[BoostCamp AI Tech / Product Serving] 클라우드 서비스
Cloud 서비스에 대한 공통 개념을 학습하며 Google Cloud Platform을 통해서 간단한 인프라를 구현하는 방법을 정리한 포스트입니다.
Cloud 서비스를 만드는 경우 자신의 컴퓨터(localhost)로 서비스를 만들거나 IP로 누구나 접근할 수 있게 수정하고, IP를 공유하는 방법이 있다.
만약 자신의 컴퓨로 서비스를 만든 경우 본인 컴퓨터가 종료되면 웹, 앱 서비스도 종료된다.
이러한 문제를 해결하기 위한 전통적인 접근 방법은 물리적 공간, 확장성을 고려한 서버실을 만들고 운영한다. 이를 IDC(Internet Data Center)라고 부른다.
이러한 방법을 위해서는 서버 컴퓨터를 넣을 공간 + 추후 서버를 추가할 때 확장할 수 있는지 그리고 전기, 에어컨 등 서버가 급작스럽게 종료되지 않도록 준비를 해야한다.
만약, 갑자기 트래픽이 몰릴 경우, 컴퓨터 10대를 설치하기 어려울 수 있으며(자재 수급 이슈 등) 반대로 트래픽이 적어서 컴퓨터 10대를 없애기가 쉽지 않다.
이러한 문제로 좀 더 자유로워 지기 위해서 도입된 개념이 바로 Cloud 서비스다. 여기서 더 발전하여 개발자가 직접 설정해야 했던 작업 등을 클라우드에서 쉽게 할 수 있는 방향으로 발전(Managed 서비스)하였다.

플랫폼 별 유사한 제품이지만 명칭과 세부 옵션 다른 경우가 있지만 기본적인 공통 개념을 동일하다.
Cloud 서비스 개념
대표적으로 사용하는 Cloud 개념으로 7가지가 있다.
- Computing Service (Server)
- Serverless Computing
- Stateless Container
- Object Storage
- Database (DB)
- Data Warehouse
- AI Platform
Computing Service (Server)
- 가장 많이 사용할 제품
- 연산을 수행하는(Computing) 서비스
- 가상 컴퓨터, 서버로 CPU나 Memory, GPU 등을 선택할 수 있음
- 인스턴스 생성 후, 인스턴스에 들어가서 사용 가능
- 대부분 리눅스 사용
- 클라우드마다 무료 사용량이 존재(성능은 약 cpu 1 core, memory 2G)
- AWS(EC2), Google Cloud(Compute Engine)
Serverless Computing
- 앞서 다룬 Computing Service와 유사하지만, 서버 관리를 클라우드쪽에서 진행
- 코드를 클라우드에 제출하면, 그 코드를 가지고 서버를 실행해주는 형태
- 요청 부하에 따라 자동으로 확장(Auto Scaling)
- Micro Service로 많이 활용
- AWS(Lambda), Google Cloud(Cloud Function)
Stateless Container
- Stateless : 컨테이너 외부(DB, Cloud Storage 등)에 데이터를 저장. 컨테이너는 그 데이터로 동작
- 컨테이너가 중지되거나 삭제될 때, 컨테이너 내에서 생성된 모든 데이터나 상태가 삭제
- Docker를 사용한 Container 기반으로 서버를 실행하는 구조
- Docker Image를 업로드하면 해당 이미지 기반으로 서버를 실행해주는 형태
- 요청 부하에 따라 자동으로 확장(Auto Scaling)
- AWS(ECS), Google Cloud(Cloud Run)
Object Storage
- 다양한 형태의 데이터를 저장할 수 있으며, API를 사용해 데이터에 접근할 수 있음
- 점점 데이터 저장 비용이 저렴해지고 있음
- 다양한 Object를 저장할 수 있는 저장소
- 머신러닝 모델 pkl 파일, csv 파일, 실험 log 등을 Object Storage에 저장할 수 있음
- AWS(S3), Google Cloud(Cloud Storage)
Database (DB)
- Database가 필요한 경우 클라우드에서 제공하는 Database를 활용할 수 있음
- 웹, 앱서비스와 데이터베이스가 연결되어 있는 경우가 많으며, 대표적으로 MySQL, PostgreSQL 등을 사용할 수 있음
- 사용자 로그 데이터를 Database에 저장할 수도 있고, Object Storage에 저장할 수도 있음
- 저장된 데이터를 어떻게 사용하냐에 따라 어디에 저장할지를 결정
- AWS(RDS), Google Cloud(Cloud SQL)
Data Warehouse
- 보통 Database = 서비스에서 사용하기 위한 데이터를 저장
- 분석 목적의 Database가 아님
- Data Warehouse
- 데이터 분석에 특화된 Database
- Database에 있는 데이터, Object Storage 에 있는 데이터 등을 모두 Data Warehouse에 저장
- AWS(Redshift), Google Cloud(BigQuery)
AI Platform
- AI Research, AI Develop 과정을 더 편리하게 해주는 제품
- MLOps 관련 서비스 제공
- Google Cloud에서 TPU 사용 가능
- AWS(SageMaker), Google Cloud(Vertex AI)
Cloud Network
네트워크 지식을 알고 있으면 특정 클라우드 벤터(AWS, GCP)에 종속되지 않고, 인프라 환경을 이해할 수 있다. 또한, 보다 안전한 클라우드 인프라 구성이 가능하다.
Virtual Private Cloud (VPC)

- 보안상의 이유로 네트워크 분리
- 실제로 같은 네트워크 안에 있지만 논리적으로 분리한 것
- Cloud Computing Service(예 : Compute Engine) 사이의 연결 복잡도 줄여줌
- 여러 서버를 하나의 네트워크에 있도록 묶는 개념
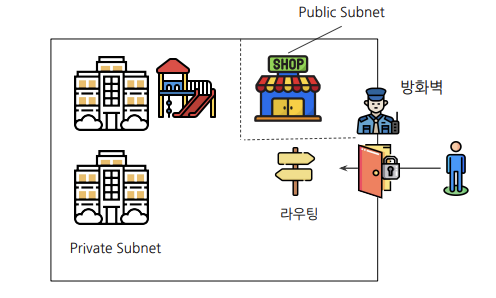
VPC에서 서브넷(subnet)라는 개념이 있으며 VPC 안에서 여러 망을 쪼개는 것을 말한다.
- Public Subnet : 외부에서 접근 가능한 망
- Private Subnet : 외부에서 접근이 불가능한 망(ex. Admin)
- 같은 VPC 내에 있으면 Private ID로 접근이 가능함
서브넷말고 라우팅(Routing) 이라는 개념이 있다.
- 경로를 설정하고 찾아가는 길
- 경로 지정
- 어디로 가고 싶은가요? 물어볼 때 길을 안내해주는 개념
GCP (Google Cloud Platform)
회원 가입 후 구글 클라우드 플랫폼 메인 대시보드로 이동
프로젝트 정보 → project_name, project_id를 자주 사용
- Compute Engine
- Compute Engine 클릭
- 서버=인스턴스=VM(Virtual Machine)=GCP Compute Engine, AWS EC2
- [VM 인스턴스] 클릭 - [인스턴스 만들기] 클릭 하면 서버 생성
- 이름, 컴퓨터 성능, Region 지정
- 머신 유형을 e2-micro로 지정
- 우측의 SSH 클릭 후 브라우저 창에서 열기 - CLI 화면이 보임
사용하지 않는 경우엔 중지 또는 삭제! !!!중지되는 경우에도 비용이 부과되는 경우가 존재할 수 있음!!!
- Compute Engine 클릭
- Cloud Storage
- Object Storage인 Cloud Storage, [버킷 만들기] 클릭
- 버킷 이름 지정하여 버킷 생성
- 버킷 클릭 시 파일 업로드, 폴더 업로드 가능
만약에 Python으로 Bucket 내 파일 다운로드 및 업로드를 하고 싶으면 어떤 과정을 거쳐야 할까?
- Google Could 파이썬 라이브러리를 설치 -
pip install google-cloud-storage - 서비스 계정(Service Account)과 키를 생성
- Cloud Console에서의 서비스 계정 만들기 페이지에서 대상 프로젝트를 선택 후
- [서비스 계정]-[서비스 계정 세부정보]에서 [역할]을 소유자로 설정
- 생성된 서비스 계정을 클릭 후 [키 추가]를 통해 json 유형의 키를 다운로드
- json 파일을 활용하여 로컬에 환경 변수를 설정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from google.cloud import storage
# Init
bucket_name = "awesome-gcp"
storage_client = sotrage.Client()
bucket = storage_client.bucket(bucket_name)
# Upload
upload_path = ''
upload_file_name = ''
blob = bucket.blob(upload_path)
blob.upload_from_filename(upload_file_name)
# Download
download_file_name = ''
destination_path = ''
blob = bucket_path = ''
blob.download_to_filename(destiation_path)
Bucket: 저장소(하드 드라이브)Blob: Binary Large Object. 저장 객체
이 글은 비밀번호로 보호되어 있습니다.