[BoostCamp AI Tech / Pre-Course 2] 딥러닝 기본 - Recurrent Neural Networks
네이버 부스트코스의 Pre-course 강의를 기반으로 작성한 포스트입니다.
MLP는 벡터를 다른 벡터로 바꾸는 것이었고, CNN은 이미지를 원하는 형태로 바꿔주는것이었다면, RNN은 시퀀셜 모델을 다루는 것이다.
Sequential Model
시퀀스 데이터를 처리하는데에 가장 어려운 것은, 길이가 언제 끝날 지 모른다는 것이다. 따라서 받아들여야하는 입력의 차원을 알 수가 없다. 시간이 지날수록, 고려해야하는 과거의 정보량이 늘어난다.
Naive sequence model
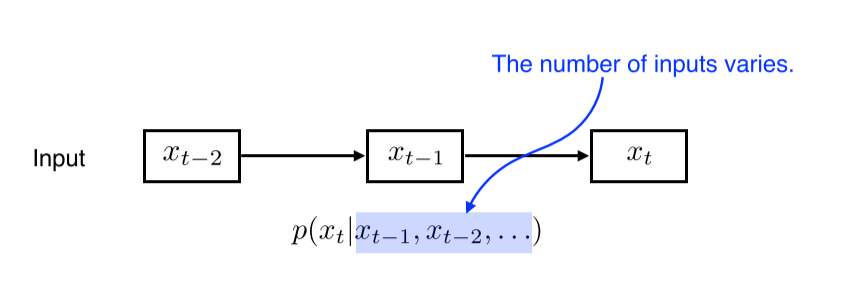
가장 기본적인 sequence model은 입력이 여러 개 들어왔을 때 다음 번 입력을 예측하는 것이다. 시간이 지날수록 봐야할 과거 정보가 많아져 계산량이 많아진다.
- ex. Language Model
Autoregressive Model
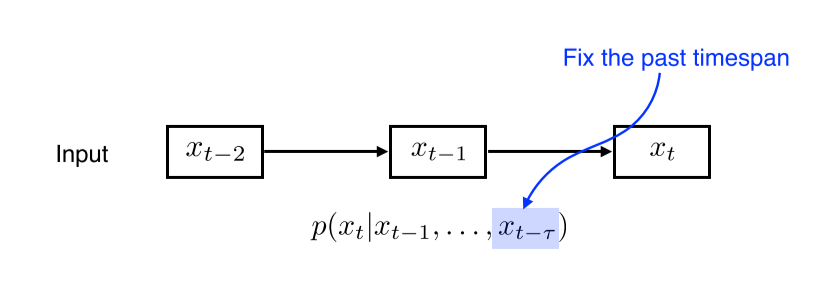
이를 가장 간단히 해결하는 방법은, 고정된 길이($\tau$)의 과거 정보만을 확인하는 것이다. 정해진 길이의 과거 정보만을 확인하기 때문에 계산이 쉬워진다.
Markov model(first-order autoregressive model)
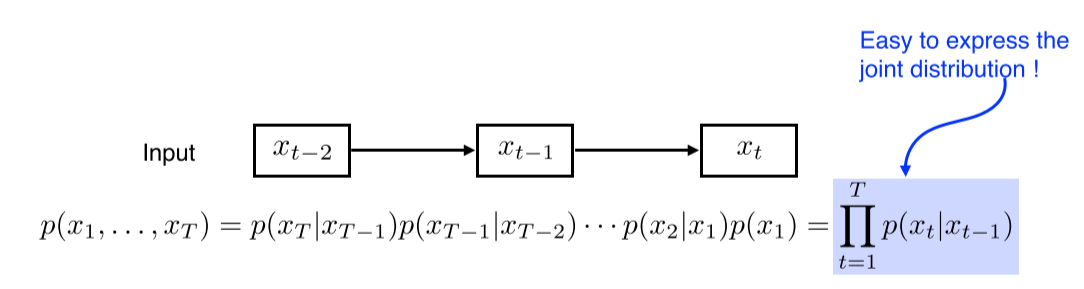
Autoregressive Mdoel 중 가장 쉬운 방법은 Markov Model이다. 이 모델을 극단적으로 간단히 만든 것이 바로 직전 시점 정보만을 고려하는 AR(1) 모델이다. 하지만 너무 많은 정보를 버릴 수밖에 없다.
Latent Autoregressive Model
기존 AR 모델이 직전정보까지밖에 고려하지 못했기 때문에, 이를 보완하여 그 이전 과거의 정보들을 ‘기억’할 수 있는 새로운 AR 모델이 나오게 되었다. 이를 Latent Autoregressive Model이라고 한다.
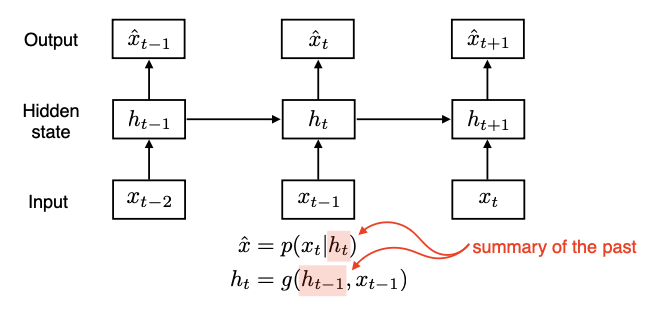
이 모델의 포인트는 hidden state(또는 latent state) $h_t$에 있다. 출력값(다음 시점의 정보)은 입력값(해당 시점의 정보)에 그 전까지의 모든 시점정보들을 요약(summary)한 $h_t$를 고려하여 만들어진다.
Recurrent Neural Network
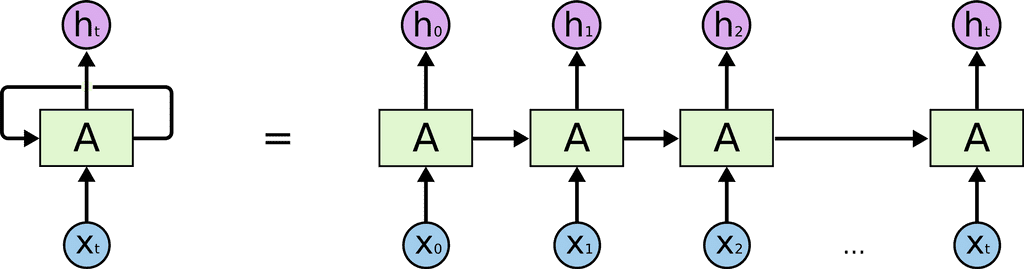
RNN을 시간순으로 풀면(un-roll) 위와 같은 모형도가 나오게 된다. RNN처럼 Recurrent(되풀이) 구조가 있는 모델을 시간순으로 풀게 되면, 결국 (과거의 입력들이 같이 들어오므로) 입력이 굉장히 많은 네트워크로 볼 수 있게 된다.
문제는 과거의 정보들을 미래의 정보로 끌고오기 때문에, 역설적으로 더 오래된(멀리있는) 정보일수록 살아남기가 힘들다는 것이다.

RNN은 이처럼 Short-term dependencies는 잘 잡을 수 있지만, Long-term dependencies는 잘 잡지 못한다는 치명적인 단점이 있다.
그렇다면 RNN 학습이 도대체 왜 어려운 것일까?
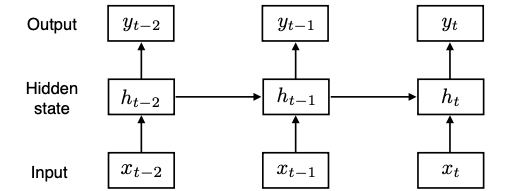
RNN은 이런식으로 과거의 $h$ 들을 고려하는 중첩된 구조이다. $\phi$는 활성화함수(activation function)이다. 시퀀스 길이가 늘어남에 따라, 이처럼 중첩되는 가중치와 activation function이 굉장히 많아진다.
위의 식에서 만약 활성화함수가 sigmoid라고 하자. sigmoid의 성질은 값을 계속 0과 1사이로 바꿈으로써 축소시키는 것이므로, 함수가 중첩될수록 점점 vanishing gradient의 문제가 생긴다.
만약, sigmoid가 아닌 ReLU함수라면 어떨까? ReLU함수는 $x>0$ 일때 해당 input을 그대로 가져가므로, $W$와 input의 곱이 계속 쌓이는 구조가 될 것이다. 따라서 자칫하면 Gradient가 아주 커져 네트워크가 터지는 exploding gradient의 문제가 생긴다.
LSTM
이러한 Vanilla RNN 단점을 해결, 즉 Long-term dependencies를 확보하기 위해 만들어진 모델이 Long Short term Memory(LSTM)이다.
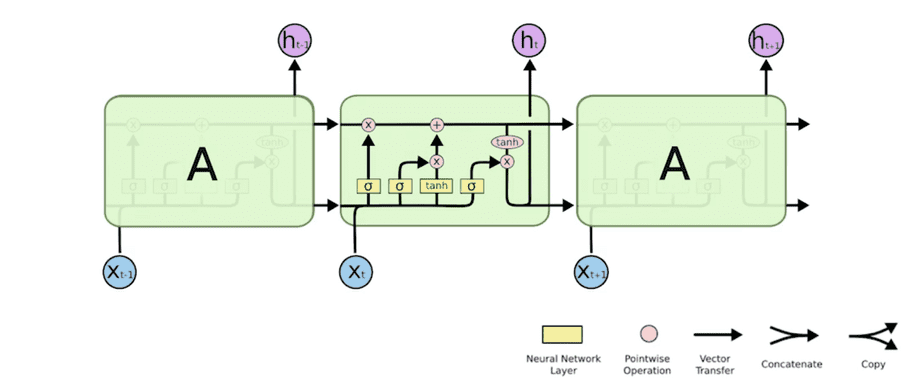
위는 RNN과 대비되는 LSTM의 모형인데, 언뜻 보면 아주 복잡해보인다.
LSTM의 핵심 아이디어는 Cell State이다. 컨베이어 벨트로 이해하면 쉬운데, 매 시점마다 컨베이어벨트로 과거 시점의 정보들이 죽 전달되고, 각 시점에서 [해당 입력값을 넣을 것인지 말 것인지], [어떤 정보를 summary에 추가할 것인지], [출력값으로 얼마만큼 내보낼 것인지]를 Gate에서 결정한다.

- $x_t$ : 시퀀스 데이터로 만든 현재 시점의 입력값 벡터
- $h_t$ : 출력값(이자 hidden state)
- Previous cell state($c_{t-1}$) : 출력값으로 나가지는 않고, 매 시점마다 과거 시점들의 입력정보들을 linear하게 취합/전달하여 보여주는 값.
Forget Gate에 의해 제어된다. - Previous hidden state($h_{t-1}$) : 이전 시점의 출력값.
주요한 아이디어로는 이전 정보를 요약하는 Cell State이다. 지금까지의 정보를 잘 조작해서 어떤 정보가 유용한지 판단하여 이를 다음 cell에 넘겨준다.

또한, LSTM에는 총 3개의 게이트가 있다.
Forget Gate: 얼마만큼 지울(버릴) 것인지- 해당 정보를 버릴 것인지, 아니면 살려서 전달할 것인지 결정한다. 현재 입력 $x_t$ 와 이전 출력 $h_{t−1}$ 을 입력으로 받아 sigmoid를 적용시키므로 0과 1 사이의 값을 갖게된다.

Input Gate: 무엇을 올릴 것인지- 해당 정보 중 어느 것을 cell state에 저장(추가)할 것인지 정한다. $x_t$와 $h_{t-1}$ 를 입력으로 받아 sigmoid를 적용시킨 값 $i_t$를 곱해서 정보를 취사선택한다. tanh를 적용시킨(출력값은 -1과 1 사이) 이번 시점의 Cell state $\tilde{C}_t$를 만들어 지금까지의 Cell state에 섞어서 업데이트한다.

Update Cell: 직전까지의 정보를 Summary한 $C_{t-1}$에 Forget Gate를 통과한 값을 곱하고, 이번 시점의 Input Gate를 통과한 값을 더하여 새로운 $C_t$로 업데이트한다.
Output Gate: 얼마만큼 내보낼 것인지- Update한 cell state를 한번 더 조작하여 어떤 값을 밖으로 내보낼 지 결정한다. Output Gate만큼 곱해서(element-wise multiplication) 현재의 아웃풋 $h_t$를 만들어낸다.

GRU
기존의 LSTM이 너무 복잡한 구조를 가지고 있어, 이를 조금 더 단순하게 만든 모델로 뉴욕대 조경현 교수가 제안한 알고리즘이다. Gated Recurrent Unit의 약자로, 게이트가 3개 있던 LSTM과는 달리 2개의 게이트(reset, update)만을 가진다. 또, cell state가 없고, hidden state만 가진다.
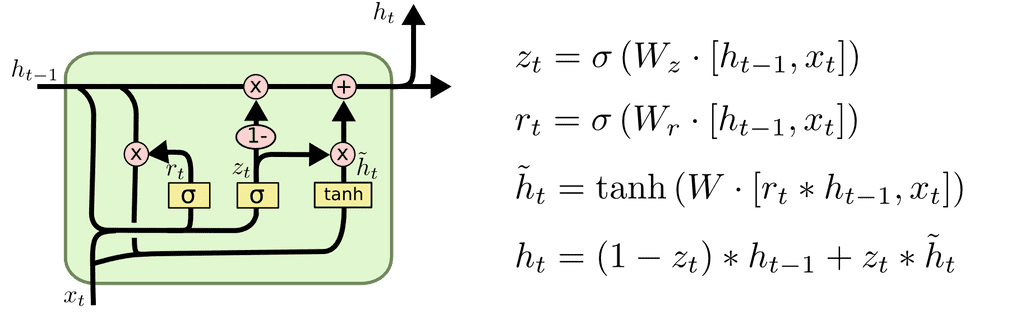
Reset Gate가 기존의 Forget Gate역할을 하고, Input&Output Gate가 합쳐져 Update Gate 역할을 한다고 볼 수 있다.
파라미터 개수가 LSTM보다 적음에도 불구하고 비슷한 작용을 하므로, 대체로 일반화 성능이 좋은 편이다.
그러나 최근에는 LSTM과 GRU 모두 Transformer가 나오면서 대체되고 있는 추세다.
이 글은 비밀번호로 보호되어 있습니다.