[BoostCamp AI Tech / Pre-Course 2] 딥러닝 기본 - Generative Model
네이버 부스트코스의 Pre-course 강의를 기반으로 작성한 포스트입니다.
우리는 생성 모델(Generative Model)을 생각하면 대부분 적대적 생성모델(GAN)을 떠올린다. 그러나 그럴듯한 이미지나 문장을 만드는 것이 생성 모델의 전부는 아니다.
생성 모델의 학습 방법
개(dog)의 이미지가 여러 장 주어졌다고 하자.
생성모델의 확률분포(probability distribution) $p(x)$를 학습함으로써 할 수 있는 것은 다음과 같다.
Generation: 확률분포 $p(x)$와 유사한 어떤 새로운 $x_{new}$를 만들어서 ($x_{new} \sim p(x)$), 개와 유사한 이미지를 만들어낼 수 있다. (sampling)Density estimation: 어떤 이미지 $x$가 개인지 아닌지 판별해낼 수 있다. $p(x)$가 높게 나온다면 개이고, $p(x)$가 낮게 나온다면 개가 아니다. (anomaly detection)- 엄밀한 의미의 생성 모델은
Discriminator모델까지 포함하고 있다. 어떤 이미지가 특정 레이블에 속하는 지 아닌지 판단할 수 있어야 한다. - 이처럼 Discriminator를 포함한 생성 모델을
명시적 모델(Explicit Model)이라고 하며, Generation만 할 수 있는 모델을암시적 모델(Implicit Model)이라고 한다.
- 엄밀한 의미의 생성 모델은
Unsupervised representation learning: 이미지들 사이에서 feature(특징,공통점)을 찾아낼 수 있다.(feature learning)
그렇다면 $p(x)$는 무엇일까? $p(x)$는 $x$를 집어넣었을 때 나오는 값일수도 있고, $x$를 샘플링할 수 있는 어떤 모델일수도 있다. 이 $p(x)$를 알기 위해서는 먼저 확률에 대한 간단한 선행지식이 필요하다.
Basic Discrete Distributions
베르누이 분포(Bernoulli distribution) : 앞, 또는 뒤만 나오는 동전 던지기와 같다.(0,1)
- $D$ = [앞면(Head), 뒷면(Tails)]
- 앞면이 나올 확률이 $P(X=Heads)=p$ 라면, 뒷면이 나올 확률은 $P(X=Tails)=1−p$이다.
- 이를 $X∼Ber(p)$로 표현한다.
- 파라미터는 1개($p$ 하나)
카테고리 분포(Categorical Distribution) : $m$ 개의 면을 가지는 주사위를 던지는 것과 같다.
- $D$ = [1, 2, … , m]
- 주사위를 던져 $i$ 가 나올 확률을 $P(Y=i)=p_i$라고 한다면, $\sum_{i=1}^m p_i = 1$이다.
- 이를 $Y∼Cat(p_1, \ldots, p_m)$이라고 한다.
- 파라미터는 $m-1$개
ex. RGB 픽셀 하나의 확률분포를 구해보자
- $(r,g,b) \sim p(R,G,B)$
- 가능한 색상의 종류(경우의 수) : $256 \times 256 \times 256$개
- 필요한 파라미터의 개수 : $256 \times 256 \times 256 - 1$개
단 하나의 RGB 픽셀을 표현하기 위한 파라미터 숫자가 굉장히 많다.
ex. 이번엔 $n$개의 binary pixels(하나의 binary image) $X_1, \ldots, X_n$이 있다고 치자.
- 가능한 경우의 수 : $2 \times 2 \times \ldots \times 2 = 2^n$개
- 필요한 파라미터의 개수 : $2^n - 1$개
이처럼, 바이너리 이미지를 나타내는 데에도 너무 많은 파라미터가 필요하다.
그러나 파라미터의 개수가 늘어나면 모델의 학습은 일반적으로 잘 되지 않는다. 이 파라미터를 줄일 방법은 없을까?
Structure Through Independence
위의 binary image 사례에서, 모든 픽셀 $X_1, \ldots, X_n$가 각각 독립적이라고 가정(independance assumption)하면, 다음과 같다.
\[P(X_1, \ldots, X_n) = P(X_1)P(X_2)\cdots P(X_n)\]- 가능한 경우의 수 : $2^n$개
- $P(X_1, \ldots, X_n)$을 구하기 위해 필요한 파라미터의 개수 : $n$ 개
동일하게 $2^n$개의 경우의 수를 나타낼 수 있지만, $n$ 개의 파라미터만 있으면 된다.
당연히 말이 안되는 가정이긴 하다. 이미지 사진이므로 각 픽셀사이의 분포는 아무래도 인접할수록 비슷할 확률이 높은데, 이를 완전히 무시한 가정이기 때문에, 적당한 분포로 모델링하기에는 좋지 않다.
Conditional Independence
기존의 Fully Dependant 모델링과 Independent 모델링의 중간점으로 타협한 것이 Conditional Independence이다.
Conditional Indepence는 다음과 같은 3가지 핵심 룰로 동작한다.
연쇄법칙(Chain rule)
베이즈 정리(Bayes' rule)
\[\text{if } x\perp y|z, \text{then } p(x|y,z)=p(x∣z)\]조건부독립- $z$가 주어졌을 때 $x$와 $y$가 독립적이라면, $y$, $z$가 주어졌을 때 $x$가 일어날 확률은 그냥 $z$만 주어지더라도 $x$ 가 일어날 확률과 같다. 즉 $y$는 상관이 없다.
- 이것으로 연쇄법칙의 conditional 부분을 날릴 수 있다.
조건부 독립이 잘 이해되지 않는다면, 적절한 예시를 들어 잘 설명해놓은 다음 글을 참고한다.
참고: 조건부 독립(Conditional Independence)
그럼 binary 이미지 예제에서 연쇄법칙을 이용한다고 가정해보자.
필요한 파라미터의 개수는 몇개일까?
$P(X_1)$ : 1개
$P(X_2 | X_1)$ : 2개 (하나는 $P(X_2 | X_1) = 0$, 나머지 하나는 $P(X_2 | X_1)=1$)
$P(X_3 | X_1, X_2)$ : 4개 (입력 $X_1$, $X_2$를 모두 고려한다)
따라서 , 최종적으로 필요한 파라미터의 개수는 $1+2+2^2+ \cdots +2^{n−1}=2^n−1$로, Fully Dependant 모델과 같다.
이제, Markov assumption을 가정해보자. 즉, $X_{i+1}$는 $X_i$에만 dependant하고, $X_1, \ldots, X_{i-1}$ 까지에는 independent하다고 가정한다.($X_{i+1}\perp X_1, \ldots, X_{i-1} | X_i$)
이 경우 파라미터 개수는 $2n−1$이다.
따라서, Markov assumption을 적용시킴으로써 파라미터의 개수를 지수차원에서 끌어내릴 수 있다.
Autoregressive Model은 이 conditional independance를 잘 활용한 모델이다.
Auto-regressive Model
28x28크기의 바이너리 이미지(픽셀들의 모음)이 있다고 하자.
우리는 $X \in { 0,1 }^{784}$인 $X$에 대해 $P(X) = P(X_1, \ldots, X_{784})$를 구해야한다. 이 때 $P(X)$를 어떻게 파라미터로 표현할 수 있을까?
- 연쇄법칙을 이용해 결합분포를 나눈다.
- $P(X_{1:784}) = P(X_1)P(X_2 | X_1)P(X_3 | X_2) \cdots$
- 이것을
AR모델(Autoregressive Model, 자기회귀모델)이라고 한다.- AR모델은 하나의 정보가 이전 정보에 dependant한 것을 의미한다. 바꿔말하면, Markov assumption처럼 직전 정보에만 dependant한것도 AR모델이고, $X_1, \ldots, X_{i-1}$까지에 모두 dependant한 것도 AR모델이다.
- 이전의 $n$개 정보들을 고려하는 모델을
AR(n) 모델이라고 부른다.
- AR 모델은 1차원 시퀀스가 필요하기 때문에 2차원, 3차원 공간에 존재하는 이미지를 한 줄로 피는
ordering작업이 필요하다.- raster scan order: 랜덤한 variable들에 각각 순서를 매기는 방법이다.
어떤 식으로 Coditional Indepedency를 주는가에 따라 연쇄법칙을 이용해 결합분포를 나누는 방식에 차이가 생기므로, 결과적으로 AR모델의 structure가 달라진다.
NADE: Neural Autoregressive Density Estimator
Autoregressive 모델을 Neural Network 혹은 딥러닝에 가장 먼저 활용했던 모델이 NADE이다.
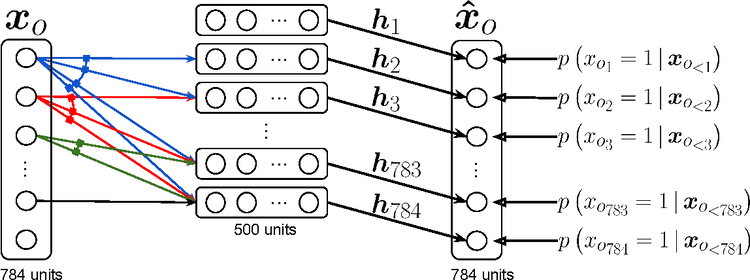
먼저 전체 이미지를 한 줄로 피고 $i$번째 픽셀 $x_i$는 그 이전까지의 모든 픽셀들에 대해 dependant하다. 픽셀의 순서가 뒤로 갈수록 받는 입력($x_{1:i-1}$)의 수가 많아지므로, weight의 길이가 가변적이다. 그 이외에는 AR모델과 동일하다.
NADE는 explicit 모델로, 주어진 입력값의 확률(density)를 계산할 수 있다.
- 784 픽셀의 바이너리 이미지라고 가정하면, 각 조건부 확률 $p(x_i | x_{1:i-1})$이 독립적으로 계산될 때 결합분포를 다음과 같이 계산할 수 있다.
- 각각의 $p(x_i|x_{1:i-1})$을 차례대로 계산해 대입하면, 전체 확률을 알 수 있게 된다.
이러한 방식은 이산변수만이 아니라 연속변수또 한 모델링 할 수 있다는 장점이 있다. 이러한 경우에는 가우시안 혼합(Gaussian mixture) 모델을 이용한다.
논문: Neural Autoregressive Distribution Estimation
Summary
Autoregressive model의 특징을 정리하면 다음과 같다.
- 조건부 확률의 연쇄 법칙을 이용해 전체 입력의 확률 분포를 차원별로 분해하여 샘플링이 비교적 용이합니다.
- 새로운 입력이 주어졌을 때 그 데이터의 확률을 쉽게 계산할 수 있다.
- 이산적인 데이터뿐만 아니라, 오디오 신호나 이미지 픽셀 같은 연속적인 데이터에도 모델을 적용할 수 있다.
- 순차적인 생성 과정 때문에 병렬화가 불가능하다.
- $i$ 번째의 입력을 만들기 위해서는 $i-1$번째가 필요하기 때문에 생성이 느리다.
이 글은 비밀번호로 보호되어 있습니다.