[BoostCamp AI Tech / CV 이론] CNN 시각화와 데이터 증강
CNN 모델의 내부 동작을 가시화하는 방법과 데이터 증강 기법에 대해 정리한 포스트입니다.
Visualizing CNN
CNN 학습 시에 어떤 과정으로 정확한 prediction을 학습하게 되는지는 블랙박스로 남아있다. 또, 성능이 잘 나오지 않는다면 어떤 이유로 학습이 잘 되지 않았는지도 알기 어렵다. 이러한 점에서 CNN의 내부 시각화의 필요성이 생긴다. 시각화 툴은 일종의 디버깅 툴처럼 사용될 수 있다.
- ZFNet이 시각화 툴을 사용했던 사례
Vanilla example : filter visualization
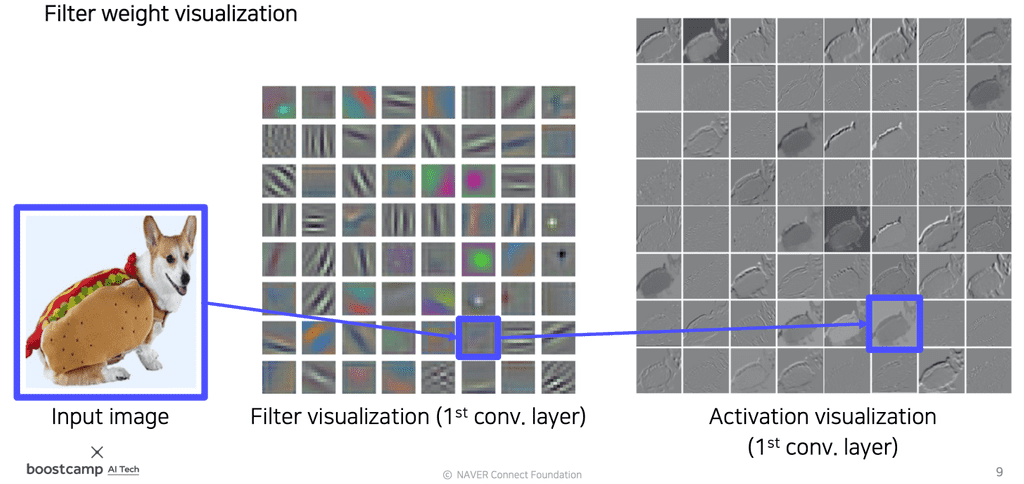
가장 간단한 시각화 방법으로는, 필터 자체를 시각화하거나 특정 필터에 대응하는 Activation Map을 통해 어떤 영역이 해당 필터와 얼마나 많이 correlation 되어있는지 분석을 할 수 있다.
다만, 초기 layer에는 catch하는 영역이 명확하게 보이지만, 중-후기 layer로 갈수록 앞쪽 layer의 필터들과 합성되어서 더 추상적인 정보를 detect하므로 사실상 사람이 해석가능한 정보가 별로 없어 시각화의 의미가 없다.
이외에도 모델을 분석하고 시각화하는 다양한 방법이 있다. 모델을 중심으로 분석하는 model behavior 분석과 데이터를 중심으로 분석하는 model decision 방법으로 분류될 수 있다.
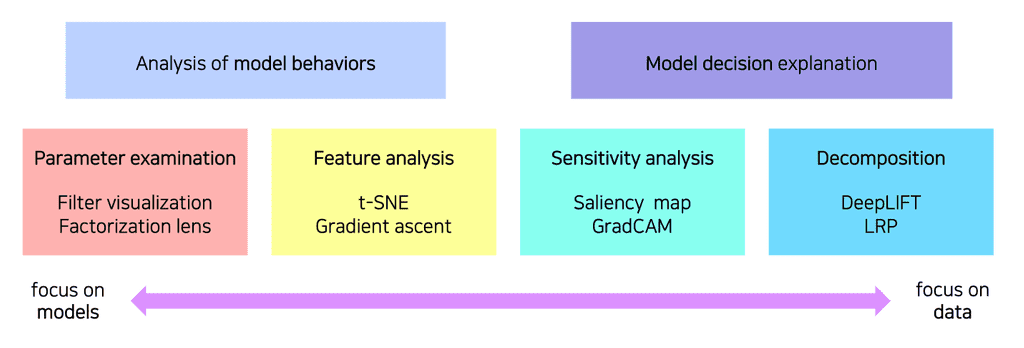
Analysis of model behaviors
모델의 행동에 집중하여 분석하는 방법에 대해 살펴보자.
Embedding feature analysis
모델의 High-level layer에서 얻는 High-level feature를 통해서 분석하는 방법이다.
분석에 대한 이미지를 모델에 넣은 후 마지막 단의 feautre vector를 추출해서 DB와 가장 가까운 이미지를 찾는 방식으로 분석을 한다.

만약, 모델이 잘 학습되었다면 의미론적으로 유사한 이미지들이 잘 찾아지고 cluster 될 것이며 이 이미지들을 보고
이러한 방식은 모델이 어떤 지식을 학습하고 특정한 컨셉에서 어떤 형태를 주목해서 학습을 했는지 관찰할 수 있다.
Dimensionality reduction
너무 고차원의 feature space를 상상하거나 눈으로 확인하여 판단하기 어렵다는 문제점이 있다. 앞서 설명한 방법은 고차원 벡터를 보고 판단하거나 직접 분석할 수 있는 방법이 없기 때문에 사전에 구축한 데이터 샘플을 이용해 간접적으로 분석한 방법이다.
하지만 이 방법외에도 차원을 축소하여 분포를 확인하는 방법도 있다.
대표적인 방법으로 t-distributed stochastic neighbor embedding(t-SNE) 가 있다.

고차원 사이의 상대적인 거리가 가까운 정도를 유지하는 새로운 벡터를 학습시킨다.
시각화를 하면 각 클래스마다 얼마나 구분하고 있는제 어떤 데이터가 아직 헷갈리게 구분되는지를 알 수 있다.
Activation investigation
위의 두 방법처럼 High level feature을 분석하는 방법 말고도 middle level과 low level을 분석하는 Layer activation 방법도 있다.
Layer activation
이 방법은 미리 labeling 된 segmentation 데이터셋을 활용한다.

구체적으로, CNN과 같은 모델의 중간 계층(channel)에서 나오는 activation map을 마스크(mask) 형태로 추출한 뒤, 이를 미리 준비한 segmentation과 비교하여 어떤 채널이 어떤 객체나 부분적 의미에 강하게 반응하는지를 확인한다.
그 결과, 각 체널에 overlap이 큰 label을 찾아 해당 채널에 의미(tag)를 할당할 수 있다.

위의 사진을 보면, conv5 layer에서 hidden unit 중 하나를 뽑아서 thresholding하여 masking했더니 어떤 노드는 얼굴만 찾아내고, 어떤 노드는 계단만 찾아내는 것을 확인할 수 있다.
학습 과정에서 특정 채널이 어떤 기능을 수행하는지를 시각화할 수 있다. 이러한 관점에서 CNN은 층을 거듭할수록 중간 계층의 채널들이 다양한 객체의 부분적 특징에 반응하며, 최종적으로는 이러한 부분적 탐지 결과들을 종합하여 전체 객체를 인식하는 방식으로 동작한다고 해석할 수 있다.
이 접근법의 장점은, pre-trained 모델을 사용하면서도 추가 학습 없이 채널별로 “어떤 클래스 또는 부가적 속성(feature)”에 반응하는지 해석할 수 있다.
따라서 단순히 최종 출력에 국한되지 않고, 모델이 학습 과정에서 내재적으로 포착한 다양한 의미 단위를 발굴할 수 있습니다. 이는 특정 클래스 감지뿐만 아니라 예상치 못한 부수적인 클래스나 속성 감지에도 활용될 수 있습니다.
Maximally activating patches

위 이미지는 CNN의 각 층에서 가장 높은 값을 가지는 hidden unit 주위의 영역을 뜯어낸 patch들의 사진인데, 이를 보면 해당 unit이 어떤 역할을 하고 있는지 확인할 수 있다. 어떤 유닛은 강아지의 코를, 어떤 유닛들은 색깔이 들어간 글자를 찾는 역할 등을 한다. 이 경우는 전반적인 큰 그림 보다는 국부적인 patch를 보므로 비교적 middle-level의 해석에 좋다.
과정은 다음과 같다.
- 특정 layer에서 channel 하나를 고른다.
- 예제 데이터를 backbone network에 넣어서 각 layer의 activation map을 모두 뽑고, 골랐던 채널의 activation map을 저장한다.
- 최대 activation value 주위의 이미지 패치를 잘라낸다(crop).
- 해당 value가 커버하는 receptive field를 찾아서 그것을 주위 영역으로 판단한다.
Class visualization
Class visualization은 예제 데이터를 사용하지 않고, 네트워크가 기억(내재)하고 있는 이미지를 시각화하여 판단하는 방법이다.
이미 학습된 CNN을 두고 입력 이미지(dummy image) 값들을 gradient ascent로 업데이트하는 방식이다.

위의 이미지에서는 새(bird) 클래스와 개(dog) 클래스에 대한 네트워크의 예상치를 확인한 것이다.
이 때, 우하단을 보면 개를 제외하고도 아이의 형태가 나온 것을 확인할 수 있는데, 이를 통해 클래스 분류에 단순히 해당 객체만 파악하는 것이 아니라, 주변 객체와의 연관성도 파악한다고 해석할 여지가 있다. 또한, 학습 데이터에서 개가 대부분 아이와 등장했다는 것을 의미하므로, 학습 데이터의 편향성도 의심해볼 수 있다.
이 방법은 최적화를 통해 구현해야한다.
\[\begin{align*} I^{*} &= \underset{I}{argmax} \ (f(I) - \text{Reg}(I)) \\ &\text{Reg}(I) = \lambda \lVert I \rVert _2 ^2 \end{align*}\]- $I$ : 영상 입력
- $f(I)$ : 입력이 CNN 모델을 거쳐 나온 class score (ex. 개 클래스의 score)
- $Reg(I)$ : $L_2$ 정규화
- 추상적인 값이 공교롭게도 가장 큰 값일 때가 있기 때문에 규제를 통해 입력 자체가 너무 이상하지 않도록 제약을 주는 것이다.
학습 과정에서 모델은 고정하며 입력 $I$만 최적화를 진행한다.
Gradient ascent의 과정은 다음과 같다.
- 임의의 영상(dummy image)를 CNN에 넣어 타깃 클래스의 prediction score를 얻는다.
- Backpropagation으로 입력 image의 gradient를 얻는다.
- 입력이 어떻게 변해야 target score가 높아지는지 찾는다.
Target score가 최대화되는 방향으로 input image를 update 해준다. (즉, gradient를 더해준다)
\[x_{t+1} = x_{t} + \alpha \frac{\partial S_c(x)}{\partial x}\]- $S_c(x)$ : 타깃 클래스 점수
- 업데이트된 영상을 input image로 삼어 1~3 을 반복한다.
이 때 최초의 dummy image는 여러 종류를 선택할 수 있다.
- black / monotone / noisy image 등
- 최초에 넣어준 dummy image를 base로 입력 영상을 업데이트하므로, dummy image의 형태를 어느정도 따라가는 최종 image를 얻게된다.
Model decision explanation
이번엔 모델이 특정 입력 즉, 데이터를 어떤 각도로 바라보고 있는지 살펴보자
Class activation mapping (CAM)
Class activation mapping(CAM) 아키텍처는 CNN의 일부를 개조하여 만들어지며 이미지의 어떤 부분이 최종 결정에 영향을 미치는지를 시각화한다.

CNN의 conv 파트를 최종적으로 통과하고 FC layer에 진입하기 전, 마지막 conv feature map을 대상으로 global average pooling을 수행하여 GAP feature를 얻는다. 이후, 단 하나의 FC layer만 통과시켜 classification한다. 마지막으로 이미지 분류 task에 대해 학습을 다시 수행한다. 즉, 일종의 pretrained된 CNN 모델로부터 유도하는 아키텍처에 가깝다.
- $S_c$ : 클래스 $c$에 대한 score 값
- $k$ : 마지막 conv layer의 채널 수
- $w_k^c$ : 마지막 FC layer에서 클래스 $c$에 해당하는 weight
- $F_k$ : 채널별 conv feature map을 공간 축(여러 채널)에 대하여 global average pooling한 것
- 이 때, $F_k$는 결국 모든 픽셀 $(x, y)$ 에 대해서, conv feature map을 각 채널 $k$마다 평균 취한 것이다.
- $\sum_{(x, y)}$ : Global average pooling
모든 연산들이 선형 연산이므로 순서를 바꿔줄 수 있다. $\text{CAM}_c(x, y)$ 는 결국 global average pooling을 적용하기 전이므로, 아직 공간에 대한 정보가 남아있다. 이것을 visualization하면, 위 이미지의 하단 히트맵처럼 나오게 된다.
CAM 적용을 위해서는 마지막 layer가 GAP과 FC layer로 이루어져야만 하며, 아키텍처를 바꾸고 나서 재학습을 해야한다는 단점이 있다. 이 경우 pre-trained model에 비해 전체적인 성능이 떨어질 수 있다.
이러한 특징으로 CAM을 추출하기에 용이하기 위해 최종 출력 이전에 Global average pooling과 FC layer 층이 이미 존재하는 아키텍처인 ResNet이나 GoogLeNet 같은 모델을 사용하는 사례가 있다.
Global Average Pooling(GAP): GAP의 목적은 feature를 1차원 벡터로 만들기 위해 사용한다.
- CNN에서 각각의 채널마다 모두 평균을 취한 후 이를 합쳐 하나의 벡터로 만드는 과정을 거친다.
- (height, width, channel)을 (channel, ) 형태로 간단하게 만든다.
Grad-CAM
CAM은 최종 층의 구조를 바꿔야 해서 모든 아키텍처에 적용할 수 없다는 제약사항이 있었으므로, 구조를 변경하지 않고 pre-trained 네트워크에서 CAM을 뽑을 수 있는 Grad-CAM 방식이 제안되었다.

기존 pretrained된 모델 아키텍처를 변경할 필요가 없기 때문에, 영상 인식 task에 한정될 필요가 없어졌다. 오로지 backbone이 CNN이기만 하면 사용할 수 있다.
\[\text{CAM} = \sum_{k} {\color{red}{w^c_k}} f_k(x, y)\]기존의 CAM 식에서 알아내야 하는 부분은 $w_k^c$, 즉 important weight 뿐이므로, 이것을 알아내는 것이 핵심이다.
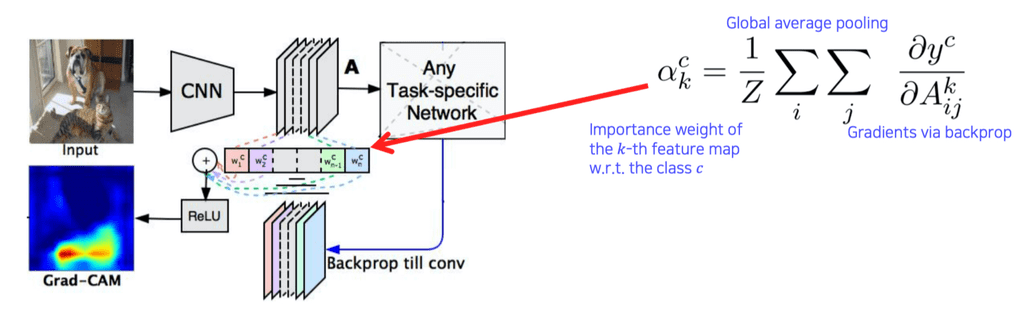
Saliency를 Backprop으로 구했던 방법을 응용해서 수행한다.
여기서의 weight는 기존의 weight와 조금 다른 개념이기 때문에 $\alpha$ 라고 하자.
- 기존의 Saliency test는 입력영상까지 backprop했지만, 여기에서는 원하는 activation map(즉, 특정 conv 층)까지만 backprop한다.
- 클래스 c에 대한 정답 레이블 $y_c$ 로부터 Loss를 구한다.
이렇게 구한 weight가 $a_k^c$ 가 된다.
\[L^c_{\text{Grad-CAM}} = \text{ReLU}(\sum_{k} \alpha_k^c A^k)\]- ReLU를 사용하는 이유는 음수 방향 영향력을 없애기 위해서다.
- 새로이 구한 weight $\alpha_k^c$ 와 activation map $A^k$ 를 선형결합하여 ReLU를 적용한다. 따라서, 양수값만 사용한다.
이를 히트맵으로 표현하면 Grad-CAM이 된다.
Data Augmentation
데이터셋는 항상 편향되어 있다는 것이다. 이미지 데이터를 예로 들자면, 구도, 사진사의 영향 등에 영향을 받기 때문에, 인간이 보기에 좋은 방향으로 치우쳐져 있다. 또 데이터셋은, 현실 데이터셋의 일부분(fractal)에 불과하므로 너무 sparse하기도 하다. 이처럼 학습에 사용되는 샘플 데이터셋과 현실 데이터셋 사이의 격차를 어떻게 메울 수 있을까?
Image Data Augmentation methods/techniques
잘라내기(Crop), 비틀기(Shear), 밝기 조절(Brightness), 원근 변환(Perspective), 회전(Rotate), 반전(Flip), 기하학 변환 등의 다양한 이미지 변환 기법이 사용된다.
OpenCV와 NumPy 라이브러리가 이러한 방식들을 지원하고 있다.
밝기조절(Brightness)- 각 픽셀별 RGB 값에 동일한 값을 더하거나, 적당한 값을 곱하는 등으로 scaling해준다.
회전/반전(Rotate/Flip)- 라이브러리에서 rotate 기능을 지원한다.
잘라내기(Crop)- 사진에서 중요한 파트에 대해 더 강하게 학습할 수 있게 만들어주는 역할을 한다.
기하학 변환
Affine transformation- 이미지의 선(line), 길이 비율(length ratio), 평행성(parallelism)은 보존한다.
- 이미지의 네 꼭짓점 중 세 꼭짓점을 mapping 대응쌍을 AffineTransform 함수에 넣어준다.
- 비틀거나, 회전하거나, 옮겨주는 기하학적 방법을 warping이라고 한다.
- Shear transform이라고도 부른다.
최근의 변환 기법들
CutMix- Cut과 Mix를 모두 사용하여, 잘라낸 각각의 두 사진을 이어붙여 학습 데이터로 사용한다. 이 때, 레이블도 동일한 비율로 조정한다.
- 이를 통해 서로 다른 두 물체의 위치를 좀 더 정교하게 catch할 수 있게 된다.
RandAugmentation- 여러가지 가능한 영상처리 기법을 어떤 방식으로 조합할 지 탐색하는 것. 즉, best sequence of augmentation을 자동으로 탐색하는 기술
- 파라미터: [사용할 기법의 종류(which), 기법의 강도(magnitude)]
- N개의 기법들 사이에서 샘플링한 뒤 수행하여 성능을 비교한다.
이 글은 비밀번호로 보호되어 있습니다.