[파이썬 알고리즘 인터뷰] 비선형 자료구조(1)
그래프 / 최단 경로 문제
그래프
수학에서, 좀 더 구체적으로 그래프 이론에서 그래프란 객체의 일부 쌍(pair)들이 ‘연관되어’ 있는 객체 집합 구조를 말한다.
300여 년 전 도시의 시민 한 명이 “이 7개 다리를 한 번씩만 건너서 모두 지나갈 수 있을까?”라는 흥미로운 문제를 냈으며 이를 오일러가 해법을 발견하는 것이 그래프 이론의 시작이다.
오일러 경로
아래 그림에서 A부터 D까지를 정점(Vertex), a부터 g까지는 간선(Edge)으로 구성된 그래프라는 수학적 구조이다. 오일러는 모든 정점이 짝수 개의 차수(Degree)를 갖는다면 모든 다리를 한 번씩 건너서 도달할 수 있으며 이를 오일러의 정리라 부른다.

이처럼 모든 간선을 한 번씩 방문하는 유한 그래프를 오일러 경로 또는 한붓 그리기라고도 말한다.
해밀턴 경로
해밀턴 경로는 각 정점을 한 번씩 방문하는 무항 또는 유향 그래프 경로를 말한다.
오일러는 간선을 기준으로 하지만 해밀턴 경로는 모든 정점을 한 번씩 방문하는 그래프를 말한다. 이러한 단순한 차이에도 불구하고 해밀턴 경로를 찾는 문제는 최적 알고리즘이 없는 대표적인 NP-완전 문제이다. 이 중 해밀턴 순환은 원래의 출발점으로 돌아오는 경로를 말하며 유명한 문제로는 최단 거리를 찾는 문제인 외판원 문제(TSP)가 있다.
그래프 정의

- vertex: 정점
- 여러 가지 특성을 가질 수 있는 객체를 의미함. 노드(node)라고도 함.
- edge (간선)
- 정점들 간의 관계를 의미. link라고도 함.
그래프 종류
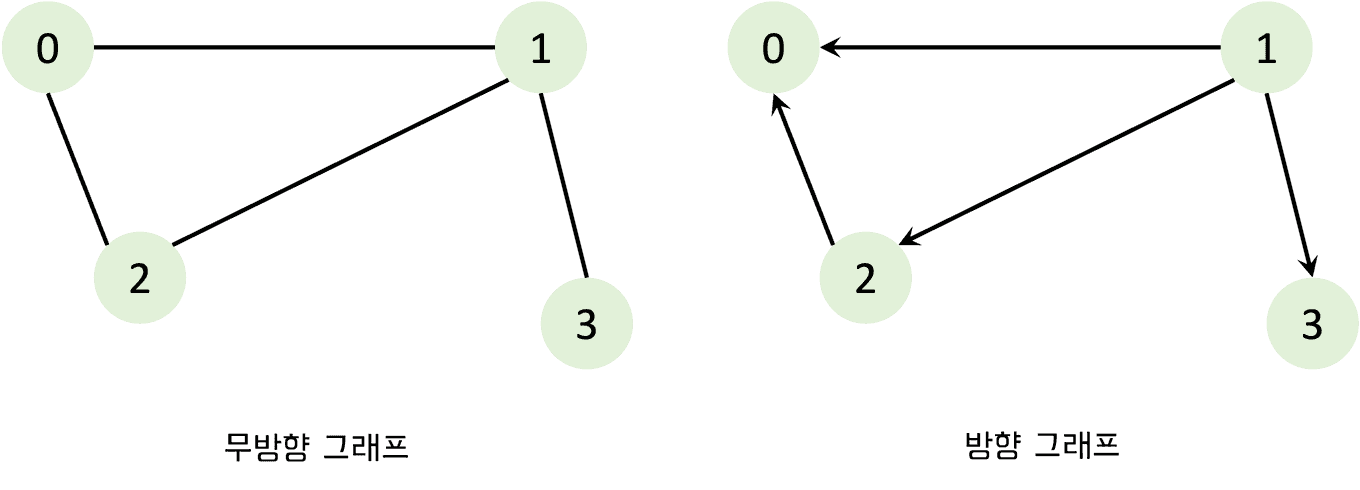
무향 그래프 vs 방향 그래프
- 무향 그래프 (undirected graph)
- 무향 에지는 양방향의 의미임. 예컨대 조합(combination)처럼 (A,B) = (B,A)로 순서에 의미가 없다는 것.
- 방향 그래프 (directed graph)
- : 에지를 통해서 한쪽 방향으로만 갈 수 있다는 특징. 즉,
≠ <B,A> 라는 특성을 보임.
- : 에지를 통해서 한쪽 방향으로만 갈 수 있다는 특징. 즉,
cf.) 가중치 그래프: 각 간선에 가중치를 부여한 형태의 그래프. 예를 들면 edge에 비용을 부과하는 형식으로 가중치가 부과될 수 있음.
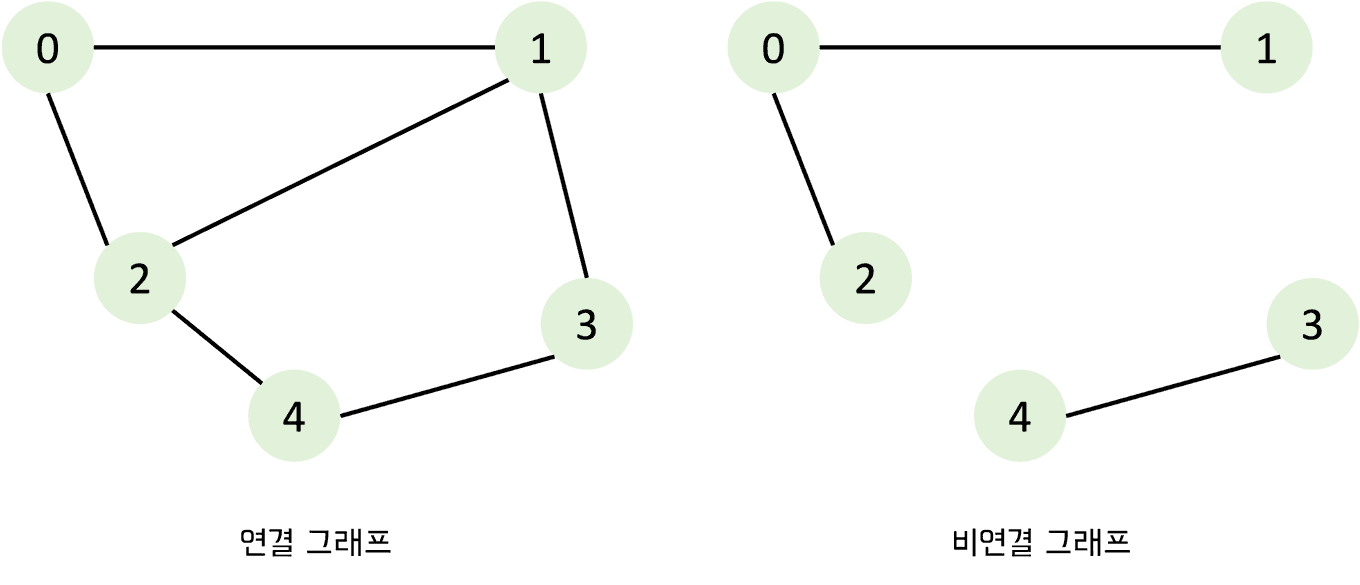
연결 그래프 vs 비연결 그래프
- 연결 그래프 (Connected Graph)
- 무방향 그래프에 있는 모든 노드에 대해 항상 경로가 존재하는 경우
- 비연결 그래프 (Disconnected Graph)
- 무방향 그래프에서 특정 노드에 대해 경로가 존재하지 않는 경우
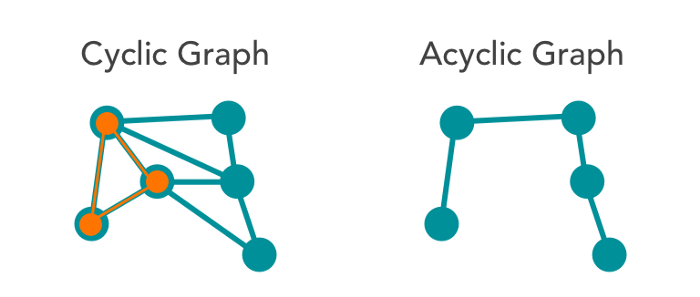
사이클과 비순환 그래프
- 사이클 (Cycle)
- 단순 경로의 시작 노드와 종료 노드가 동일한 경우
- 단순 경로 (Simple Path): 처음 정점과 끝 정점을 제외하고 중복된 정점이 없는 경로
- 비순환 그래프 (Acyclic Graph)
- 사이클이 없는 그래프
완전 그래프
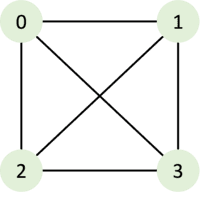
완전 그래프(Complete Graph)는 그래프의 모든 노드가 서로 연결되어 있는 그래프
그래프 순회
그래프 순회란 그래프 탐색이라고도 불리우며 그래프의 각 정점을 방문하는 과정을 말한다.
그래프의 각 정점을 방문하는 그래프 순회에는 크게 깊이 우선 탐색(DFS)과 너비 우선 탐색(BFS)의 2가지 알고리즘이 있다. 일반적으로 DFS가 BFS에 비해 더 널리 쓰인다.
DFS는 주로 스택으로 구현하거나 재귀로 구현하며, 이후에 살펴볼 백트래킹을 통해 뛰어난 효용을 보인다. 반면, BFS는 주로 큐로 구현하며, 그래프의 최단 경로를 구하는 문제 등에 사용된다.
그래프를 표현하는 방법에는 크게 인접 행렬(Adjacency Matrix)과 인접 리스트(Adjacency List)의 2가지 방법이 있다.
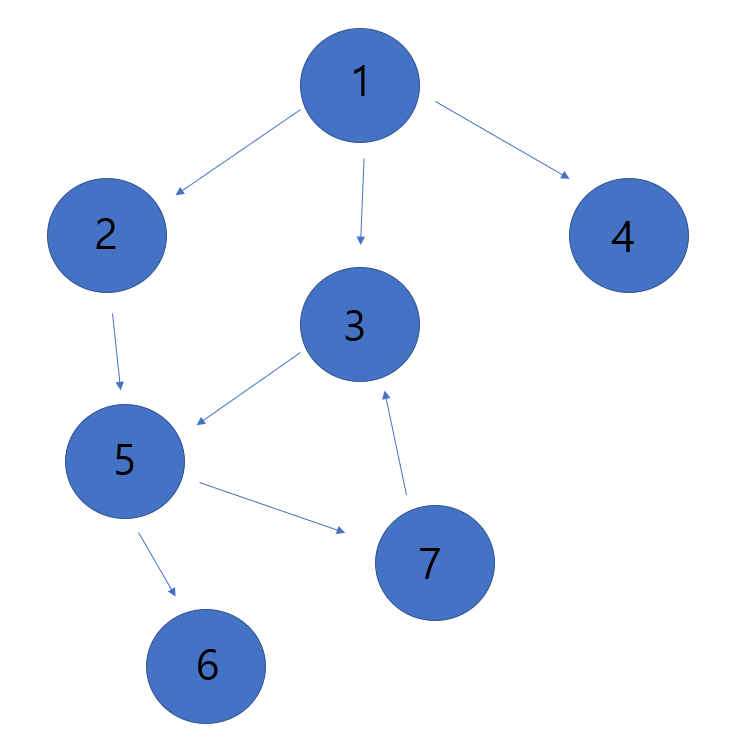
- 인접 리스트: 출발 노드를 키로, 도착 노드를 값으로 표현한다. 파이썬에서는 딕셔너리 자료형으로 나타낼 수 있으며 도착 노드는 여러 개가 될 수 있으므로 리스트 형태가 된다.
1
2
3
4
5
6
7
8
9
10
# 그래프를 인접 리스트로 표현
graph = {
1: [2, 3, 4],
2: [5],
3: [5],
4: [],
5: [6, 7],
6: [],
7: [3],
}
DFS(깊이 우선 탐색)
DFS는 깊은 부분을 우선적으로 탐색하는 알고리즘이다.
일반적으로 DFS는 스택으로 구현하며, 재귀를 이용하면 좀 더 간단하게 구현할 수 있으며 코딩 테스트 시에도 재귀 구현이 더 선호되는 편이다.
구체적인 동작 과정은 다음과 같다.
- 탐색 시작 노드를 스택에 삽입하고 방문 처리를 한다.
- 스택의 최상단 노드에 방문하지 않은 입접한 노드가 하나라도 있으면 그 노드를 스택에 넣고 방문한다.
- 더 이상 2번의 과정을 수행할 수 없을 때 까지 반복한다.

재귀 구조로 구현
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 파이썬으로 구현
def recursive_dfs(v, discovered=[]):
discovered.append(v)
for w in graph[v]:
if w not in discovered:
discovered = recursive_dfs(w, discovered)
return discovered
print(f'recursive_dfs: {recursive_dfs(1)}')
# 실제 예시
def dfs(graph, v, visited):
# 현재 노드를 방문처리
visited[v] = True
print(v, end=" ")
for i in graph[v]:
if not visited[i]:
dfs(graph, i, visited)
graph = [
[],
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[7],
[2, 6, 8],
[1, 7]
]
visited = [False] * 9
dfs(graph, 1, visited)
# 1 2 7 6 8 3 4 5
그래프 탐색 순서: 1 → 2 → 5 → 6 → 7 → 3 → 4
스택을 이용한 반복 구조로 구현
1
2
3
4
5
6
7
8
9
10
11
12
def iterative_dfs(start_v):
discovered = []
stack = [start_v]
while stack:
v = stack.pop()
if v not in discovered:
discovered.append(v)
for w in graph[v]:
stack.append(w)
return discovered
print(f'iterative dfs: {iterative_dfs(1)}')
그래프 탐색 순서: 1 → 4 → 3 → 5 → 7 → 6 → 2
BFS(너비 우선 탐색)
BFS는 그래프에서 가까운 노드부터 우선적으로 탐색하는 알고리즘이다.
BFS는 큐를 이용하며, 구체적인 동작 구조는 다음과 같다.
- 탐색 시작 노드를 큐에 삽입하고 방문 처리를 한다.
- 큐에서 노드를 꺼낸 뒤에 해당 노드의 인접 노드 중에서 방문하지 않은 노드를 모두 큐에 삽입하고 방문 처리한다.
- 더 이상 2번 과정을 수행할 수 없을 때까지 반복한다.

BFS는 DFS보다 쓰임새는 적지만, 간선의 비용이 동일한 상황에서 최단 경로를 찾는 경우에 사용(간선의 비용이 다른 다익스트라 알고리즘) 되며 재귀 구현은 불가능하다.
큐를 이용한 반복 구조로 구현
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 큐를 이용한 BFS 구현
def iterative_bfs(start_v):
discovered = [start_v]
queue = [start_v]
while queue:
v = queue.pop(0) # 최적화를 위해 deque로 구현해 popleft()를 사용도 가능
for w in graph[v]:
if w not in discovered:
discovered.append(w)
queue.append(w)
return discovered
# 실제 예시
from collections import deque
def bfs(graph, start, visited):
queue = deque([start])
visited[start] = True
while queue:
v = queue.popleft()
print(v, end=" ")
for i in graph[v]:
if not visited[i]:
queue.append(i)
visited[i] = True
graph = [
[],
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[7],
[2, 6, 8],
[1, 7]
]
visited = [False] * 9
bfs(graph, 1, visited)
# 1 2 3 8 7 4 5 6
그래프 탐색 순서: 1 → 2 → 3 → 4 → 5 → 6 → 7
백트래킹
백트래킹(Backtracking)은 해결책에 대한 후보를 구축해 나아가다 가능성이 없다고 판단되는 즉시 후보를 포기(백트랙-Backtrack)해 정답을 찾아가는 범용적인 알고리즘으로 제약 충족 문제에 특히 유용하다.
백트래킹은 DFS(깊이 우선 탐색)과 연관이 높다. 백트래킹은 탐색을 하다가 더 갈 수 없으면 왔던 길을 되돌아가 다른 길을 찾는다는 데서 유래했다. 백트래킹은 DFS와 같은 방식으로 탐색하는 모든 방법을 뜻하며, DFS는 백트래킹의 골격을 이루는 알고리즘이다.
백트래킹은 주로 재귀로 구현하며, 알고리즘마다 DFS 변형이 조금씩 일어나지만 기본적으로 모두 DFS의 범주에 속한다. 백트래킹은 가보고 되돌아오고를 반복하며 브루트 포스와 유사하지만 한번 방문 후 가능성이 없는 경우에는 즉시 후보를 포기한다는 점에서 매번 같은 경로를 방문하는 브루트 포스보다는 훨씬 더 우아한 방식이다.
ex) 부모 노드의 값과 다른 자식 노드를 만족하는 경로 탐색
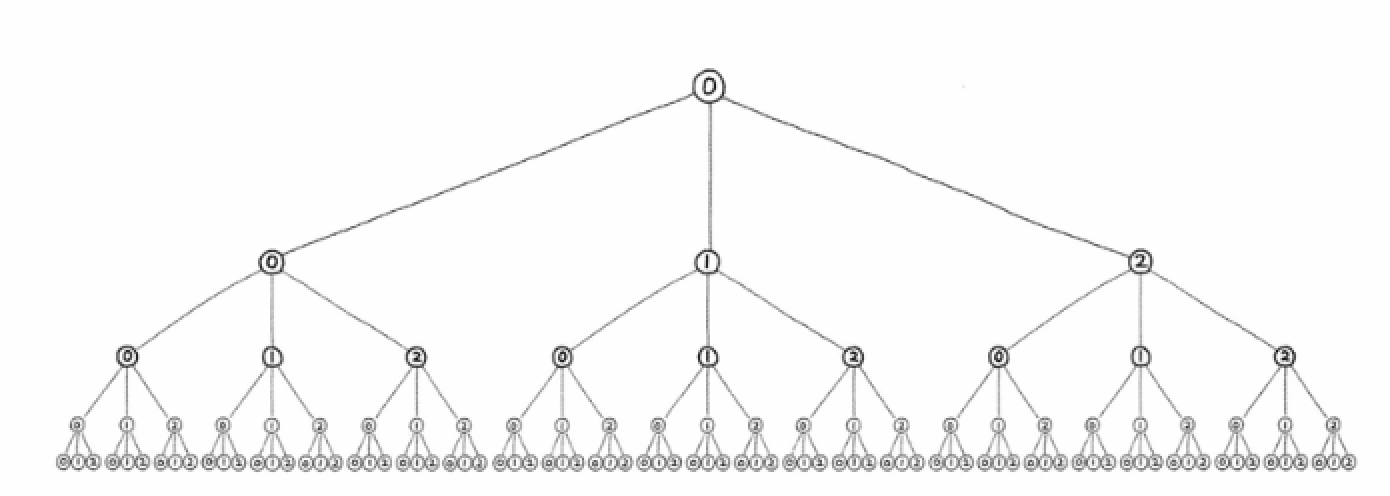 부르트 포스로 전체 탐색을 시도하는 경우
부르트 포스로 전체 탐색을 시도하는 경우
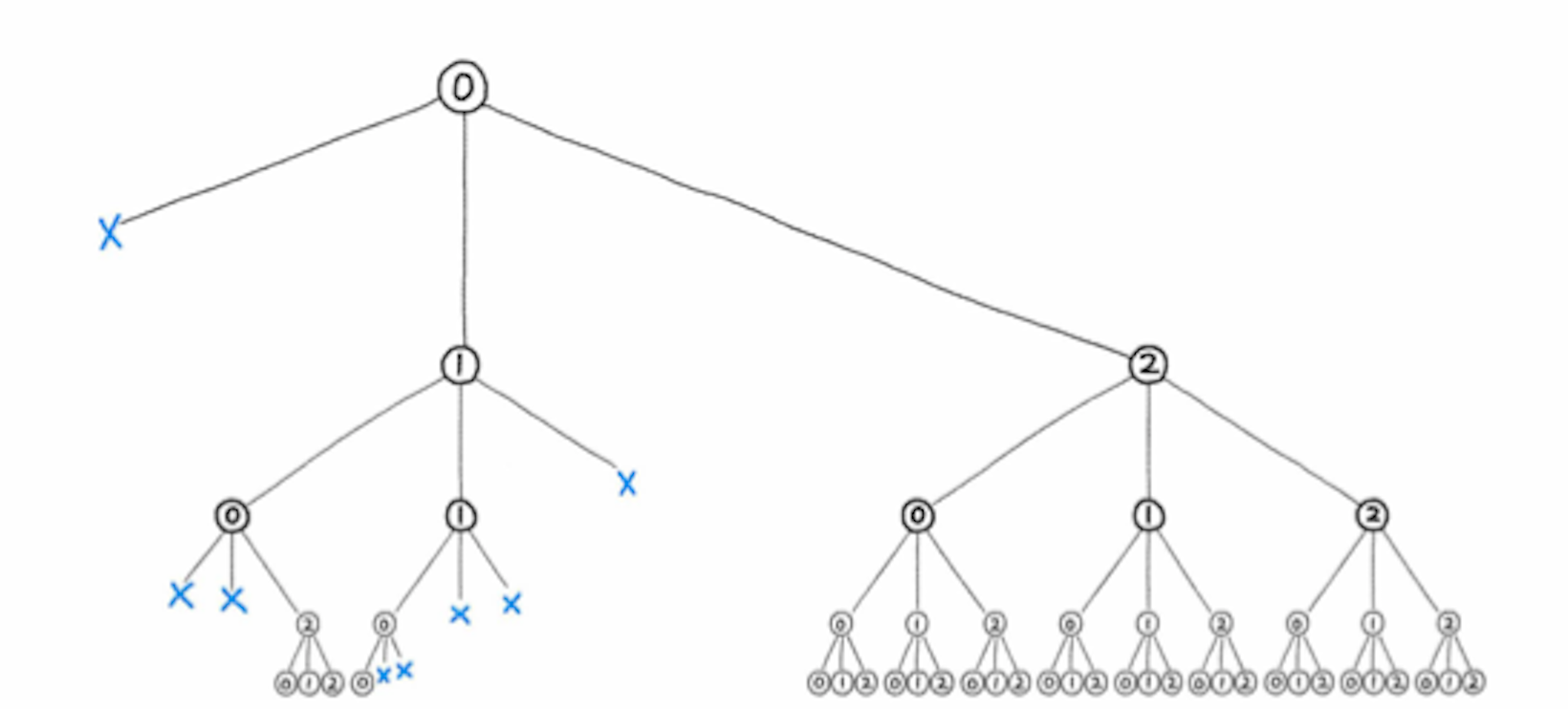 트리를 탐색하여 가능성이 없는 후보를 포기하는 백트래킹
트리를 탐색하여 가능성이 없는 후보를 포기하는 백트래킹
이를 트리의 가지치기(Pruning)라고 하며, 이처럼 불필요한 부분을 일찍 포기한다면 탐색을 최적화할 수 있기 때문에, 가지치기는 트리의 탐색 최적화 문제와도 관련이 깊다.
제약 충족 문제
제약 충족 문제란 수많은 제약 조건을 충족하는 상태를 찾아내는 수학 문제를 일컫는다.
백트래킹은 제약 충족 문제(CSP)를 풀이하는 데 필수적인 알고리즘이며 가지치기를 통해 제약 충족 문제를 최적화 하기 때문이다. 제약 충족 문제는 대표적으로 스도쿠가 있다.
최단 경로 문제
최단 경로 문제는 각 간선의 가중치 합이 최소가 되는 두 정점(또는 노드)사이의 경로를 찾는 문제다.
최단 경로는 지도 상의 한 지점에서 다른 지점으로 갈 때 가장 빠른 길을 찾는 것과 비슷한 문제다.
- 정점(Vertex): 교차로
- 간선(Edge): 길
- 가중치(Weight): 거리나 시간과 같은 이동 비용
그래프의 종류와 특성에 따라 각각 최적화된 다양한 최단 경로 알고리즘이 존재하며 그 중 가장 유명한 것은 다익스트라 알고리즘이다.
- 항상 노드 주변의 최단 경로만을 택하는 대표적인 그리디 알고리즘 중 하나
- 단순하며 실행 속도도 빠름
- 노드 주변을 탐색할 때 BFS를 이용
DFS는 미로를 찾아 헤매는 과정과 비슷한 반면, BFS는 여러 명의 사람이 각기 서로 다른 갈림길로 흩어져서 길을 찾는 것과 비슷하다. 다만 가중치가 음수인 경우는 처리할 수 없다.(벨만-포드 알고리즘은 음수 처리가 가능)
다익스트라의 최초 구현에서는 시간 복잡도가 $O(V^2)$였으나 현재는 너비 우선 탐색(BFS)시 가장 가까운 순서를 찾을 때 우선순위 큐를 적용하여 이 경우 시간 복잡도는 $O((V + E)log V)$, 모든 정점이 출발지에서 도달이 가능하다면 최종적으로 $O(E log V)$가 된다.