[BoostCamp AI Tech / AI Math] 확률적 경사하강법
확률적 경사하강법의 원리와 경사하강법과의 차이 그리고 확률적 경사하강법 학습시 주의사항에 대한 정리 포스트입니다.
확률적 경사하강법(stochastic gradient descent)은 모든 데이터를 사용해서 업데이터하는 대신 데이터 한개 또는 일부를 활용하여 업데이트한다.
경사하강법 : 데이터 전체로 그레디언트 계산
\[\theta^{(t+1)} \gets \theta^{(t)} - \nabla_{\theta} L(\mathcal{D} - \theta^{(t)})\]확률적 경사하강법 : 데이터 일부로 그레디언트 계산
\[\theta^{(t+1)} \gets \theta^{(t)} - \nabla_{\theta} L(\mathcal{D}_{(b)} - \theta^{(t)})\]
볼록이 아닌(non-convex) 목적식은 SGD를 통해 최적화할 수 있다. 다만, SGD가 만능인 것은 아니며 경사하강법에 비해 실증적으로 더 낫다고 검증되었기 때문에 사용한다.
\[\beta^{(t+1)} \gets \beta^{(t)} + \frac{2\lambda}{b} \mathbf{X}_{(b)}^T(\mathbf{y_{(b)}} - \mathbf{X_{(b)}}\beta^{(t)})\]전체 데이터 $(\mathbf{X}, \mathbf{y})$ 를 쓰지 않고 미니배치 $(\mathbf{X} _{(b)}, \mathbf{y} _{(b)})$ 를 써서 업데이트 하므로 연산량이 $b/n$로 감소한다.
이러한 방식은 연산자원을 좀 더 효율적으로 활용하는데 도움이 된다.
확률적 경사하강법의 원리
경사하강법은 전체데이터 $\mathcal{D} = (\mathbf{X}, \mathbf{y})$ 를 가지고 목적식의 그레디언트 벡터인 $\nabla_{\theta} L(\mathcal{D}, \theta)$ 를 계산한다.
반면에, SGD는 미니배치 $\mathcal{D} _{(b)} = (\mathbf{X} _{(b)}, \mathbf{y} _{(b)}) \subset \mathcal{D}$ 를 가지고 그레디언트 벡터를 계산한다.
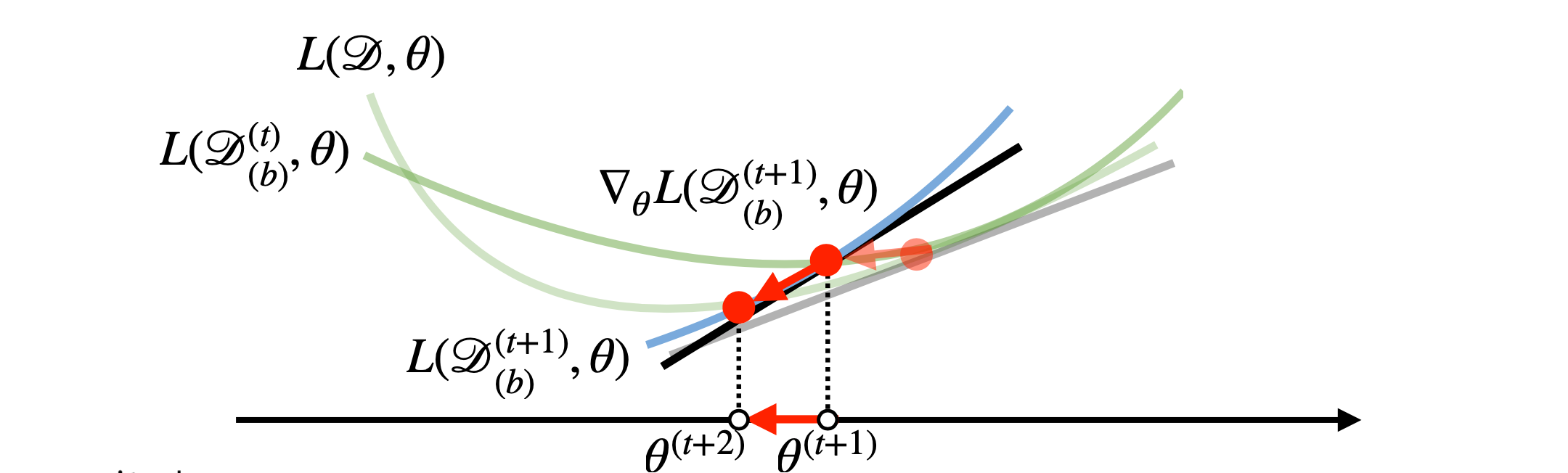
미니배치는 매변 확률적으로 선택하고, 따라서 목적식 모양도 계속 바뀐다. 이러한 이유로 경사하강법의 문제점이었던 극값에 도달했을 때, 학습이 멈추었던 현상을 확률적으로 피할 수 있다.
즉, SGD는 매번 다른 미니배치를 확률적으로 사용하기 때문에 곡선 모양이 바뀌게 되고 이 곡선에서 그레디언트를 계산한다.
SGD는 볼록이 아닌 목적식에서도 사용 가능하므로 경사하강법보다 기계학습 모델 최적화에 더 효율적이다.
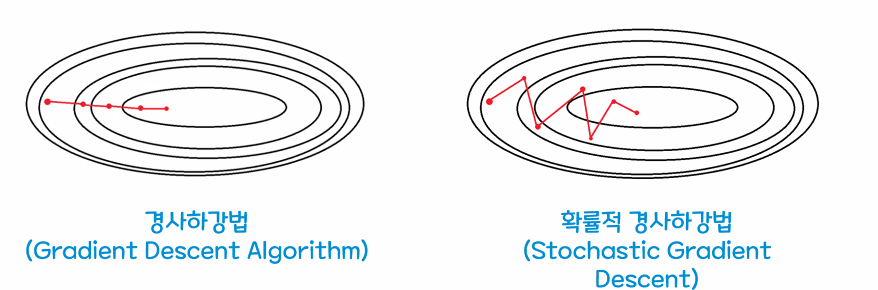
극솟값에 빠지는 지점에서 탈출하는 동시에 최적값을 향하는 지점을 찾을 수 있어 비볼록함수에서 사용하기에 적합하다.
이때, 미니배치 사이즈를 적절하게 설정해 하드웨어를 효율적으로 사용하고 빠르게 수렴할 수 있다.
확률적 경사하강법의 장점
SGD가 하드웨어 측면에서 일부 데이터만 사용하기 때문에 모든 데이터를 사용하는 경사하강법에서 발생할 수 있는 out-of-memory가 발생하지 않는다.
SGD 기반 선형회귀 알고리즘
경사하강법에 없는 미니배치의 사이즈를 결정하는 batch_size와 데이터를 랜덤하게 섞는 shuffler가 필요하다.
1
2
3
4
5
6
7
8
9
10
11
sgd_error_list = []
beta_hat = np.random.normal(size=(4, ))
for t in range(T):
data_size = len(y)
sampler = shuffler(X, y, data_size, batch_size)
for (X_batch, y_batch) in sampler:
error = y_batch - X_batch @ beta_hat
grad = - X_batch.transpose() @ error
beta_hat = beta_hat - lr * grad / batch_size
sgd_error_list.append(np.mean(error**2))
SGD 학습시 유의사항
SGD 알고리즘은 학습률을 고정시키면 안되고 스케줄러를 쓰는 것이 좋다. 이때 스케줄러는 Robbins-Monro 조건을 만족해야한다.
\[\lambda_t \propto t^{-1} \Longrightarrow \sum_{t} \lambda_t = \infty \ \ \ \ \sum_{t} \lambda_t^2 < \infty\]이 조건은 step의 역수에 해당하는 것 만큼 학습률을 설정하면 위의 식의 조건을 만족한다.
이를 코드에 적용하면 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
def lr(t, init=1.0):
return init / (t + 1)
sgd_error_list = []
beta_hat = np.random.normal(size=(4, ))
for t in range(T):
data_size = len(y)
sampler = shuffler(X, y, data_size, batch_size)
for (X_batch, y_batch) in sampler:
error = y_batch - X_batch @ beta_hat
grad = - X_batch.transpose() @ error
beta_hat = beta_hat - lr(t) * grad / batch_size
sgd_error_list.append(np.mean(error**2))
이 글은 비밀번호로 보호되어 있습니다.