[자연어 처리] 데이터 증강
자연어 처리에서 사용하는 데이터 증강 방법을 정리한 포스트입니다.
[자연어 처리] 데이터 증강
자연어처리(NLP) 모델 학습에서 데이터가 부족하거나 특정 라벨이 불균형할 경우, 데이터 증강(Data Augmentation) 기법을 사용하면 모델 성능을 크게 향상시킬 수 있다.
여기서는 대표적인 증강 방법과 Python 코드, 예시, 장단점까지 함께 정리하였다.
EDA
아래 데이터 증강 방법은 EDA: Easy Data Augmentation 논문에서 제시한 방법으로 총 4가지 자연어 처리에서의 데이터 증강 방법을 제시하였다.
- 논문: EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
- 관련 깃허브 : Code
Synonym Replacement(SR)
문장 내 일부 단어를 유의어로 교체하여 한다. 이떄, 불용어가 아닌 n개의 단어를 고르고, 임의로 선택한 유의어와 교체한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
def synonym_replacement(words, n):
new_words = words.copy()
random_word_list = list(set([word for word in words]))
random.shuffle(random_word_list)
num_replaced = 0
for random_word in random_word_list:
synonyms = get_synonyms(random_word)
if len(synonyms) >= 1:
synonym = random.choice(list(synonyms))
new_words = [synonym if word == random_word else word for word in new_words]
num_replaced += 1
if num_replaced >= n:
break
if len(new_words) != 0:
sentence = ' '.join(new_words)
new_words = sentence.split(" ")
else:
new_words = ""
return new_words
def get_synonyms(word):
synomyms = []
try:
for syn in wordnet[word]:
for s in syn:
synomyms.append(s)
except:
pass
return synomyms
- 장점 : 모델이 다양한 표현에서 의미 학습 가능
- 단점 : 문맥과 맞지 않는 단어로 교체되지 않도록 사전 관리 필요
Random Insertion(RI)
문장의 일부 단어의 유의어를 삽입한다. 불용어가 아닌 단어들 중 랜덤하게 단어를 고르고, 유의어를 문장 내 임의의 위치에 삽입한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
def random_insertion(words, n):
new_words = words.copy()
for _ in range(n):
add_word(new_words)
return new_words
def add_word(new_words):
synonyms = []
counter = 0
while len(synonyms) < 1:
if len(new_words) >= 1:
random_word = new_words[random.randint(0, len(new_words)-1)]
synonyms = get_synonyms(random_word)
counter += 1
else:
random_word = ""
if counter >= 10:
return
random_synonym = synonyms[0]
random_idx = random.randint(0, len(new_words)-1)
new_words.insert(random_idx, random_synonym)
- 장점 : 문장 길이 다양화, 모델이 문장 구조에 덜 민감하게 학습
- 단점 : 삽입 단어가 너무 많으면 문장 의미 왜곡 가능
Random Swap(RS)
무작위로 문장 내 두 단어의 순서를 변경한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def random_swap(words, n):
new_words = words.copy()
for _ in range(n):
new_words = swap_word(new_words)
return new_words
def swap_word(new_words):
random_idx_1 = random.randint(0, len(new_words)-1)
random_idx_2 = random_idx_1
counter = 0
while random_idx_2 == random_idx_1:
random_idx_2 = random.randint(0, len(new_words)-1)
counter += 1
if counter > 3:
return new_words
new_words[random_idx_1], new_words[random_idx_2] = new_words[random_idx_2], new_words[random_idx_1]
return new_words
- 장점: 단어 순서 의존도 낮춤, 문장 구조 다양화
- 단점: 문맥 파악이 중요한 태스크에서는 문장 의미 왜곡 가능
Random Deletion(RD)
문장 내 단어를 확률적으로 삭제한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def random_deletion(words, p):
if len(words) == 1:
return words
new_words = []
for word in words:
r = random.uniform(0, 1)
if r > p:
new_words.append(word)
if len(new_words) == 0:
rand_int = random.randint(0, len(words)-1)
return [words[rand_int]]
return new_words
- 장점 : 핵심 단어 중심 학습, 과적합 방지
- 단점 : 너무 높은 확률로 삭제하면 의미 손실 발생
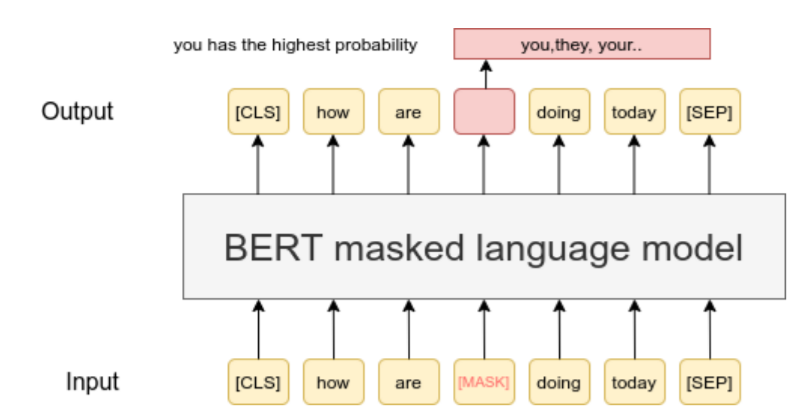
Masked Language models(MLM)
Pre-trained 된 BERT, RoBERTa 와 같은 모델을 활용하여 특정 단어를 [MASK] 처리한 후, [MASK] 된 단어를 예측해 데이터를 증강하는 방식이다.
MLM은 Transformer 모델을 비롯한 다양한 자연어 처리 모델에서 사용되며, 이를 통해 모델이 문장 내의 단어들을 이해하고, 문맥을 파악하는 능력을 향상시킬 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
from transformers import AutoTokenizer, AutoModelForMaskedLM
import torch
import random
tokenizer = AUtoTokenizer.from_pretrained("bert-base-multilingual-cased")
model = AutoModelForMaskedLM.from_pretrained("bert-base-multilingual-cased")
model.eval()
def mask_augment(sentence, mask_prob=0.15, top_k=5):
tokens = tokenizer.tokenize(sentence)
n_mask = max(1, int(len(tokens) * mask_prob))
mask_indices = random.sample(range(len(tokens)), n_mask)
for idx in mask_indices:
tokens[idx] = tokenizer.mask_token # [MASK] 적용
input_ids = tokenizer.encode(tokens, return_tensors="pt")
with torch.no_grad():
outputs = model(input_ids)
predictions = outputs.logits
# 마스크된 위치 예측
for idx in mask_indices:
probs = torch.softmax(predictions[0, idx], dim=0)
top_tokens = torch.topk(probs, top_k).indices.tolist()
predicted_token = tokenizer.convert_ids_to_tokens(random.choice(top_tokens))
tokens[idx] = predicted_token
return tokenizer.convert_tokens_to_string(tokens)
sentence = "오늘 날씨가 정말 좋다"
augmented_sentence = mask_augment(sentence, mask_prob=0.2)
print(augmented_sentence)
학습 과정
- 전체 문장에서 일부 단어를 랜덤하게 선택하여 마스킹
- 마스킹된 단어를 제외한 나머지 단어들을 모델의 입력으로 주고, 모델은 마스킹된 단어를 예측
- 모델은 예측한 단어와 실제 마스킹된 단어를 비교하여 오차를 계산하고, 이를 역전파하여 모델을 학습
- 학습이 완료된 모델은 마스킹된 단어를 포함한 전체 문장을 입력받아, 마스킹된 단어를 예측하고, 문장을 생성하는데 사용될 수 있음.
This post is licensed under CC BY 4.0 by the author.