.empl_id = E.id
WHERE W.proj_id = 2002;
GROUP BY
GROUP BY는 관심있는 attribute(s) 기준으로 그룹을 나눠서 그룹별로 aggregate function을 적용하고 싶을 때 사용한다.
- grouping attribute(s): 그룹을 나누는 기준이 되는 attribute(s)
- grouping attribute(s)에 NULL 값이 있을 때는 NULL 값을 가지는 tuple끼리 묶인다.
ex. 각 프로젝트에 참여한 임직원 수와 최대 연봉과 최소 연봉과 평균 연봉을 알고 싶다.
1
2
3
SELECT W.pro_id, COUNT(*), MAX(salary), MIN(salary), AVG(salary)
FROM works_on W JOIN employee E ON W.empl_id = E.id
GROUP BY W.proj_id;
HAVING
만약에 위의 조건에서 특정 조건을 더 부여하고 싶으면 어떻게 해야할까?
이때, 사용하는 키워드가 바로 HAVING 이다. HAVING은 GROUP BY와 함꼐 사용한다.
- aggregate function의 결과값을 바탕으로 그룹을 필터링하고 싶을 때 사용한다.
- HAVING절에 명시된 조건을 만족하는 그룹만 결과에 포함된다.
ex. 프로젝트 인원이 7명 이상인 프로젝트들에 대해서 각 프로젝트에 참여한 임직원 수와 최대 연봉과 최소 연봉과 평균 연봉을 알고 싶다.
1
2
3
4
SELECT W.pro_id, COUNT(*), MAX(salary), MIN(salary), AVG(salary)
FROM works_on W JOIN employee E ON W.empl_id = E.id
GROUP BY W.proj_id
HAVING COUNT(*) >= 7;
SELECT 요약 및 실행 순서
SELECT의 문법과 실행 순서를 살펴보면 다음과 같다.
1
2
3
4
5
6
6. SELECT attribute(s) or aggregate function(s)
1. FROM table(s)
2. [WHERE condition(s)]
3. [GROUP BY group attribute(s)]
4. [HAVING group condition(s)]
5. [ORDER BY attribute(s)];
위의 순서는 select query에서 각 절(phrase)의 실행 순서는 개념적인 순서로 select 쿼리의 실제 실행 순서는 각 RDBMS에서 어떻게 구현했는지에 따라 다르다.