[BoostCamp AI Tech / NLP 이론] Self-supervised Pre-training Model: BERT
Transformer 기반의 자연어 처리 성능을 혁신한 모델 BERT에 대한 내용을 정리한 포스트입니다.
Self-Supervised Learning
Self-Supervised Learning(자기 지도 학습) 이란 데이터의 일부를 숨기고, 해당 부분을 예측하도록 학습하는 Pre-training(사전 학습) 중 하나이다.
- Image inpainting
- ex. 얼굴이미지를 통해 성별 분류
- 수집된 얼굴이미지에 성별 정보를 레이블을 만들어야하는 번거로움이 있으며 레이블이 있는 대뮤모 데이터를 구하기 어렵움
- 원본 이미지에서 랜덤하게 일부 정보(픽셀)를 없앤 이미지를 모델 입력으로 사용하여 모델이 훼손된 이미지를 복원하는 방식으로 학습을 진행
- 퍼즐 풀기
- 입력 이미지에서 이미지 패치들을 무작위로 다른 위치에 놓은 새로운 이미지를 모델의 입력으로 사용하고 모델은 각 패치들이 어디에 위치해야하는지를 학습한다.
Self-supervised learning을 통해 학습된 모델은 주어진 입력 데이터에 대한 유의미한 여러 지식을 배우며 이러한 학습에 사용된 여러 layer들은 주어진 입력 데이터로 부터 다양한 feature를 추출하도록 학습된다.
Pre-training: 모델에게 기초 지식을 먼저 가르치도록 하는 모델을 학습하는 하나의 이론으로 이를 수행하는 방법으로 두 가지가 있다.
- 지도학습 기반 사전학습 (Supervised Pre-training): 사람이 정답(Label)을 달아놓은 데이터를 사용
- 자기지도학습 기반 사전학습 (Self-supervised Pre-training): 정답이 없는 데이터를 사용해 데이터 스스로 정답을 만들게 한다.
Transfer Learning
self-supervised learning 기법을 통해 학습된 모델을 가지고 목표 task(target task, downstream task, fine-tuning task)에 활용하여 해당 task의 성능을 높이는데 사용하는 방법을 Transfer learning(전이 학습) 이라고 한다.
사전 학습된 모델의 앞쪽 layer를 가지고 입력 데이터로부터 추출된 피처들을 입력으로 받아 목표 task를 수행하는 새로운 layer들을 덛붙이는 방식으로 전체 Neural Network를 구성할 수 있다.
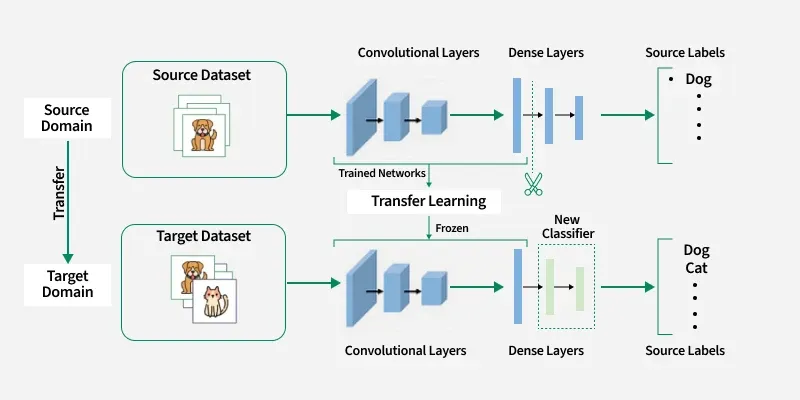
- 사전 학습 모델의 layer들은 목표 task를 위한 데이터를 통해서 학습을 진행할 수도 있고 학습을 하지 않고 그대로 사용할 수 있다.
- 만약 학습을 진행한다면 새로 붙인 layer에 사용하는 learning rate보다 작은 값으로 설정함으로써 fine-tuning(미세조정) 을 하는 식으로 모델 학습을 진행할 수 있다.
BERT
Self-Supervised learning을 활용하기 위해서는 필수적으로 대규모의 labling 되지 않은 데이터가 필요하다.
자연어 처리같은 경우는 인터넷에서 수집할 수 있는 다양한 글들이 활용된다.
이러한 방법을 통해 학습된 대표적은 모델로 BERT(Bidirectional Encoder Representations from Transformers) 가 있다.

- 모델 구조: 대형 Transformer encoder
- 사전 학습 태스크:
Masked language modeling(MLM)Next-sentence prediction (NSP)- 대향의 Unlabeled 데이터로 학습을 진행
- 사전 학습된 BERT를 다양한 Task에 적용
- 단일 문장 분류, 문장 쌍 분류
- 질의 응답(Question & Answering)
- 문장 내 토큰 분류
Masked language modeling(MLM)
제공된 문장에서 mask된 단어를 예측하기 위해서 앞 뒤에 mask되지 않는 단어를 모두 제공하여 주어진 단어를 예측하는 방식이다.
- 무작위로 입력 Token 중
15%의 Token을 마스킹하고 이를 예측- 15%의 Token 중
80%의 Token은[MASK]Token 으로 대체 - 15%의 Token 중
10%의 Token은 다른 무작위 Token으로 대체- Transfer learning할 Task에는 [MASK] Token이 없기 때문
- 15%의 Token 중
10%의 Token은 원래의 Token을 그대로 사용- 항상 무작위의 Token으로 바꿔서 학습 시키면, 의도치 않은 편향이 생길 수 있기 때문
- 15%의 Token 중
이러한 task를 학습하면 주어진 언어에 대한 문법적인 지식과 단어와 문장들이 나타내는 의미를 잘 배울 수 있다.
Next-sentence prediction(NSP)
이 글은 비밀번호로 보호되어 있습니다.