[Database] (쉬운 코드) SQL로 DB에 데이터 조작(INSERT/UPDATE/DELETE)
쉬운 코드 강의 「데이터베이스」 내용을 바탕으로, SQL로 DB에 데이터를 추가/수정/삭제하는 방법을 정리한 포스트 입니다.
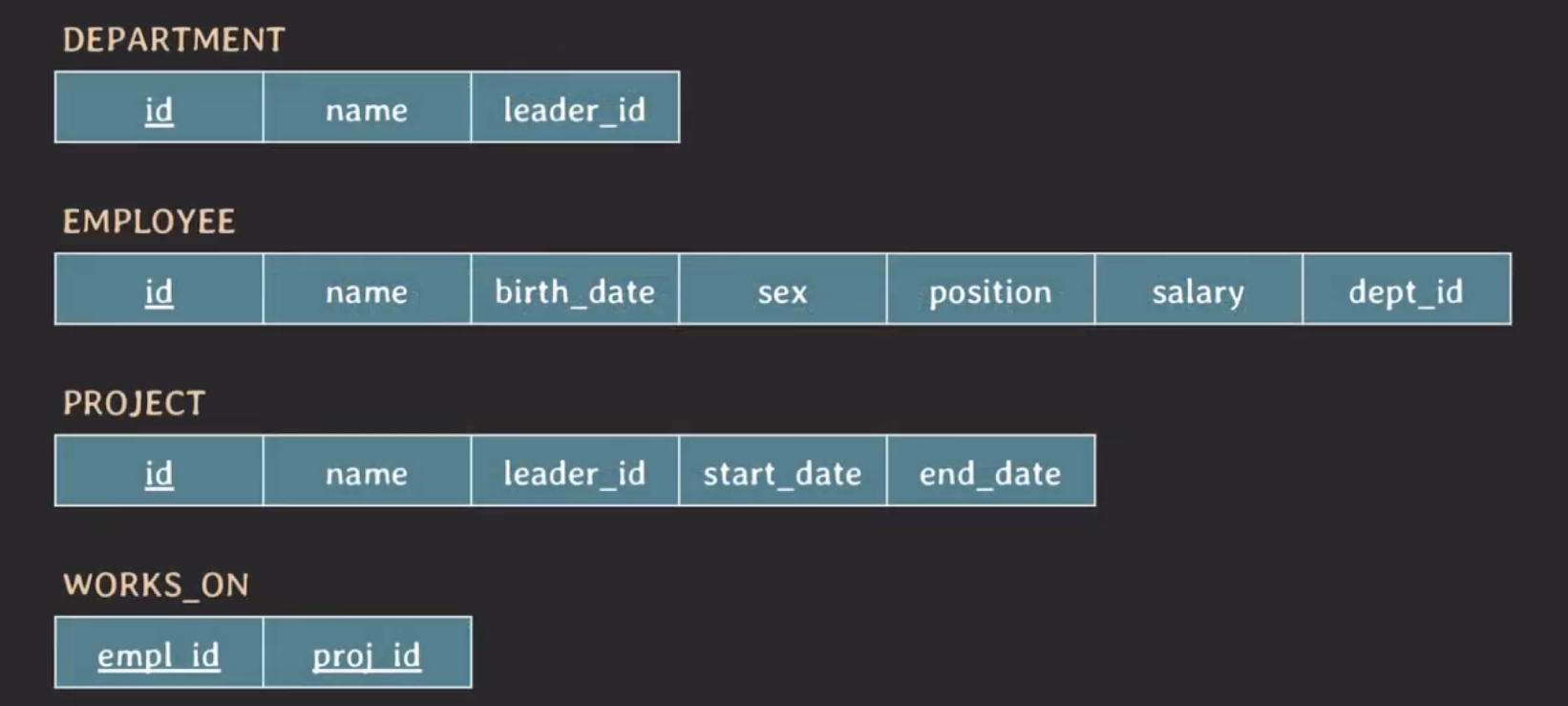
테이블 구조
우선 시작하기에 앞서 내용 이해에 필요한 테이블 구조입니다.
데이터 추가
EMPLOYEE 테이블에 값을 추가하는 방법은 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
create table EMPLOYEE(
id INT PRIMARY KEY,
name VARCHAR(30) NOT NULL,
birth_date DATE,
sex CHAR(1) CHECK (sex in ('M', 'F')),
position VARCHAR(10),
salary INT DEFAULT 5000000,
dept_id INT,
FOREIGN KEY (dept_id) references DEPARTMENT (id)
on delete SET NULL on update CASCADE,
CHECK (salary >= 5000000)
);
INSERT INTO employee
VALUES (1, 'MESSI', '1987-02-01', 'M', 'DEV_BACK', 10000000, null);
테이블에 데이터를 추가할 경우, 처음에 테이블을 정의할 때 모든 attribute에 대응하는 값을 순서대로 입력해야한다.
위의 예제에서 dept_id가 null 인 이유는 아직 DEPARTMENT에 어떠한 값이 없기 때문이다. 만약 이러한 경우에 null이 아닌 값이 들어가면 에러가 뜬다.
입력 데이터가 성공적으로 추가가 되었다면 Query OK, 1 row affected (0.05sec) 이라고 뜬다.
만약 성공적이지 않는다면 ERROR 1062 (23000): 이런 식의 에러가 출력된다.
❗️ERROR message
만약 에러 메세지 Check constraint ‘employee_chk_2’ is violated 에서 ‘employee_chk_2’ 를 구체적으로 알고 싶으면
SHOW CREATE TABLE employee;를 입력하여 알아낼 수 있다.
1
2
INSERT INTO employee (name, birth_date, sex, position, id)
VALUES ('JENNY', '2000-10-12', 'F', 'DEV_BACK', 3);
위 코드 방식대로 입력하면 값을 넣는 순서 자유도가 생긴다. 또한, 원하는 attribute만 넣을 수 있다. 넣지 않는 값들은 처음 스키마를 그릴 때 지정한 DEFAULT 값이 들어가며 만약 DEFAULT 값이 없다면 NULL이 들어간다.
이렇게 추가한 데이터가 잘 추가가 되었는지 확인하기 위해서는 SELECT * FROM employee;를 입력하면 전체 테이블을 볼 수 있다.
위의 내용을 정리하면 다음과 같다.
- 한 개의 value를 추가
INSERT INTO table_name VALUES (comma-separated all values);INSERT INTO table_names (attributes list) VALUES (attributes list 순서와 동일하게 comma-separated values);
- 여러 개의 value를 추가
INSERT INTO table_name VALUES (..., ..), (..., ..), (..., ..);
데이터 수정하기
이미 저장된 데이터를 어떻게 수정할 수 있을까?
ex. employee ID가 1인 Messi는 개발(development)팀 소속이고 개발팀 ID는 1003이다. 이때, NULL값인 개발팀 ID를 업데이트를 해주자.
1
UPDATE employee SET dept_id = 1003 WHERE id = 1;
WHERE은 조건을 나타내는 키워드이다.
수정이 잘 되었는지 바꾼 데이터만 확인하고 싶으면 아래와 같은 코드를 입력하면 조회할 수 있다.
1
SELECT * FROM employee WHERE id = 1;
ex. 개발팀 연봉을 두 배로 인상하고 이 떄 개발팀 ID는 1003이다.
1
UPDATE employee SET salary = salary * 2 WHERE dept_id = 1003;
ex. 프로젝트 ID 2003에 참여한 임직원의 연봉을 두 배로 인상하고 샆다.
1
UPDATE employee, works_on SET salary = salary * 2 WHERE id = empl_id and proj_id = 2003;
id는 employee 테이블의id를 의미한다.id = empl_id가 두 테이블을 연결하는 핵심 코드이다.
좀 더 직관적으로 표현하면 다음과 같이 표현할 수 있다.
1
2
3
UPDATE employee, works_on
SET salary = salary * 2
WHERE employee.id = works_on.empl_id and proj_id = 2003;
ex. 회사의 모든 구성원의 연봉을 두 배로 올리자!
1
2
UPDATE employee
SET salary = salary * 2;
위의 내용을 정리하면 다음과 같다.
1
2
3
UPDATE table_name(s)
SET attribute = value [, attribute = value, ..]
[WHERE condition(s)];
데이터 삭제하기
테이블의 데이터를 삭제하는 방법을 알아보자
ex. John이 퇴사를 하게 되면서 employee 테이블에서 John 정보를 삭제해야 한다. John의 employee ID는 8이고 현재 John은 project 2001에 참여하고 있다.
1
DELETE FROM employee WHERE id = 8;
이 때, WORKS_ON 테이블에서도 John에 관련된 정보를 지워야할까?
답은 지워도 되지 않는다. 그 이유는 처음 WORKS_ON을 만들었을 때 FOREIGN KEY를 통해 on delete CASCADE 라고 옵션을 걸어줬기 때문에 EMPLOYEE 에서 삭제되면 WORKS_ON에서 자동적으로 삭제된다.
ex. Jane이 휴직을 떠나게 되면서 현재 진행 중인 프로젝트에서 중도하차하게 됐다.
1
DELETE FROM works_on WHERE empl_id = 2;
ex. 현재 Dingyo가 두 개의 프로젝트에 참여하고 있었는데 프로젝트 2001에 선택과 집중을 하기로 하고 프로젝트 2002에서는 빠지기로 했다. 이때 Dingyo의 ID는 5이다.
1
DELETE FROM works_on WHERE empl_id = 5 and proj_id = 2002;
만약 Dingyo가 여러 프로젝트에 참여하고 있었으며 선택과 집중을 하기 위해 2001만 참여하기로 했다면??
1
DELETE FROM works_on WHERE empl_id = 5 and proj_id <> 2001;
<>와!=은 동일
ex. 회사에 큰 문제가 생겨서 진행중인 모든 프로젝트를 중단해야한다.
1
DELETE FROM project;
❗️WHERE 없이 동작하는 코드
WHERE없이 실행한 코드는 모든 데이터를 삭제하거나 수정하는 것이기 때문에 매우 조심히 사용해야한다.
위의 내용을 정리하면 다음과 같다.
1
2
DELETE FROM table_name
[WHERE condition(s)];