[파이토치 트랜스포머를 활용한 자연어 처리와 컴퓨터 비전 심층학습] 파이토치 기초(2)
데이터 세트와 데이터 로더 / 모델 & 데이터세트 분리 / 모델 저장 및 불러오기
데이터세트와 데이터로더
데이터세트: 데이터의 집합을 의미하며, 입력값(X)과 결과값(Y)에 대한 정보를 제공하거나 일련의 데이터 묶음을 제공
- 구조: 일반적으로 데이터베이스(Database)의 테이블(Table)과 같은 형태
- 데이터세트의 한 패턴을 테이블의 행(Row)으로 간주한다면, 이 행에서 데이터를 불러와 학습을 진행
데이터의 구조나 패턴은 매우 다양하며 학습해야 하는 데이터가 파일 경로로 제공되거나 데이터를 활용하기 위해서 전처리 단계가 필요한 경우가 있다. 또한 다양한 데이터가 포함된 데이터세트에서는 특정한 필드의 값을 사용하거나 사용하지 않을 수 있다.
데이터를 변형하고 매핑하는 코드를 학습 과정에 직접 반영하면 모듈화(Modularization), 재사용성(Reusable), 가독성(Readability) 등을 떨어뜨리는 주요 원인이 된다. 이러한 현상을 방지하고 코드를 구조적으로 설계할 수 있도록 데이터세트와 데이터로더를 사용한다.
데이테세트
데이터세트(Dataset)는 학습에 필요한 데이터 샘플을 정제하고 정답을 저장하는 기능을 제공한다.
- 초기화 메서드(
__init__): 입력된 데이터의 전처리 과정을 수행하는 메서드- 새로운 인스턴스가 생성될 때 학습에 사용될 데이터를 선언하고, 학습에 필요한 형태로 변형하는 과정을 진행
- 호출 메서드(
__getitem__): 학습을 진행할 때 사용되는 하나의 행을 불러오는 과정- 입력된 색인(index)에 해당하는 데이터 샘플을 불러오고 반환
- 초기화 메서드에서 변형되거나 개선된 데이터를 가져오며, 데이터 샘플과 정답을 반환
- 길이 반환 메서드(
__len__): 학습에 사용된 전체 데이터세트의 개수를 반환- 메서드를 통해 몇 개의 데이터로 학습이 진행되는지 확인할 수 있음
1
2
3
4
5
6
7
8
9
10
11
12
# 데이터세트 클래스 기본형
class Dataset:
def __init__(self, data, *arg, **kwargs):
self.data = data
def __getitem__(self, index):
return tuple(data[index] for data in data.tensors)
def __len__(self):
return self.data[0].size(0)
모델 학습을 위해 임의의 데이터세트를 구성할 때 파이토치에서 지원하는 데이터세트 클래스를 상속받아 사용한다. 새로 정의한 데이터세트 클래스는 현재 시스템에 적합한 구조로 데이터를 전처리해 사용한다.
데이터로더
데이터로더(DataLoader)는 데이터세트에 저장된 데이터를 어떠한 방식으로 불러와 활용할지 정의한다. 학습을 조금 더 원활하게 진행할 수 있도록 여러 기능을 제공한다.
- 배치 크기(batch_size): 학습에 사용되는 데이터의 개수가 매우 많아 한 번의 에폭에서 모든 데이터를 메모리에 올릴 수 없을 때 데이터를 나누는 역할을 한다.
- 전체 데이터세트에서배치 크기만큼 데이터 샘플을 나누고, 모든 배치를 대상으로 학습을 완료하면 한 번의 에폭이 완료
- 데이터 순서 변경(shuffle): 데이터의 순서로 학습되는 것을 방지
- 데이터 로드 프로세스 수(num_workers): 데이터를 불러올 때 사용할 프로세스의 개수
다중 선형회귀
데이터세트와 데이터로더를 활용해 다중 선형회귀를 구현하면 아래와 같이 구현할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
import torch
from torch import nn
from torch import optim
from torch.utils.data import TensorDataset, DataLoader
# 기본 데이터 구조 선언
train_x = torch.FloatTensor([
[1, 2], [2, 3], [3, 4], [4, 5], [5, 6], [6, 7]
])
train_y = torch.FloatTensor([
[0.1, 1.5], [1, 2.8], [1.9, 4.1], [2.8, 5.4], [3.7, 6.7], [4.6, 8]
])
# 데이터세트와 데이터로더
train_dataset = TensorDataset(train_x, train_y)
train_dataloader = DataLoader(train_dataset, batch_size=2, shuffle=True, drop_last=True)
# 모델, 오차 함수, 최적화 함수 선언
model = nn.Linear(2, 2, bias=True)
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)
# 데이터로더 적용
for epoch in range(20000):
cost = 0.0
for batch in train_dataloader:
x, y = batch
output = model(x)
loss = criterion(output, y)
loss.backward()
optimizer.step()
cost += loss
cost = cost / len(train_dataloader)
if (epoch + 1) % 1000 == 0:
print(f"Epoch: {epoch+1:4d}, Model: {list(model.parameters())}, Cost: {cost:.3f}")
실제 환경에서 적용되는 데이터(학습에 사용하지 않은 데이터)를 통해 지속적으로 검증하고, 최적의 매개변수를 찾는 방법으로 모델을 구성해야 한다. 이 이유로 데이터의 구조나 형태는 지속해서 변경될 수 있으므로 데이터세트와 데이터로더를 활용해 코드 품질을 높이고 반복 및 변경되는 작업에 대해 더 효율적으로 대처해야한다.
모델/데이터세트 분리
모델(Model)은 인공 신경망 모듈을 활용해 구현되며 데이터에 대한 연산을 수행하는 계층을 정의하고, 순방향 연산을 수행한다.
- 클래스 구조를 활용
- 신경망 패키지의 모듈(
Module) 클래스를 활용
새로운 모델 클래스를 생성하려면 모듈 클래스를 상속받아 임의의 서브 클래스를 생성하며 이는 다른 모듈 클래스를 포함할 수 있으며 트리 구조(Tree Structure)로 중첩할 수 있다.
모듈 클래스
- 초기화 메서드(
__init__)와 순방향 메서드(forward)를 재정의하여 활용- 초기화 메서드는 신경망에 사용될 계층을 초기화
- 순방향 메서드에서는 모델이 어떤 구조를 갖게 될지를 정의
- 모델 객체를 호출하는 순간 순방향 메서드가 정의한 순서대로 학습을 진행
1
2
3
4
5
6
7
8
9
10
11
# 모듈 클래스 기본형
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
return x
- 초기화 메서드(
__init__)super함수로 모듈 클래스의 속성을 초기화하며 이를 통해 부모 클래스를 초기화하면 서브 클래스인 모델에서 부모 클래스의 속성을 사용할 수 있음- 모델 초기화 이후, 학습에 사용되는 계층을 초기화 메서드에 선언
- 모델 매개변수:
self.conv1이나self.conv2와 같은 인스턴스
- 순방향 메서드(
forward)- 모델 매개변수를 이용해 신경망 구조를 설계
- 모델이 데이터(
x)를 입력받아 학습을 진행하는 과정을 정의 - 모델의 인스턴스를 호출하는 순간 호출 메서드(
__call__)가 순방향 메서드를 실행
역방향(backward) 연산은 정의하지 않아도 된다. 파이토치의 자동 미분 기능인 Autograd에서 모델의 매개변수를 역으로 전파해 자동으로 기울기 또는 변화도를 계산해 준다.
비선형 회귀
비선형 회귀를 모듈 클래스를 적용해 모델로 구현할 수 있다.
데이터 형태는 다음과 같다.
| x | y |
|---|---|
| -10.0 | 327.79 |
| -9.9 | 321.39 |
| -9.8 | 314.48 |
| -9.7 | 308.51 |
| -9.6 | 302.86 |
| … | … |
x 데이터와 y 데이터는 $y = 3.1x^2 - 1.7x + random(0.01, 0.99)$의 관계를 갖는다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 라이브러리 및 프레임워크 초기화
import torch
import pandas as pd
from torch import nn
from torch import optim
from torch.utils.data import Dataset, DataLoader
# 사용자 정의 데이터 세트
class CustomDataset(Dataset):
def __init__(self, file_path):
df = pd.read_csv(file_path)
self.x = df.iloc[:, 0].values
self.y = df.iloc[:, 1].values
self.length = len(df)
def __getitem__(self, index):
x = torch.FloatTensor([self.x[index] ** 2, self.x[index]])
y = torch.FloatTensor([self.y[index]])
return x, y
def __len__(self):
return self.length
데이터세트 클래스를 상속받아 사용자 정의 데이터세트(CustomDataset)를 정의한다.
- 초기화 메서드(
__init__)에서는 데이터를 불러오며 값을 할당한다.self.x: x 값self.y: y 값self.length: 데이터의 전체 길이
- 호출 메서드(
__getitem__)에서 x 값과 y 값을 반환한다.- 결과값이 이차 방정식($y = W_1x^2 + W_2x + b$) x 값은 [$x^2$, $x$]의 구조로 반환하고 y 값은 [$y$] 구조로 반환한다.
- 반환 메서드(
__len__)로 초기화 메서드에서 선언한self.length를 반환해 현재 데이터의 길이를 제공한다.
사용자 정의 데이터세트 구성을 완료했다면 사용자 정의 모델을 선언한다.
1
2
3
4
5
6
7
8
9
# 사용자 정의 모델
class CustomModel(nn.Module):
def __init__(self):
super().__init__()
self.layer = nn.Linear(2, 1)
def forward(self, x):
x = self.layer(x)
return x
모듈 클래스를 상속받아 사용자 정의 모델을 정의한다.
super함수를 통해 모듈 클래스의 속성을 초기화하고 모델에서 사용할 계층을 정의- 선형 변환 함수(
nn.Linear)의 입력 데이터 차원 크기(in_features)는 이차 다항식이므로 2를 입력하고, 출력 데이터 차원 크기(out_features)는 1을 입력한다.
모델 매개변수 선언을 모두 완료했다면 순방향 메서드에서 학습 과정을 정의한다.
forward에서self.layer변수에 입력 데이터 x를 전달하고 결과값을 반환
사용자 정의 클래스를 모두 선언하면 인스턴스를 생성한다.
1
2
3
# 사용자 정의 데이터세트와 데이터로더
train_dataset = CustomDataset("../datasets/non_linear.csv")
train_dataloader = DataLoader(train_dataset, batch_size=128, shuffle=True, drop_last=True)
train_dataset 변수에 CustomDataset 인스턴스를 생성한 후 train_dataloader 변수에 데이터로더 인스턴스를 생성한다. 배치 크기(batch_size)와 데이터 순서 변경(shuffle)과 마지막 배치 제거(drop_last)를 참 값으로 할당한다.
인스턴스를 생성한 후 모델, 오차 함수, 최적화 함수를 선언하고 GPU 연산을 적용한다.
1
2
3
4
5
# GPU 연산 적용
device = "cuda" if torch.cuda.is_available() else "cpu"
model = CustomModel().to(device)
criterion = nn.MSELoss().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.0001)
model변수에 사용자 정의 모델을 정의하고criterion변수에 평균 제곱 오차를 할당한다.to메서드를 사용하여CustomModel과MSELoss클래스의 학습 장치를 설정한다.optimizer변수에 최적화 함수를 정의
이후 학습을 진행한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 학습 진행
for epoch in range(10000):
cost = 0.0
for x, y in train_dataloader:
x = x.to(device)
y = y.to(device)
output = model(x)
loss = criterion(output, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
cost += loss
cost = cost / len(train_dataloader)
if (epoch + 1) % 1000 == 0:
print(f"Epoch : {epoch + 1: 4d}, Model: {list(model.parameters())}, Cost: {cost:.3f}")
############## 출력결과 ##############
# Epoch: 1000, Model: [
# Parameter containing: tensor([[3.1034, -1.7008]], device='cuda:0', requires_grad=True),
# Parameter containing: tensor([0.2861], device='cuda:0', requires_grad=True)],
# Cost : 0.095
출력결과를 의하면 가중치는 각각 3.1034($W_1$), -1.7008($W_2$)로 계산되며, 편향은 0.4008($b$)의 값을 반환한다.
모델 평가
학습에 사용하지 않는 임의의 데이터를 모델에 입력해 모델을 평가하는 코드는 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
# 모델 평가
with torch.no_grad():
model.eval()
inputs = torch.FloatTensor(
[
[1 ** 2, 1],
[5 ** 2, 5],
[11 ** 2, 11]
]
).to(device)
outputs = model(inputs)
print(outputs)
테스트 데이터세트나 임의의 값으로 모델을 확인하거나 평가할 때는 torch.no_grad 클래스를 활용한다.
no_grad: 기울기 계산을 비활성화하는 클래스로 자동 미분 기능을 사용하지 않도록 설정- 테스트 데이터는 모델에서 요구하는 입력 차원과 동일한 구조를 가져야 한다.
만약 다시 학습을 진행하려면 train 메서드를 호출해서 모드를 변경해야한다.
1
2
3
4
5
6
7
8
9
10
# 모델 저장
torch.save(
model,
"../models/model.pt"
)
torch.save(
model.state_dict(),
"../models/model_state_dict.pt"
)
모델 파일을 저장하면 나중에 다시 활용할 수 있다.
데이터세트 분리
머신러닝에서 사용되는 전체 데이터세트(Original Dataset)는 두 가지 또는 세 가지로 나눌 수 있다.
- 훈련용 데이터(Training Data): 모델을 학습하는 데 사용
- 테스트 데이터(Test Data): 검증용 데이터를 통해 결정된 성능이 가장 우수한 모델을 최종 테스트하기 위한 목적으로 사용
- 검증용 데이터(Validation Data): 학습이 완료된 모델을 검증하기 위한 데이터세트이며 주로 구조가 다른 모델의 성능 비교를 위해 사용
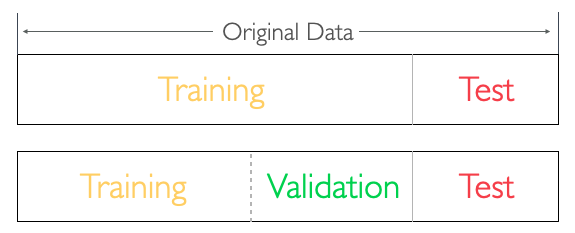
즉, 훈련용 데이터는 모델 학습을 위한 데이터 집합, 검증용 데이터는 모델 선정을 위한 데이터 집합, 테스트 데이터는 최종 모델의 성능을 평가하기 위한 데이터 집합으로 볼 수 있으며 주로 6:2:2 또는 8:1:1의 비율로 설정한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 데이터 분리
import torch
import pandas as pd
from torch import nn
from torch import optim
from torch.utils.data import Dataset, DataLoader, random_split
dataset = CustomDataset("../datasets/non_linear.csv")
dataset_size = len(dataset)
train_size = int(dataset_size * 0.8)
validation_size = int(dataset_size * 0.1)
test_size = dataset_size - train_size - validation_size
train_dataset, validation_dataset, test_dataset = random_split(dataset, [train_size, validation_size, test_size])
train_dataloader = DataLoader(train_dataset, batch_size=16, shuffle=True, drop_last=True)
validation_dataloader = DataLoader(validation_dataset, batch_size=4, shuffle=True, dorp_last=True)
test_dataloader = DataLoader(test_dataset, batch_size=4, shuffle=True, drop_last=True)
# 중략
with torch.no_grad():
model.eval()
for x, y in validation_dataloader:
x = x.to(device)
y = y.to(device)
outputs = model(x)
데이터세트 분리를 위해 torch.utils.data 모듈에서 **무작위 분리(random_split) 함수를 포함시킨다.
1
2
3
4
5
6
# 무작위 분리 함스
subset = torch.utils.data.random_split(
dataset,
lengths,
generator
)
무작위 분리 함수는 분리 길이(lengths)만큼 데이터세트(dataset)의 서브셋(subset)을 생성한다. 생성자(generator)는 서브셋에 포함될 무작위 데이터들의 난수 생성 시드를 의미한다.
1
2
3
4
5
6
7
with torch.no_grad():
model.eval()
for x, y in validation_dataloader:
x = x.to(device)
y = y.to(device)
outputs = model(x)
모델 검증 과정에서는 검증용 데이터(validation_dataloader)**를 활용해 모델 성능을 확인한다. 이후 모델이 결정되면 최종 평가를 위해 테스트 데이터(test_dataloader)로 마지막 성능 검증을 진행한다.
모델 저장 및 불러오기
파이토치의 모델은 직렬화(Serialize)와 역직렬화(Deserialize)를 통해 객체를 저장하고 불러올 수 있다.
모델을 저장하려면 파이썬의 피클(Pickle)을 활용해 파이썬 객체 구조를 바이너리 프로토콜(Binary Protocols)로 직렬화한다. 이때 모델에 사용된 텐서나 매개변수를 저장한다.
모델을 불러오려면 저장된 객체 파일을 역직렬화해 현재 프로세스의 메모리에 업로드하고 이를 통해 계산된 텐서나 매개변수를 불려올 수 있다.
모델 파일 확장자는 주로 .pt나 .pth로 저장된다.
모델 전체 저장/불러오기
모델 전체를 저장하는 경우에는 학습에 사용된 모델 클래스의 구조와 학습 상태 등을 모두 저장한다.
1
2
3
4
5
# 모델 저장 함수
torch.save(
model,
path
)
model: 모델 인스턴스save: 파일이 생성될 경로
모델 전체를 저장하므로 모델 크기에 따라 필요 용량이 달라지며 이를 위해서는 미리 저장 공간을 확보해야 한다.
1
2
3
4
5
# 모델 불러오기 함수
model = torch.load(
path,
map_location
)
path: 모델이 저장된 경로map_location: 모델을 불러올 때 적용하려는 장치 상태를 의미
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 모델 불러오기
import torch
from torch import nn
class CustomModel(nn.Module):
def __init__(self):
super().__init__()
self.layer = nn.Linear(2, 1)
def forward(self, x):
x = self.layer(x)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
model = torch.load("../models/model.pt", map_location=device)
print(model)
####### 출력 결과########
"""
CustomModel(
(layer): Linear(in_features=2, out_features=1, bias=True)
)
"""
with torch.no_grad():
model.eval()
inputs = torch.FloatTensor(
[
[1 ** 2, 1],
[5 ** 2, 5],
[11 ** 2, 11]
]
).to(device)
outputs = model(inputs)
모델을 불러오는 경우에도 동일한 형태의 클래스가 선언돼 있어야 하며 이때 변수의 명칭(layer)까지 동일한 형태로 구현해야 한다.
모델 상태 저장/불러오기
모델 상태만 저장하는 방법 모델의 매개변수만을 저장하여 활용하는 방법으로 모델 전체를 저장하는 것보다 적은 저장 공간을 요구한다.
1
2
3
4
5
6
# 모델 상태 저장
torch.save(
model.state_dict(),
"../models/model_state_dict.pt"
)
모델 상태(torch.state_dict)는 모델에서 학습이 가능한 매개변수를 순서가 있는 딕셔너리(OrderedDict) 형식으로 반환한다.
1
2
3
4
5
6
7
8
9
10
11
# 모델 상태
OrderedDict(
[
(
'layer.weight', tensor([[3.1076, -1.7026]], device='cuda:0')
),
(
'layer.bias', tensor([0.0293], device='cuda:0')
)
]
)
학습된 CustomModel 객체의 가중치(weight)와 편향(bias)이 저장되어 있다. 즉, 추론에 필요한 데이터만 가져와 저장하는 방식이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 모델 상태 불러오기
import torch
from torch import nn
class CustomModel(nn.Module):
def __init__(self):
super().__init__()
self.layer = nn.Linear(2, 1)
def forward(self, x):
x = self.layer(x)
return x
device = "gpu" if torch.cuda.is_available() else "cpu"
model = CustomModel().to(device)
model_state_dict = torch.load("../models/model_state_dict.pt", map_location=device)
model.load_state_dict(model_state_dict)
with torch.no_grad():
model.eval()
inputs = torch.FloatTensor(
[
[1 ** 2, 1],
[5 ** 2, 5],
[11 ** 2, 11]
]
).to(device)
outputs = model(inputs)
모델 상태만 불러오면 모델 구조를 알 수 없으므로 CustomModel 클래스가 동일하게 구현돼 있어야 하며 model_state_dict.pt 도 torch.load 함수를 통해 불러온다.
단, model 인스턴스의 load_state_dict 메서드로 모델 상태를 반영한다.
체크포인트 저장/불러오기
체크포인트(Checkpoint)는 학습 과정의 특정 지점마다 저장하는 것을 의미한다. 학습 과정에서 한 번에 전체 에폭을 반복하기 어렵거나 모종의 이유로 학습이 중단될 수 있다. 이러한 현상을 방지하기 위해 일정 에폭마다 학습된 결과를 저장해 나중에 이어서 학습하게 할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 체크포인트 저장
import torch
import pandas as pd
from torch import nn
from torch import optim
from torch.utils.data import Dataset, DataLoader
## 중략
checkpoint = 1
for epoch in range(10000):
## 중략
cost = cost / len(train_dataloader)
if (epoch + 1) % 1000 == 0:
torch.save(
{
"model": "CustomModel",
"epoch": epoch,
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"cost": cost,
"description": f"CustomModel checkpoint-{checkpoint}",
},
f"../models/checkpoint-{checkpoint}.pt",
)
checkpoint += 1
체크포인트도 모델 저장 함수(torch.save)를 활용해 여러 상태를 저장할 수 있다. 딕셔너리 형식으로 값을 할당해야하며 필수로 포함되어야 하는 정보는 다음과 같다.
- 에폭(
epoch) - 모델 상태(
model_state_dict) - 최적화 상태(
optimizer.state_dict)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 체크포인트 불러오기
import torch
import pandas as pd
from torch import nn
from torch import optim
from torch.utils.data import Dataset, DataLoader
## 중략
checkpoint = torch.load("../models/checkpoint-6.pt")
model.load_state_dict(checkpoint["model_state_dict"])
optimizer.load_state_dict(checkpoint["optimizer_state_dict"])
checkpoint_epoch = checkpoint["epoch"]
checkpoint_description = checkpoint["description"]
for epoch in range(checkpoint_epoch + 1, 10000):
cost = 0.0
for x, y in train_dataloader:
x = x.to(device)
y = y.to(device)
output = model(x)
loss = criterion(output, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
cost += loss
if (epoch + 1) % 1000 == 0:
print(f"Epoch: {epoch+ 1:4d}, Model: {list(model.parameters())}, Cost: {cost:. 3f}")
모델 저장 및 불러오기를 통해 사전에 학습된 모델을 사용하거나 공유할 수 있으며 체크포인트마다 모델 상태를 저장해 가장 최적화된 모델 상태로 추론을 진행할 수 있다.