[BoostCamp AI Tech / CV 이론] CNN to ViT
CNN 모델과 ViT 모델의 등장과 구조에 대한 내용에서 더 나아가 ViT를 이용한 self-supervised 학습 방법을 정리한 포스트입니다.
Image Classification
분류기(Classifier)는 입력을 어떤 카테고리 값과 매핑시켜 내보내는 장치이다. 이미지 분류는 이 분류기의 입력값으로 시각적 데이터만을 사용하여 추론하는 것을 일컫는다.
극단적으로 생각해보았을 때, 모든 분류 문제는 세상의 모든 시각적 데이터를 가지고 있다면 아주 쉽게 해결된다. 그냥 모든 데이터들 사이에서 비슷한 것들끼리 모으기만 하면 된다.
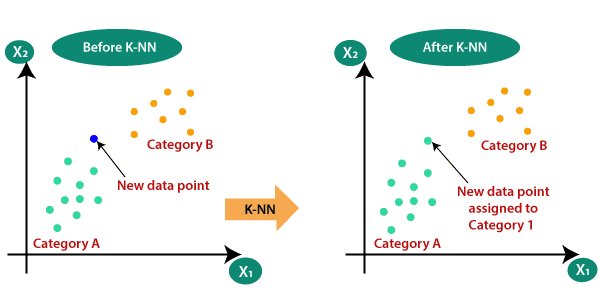
즉, K Nearest Neighbors(K-NN) 문제로 해결할 수 있다. K-NN 문제는 단순히 이미지 레이블 데이터 값을 주위의 다른 데이터 레이블들과 비교하여 가장 비슷하다고 판단되는 후보군으로 편입시키는 문제이다. 이렇게 해결하는 분류기가 있다면, 마치 검색엔진처럼 작동한다.
그러나, 이러한 접근 방식은 불가능하다. Time/Memory Complexity 무한대일 것이라는 점과, ‘비슷하다’는 기준을 어떻게 잡을건지가 모호하다는 것이 결정적인 불가능 요인이다. 따라서 컴퓨터 비젼은 방대한 데이터를 제한된 complexity의 시스템(인공 신경망)이라는 분류기에 녹여넣는 것이 목표이다.
Fully Connected Layer Network
이런 이미지 분류를 가장 간단한 형태의 인공 신경망 분류기, 즉 단일 계층의 Fully Connected Layer Network로 구현했다고 생각해보자.
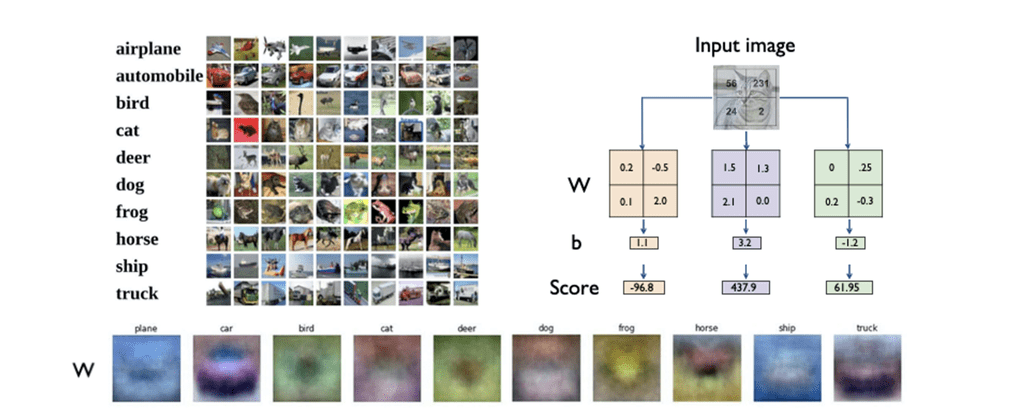
이미지를 모델이 인식하는데 있어 single fully connected layer 방식을 사용하면 다음과 같은 문제가 발생한다.
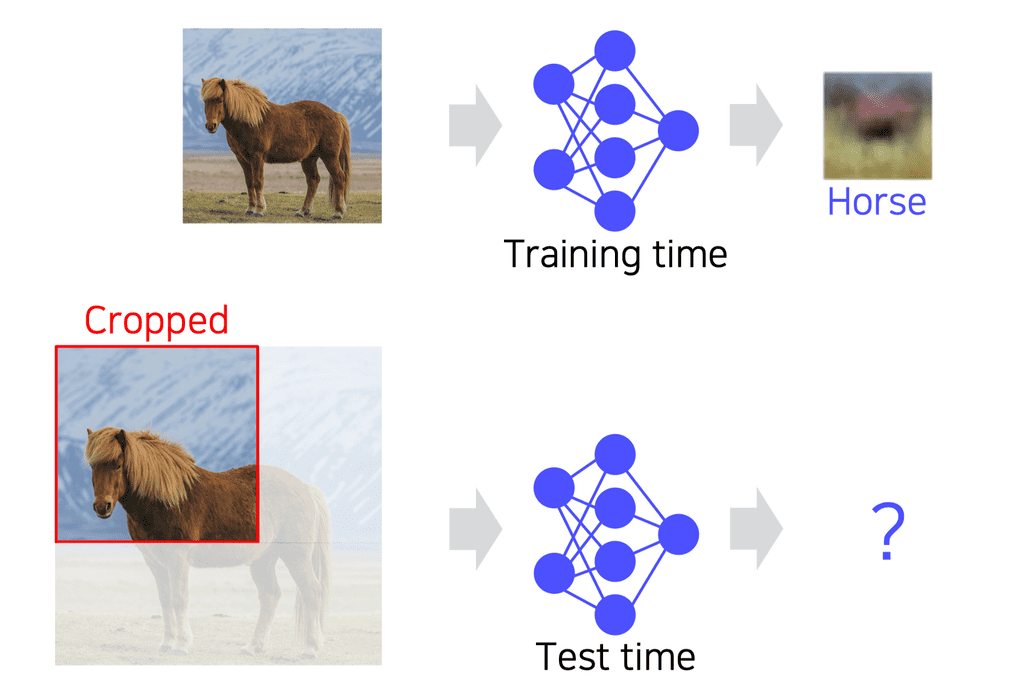
- 같은 클래스에 해당하는 이미지이지만 이전에 학습된 이미지와 달라지면 이를 제대로 인식하지 못한다.
- ex. 학습은 말의 앞모습 전체을 가지고 학습을 했지만, 말의 머리 모양만 crop해서 모델 테스트로 입력하면 말이라고 인식하지 못한다.
- 각 픽셀마다 대응하는 파라미터가 있어야 하므로 굉장히 많은 파라미터가 필요하여 모델의 크기가 굉장히 크다.
Convolutional Neural Network(CNN)
이러한 Fully Connect Layer Network를 해결하기 위해 고안해낸 아이디어가 CNN(Convolutional Neural Networks) 이다.
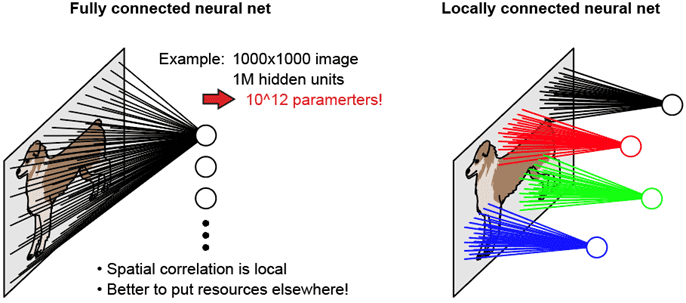
CNN은 모든 노드들을 다음 계층으로 전연결시키는 것이 아니라, 국소적인 연결(locally connect)을 사용한다. 동일한 국소적 sliding window를 이미지의 모든 부분에 대입시켜 feature들을 뽑아냄으로써, 치우쳐 있는 이미지나 잘린 이미지라도 feature를 추출할 수 있고, 파라미터를 재활용하여 메모리도 적게 사용할 수 있다.
이런 장점 때문에 많은 CV task의 backbone으로 활용되고 있다.
CNN 아키텍처의 종류
아래의 그림은 CNN 모델의 발전 과정이다.
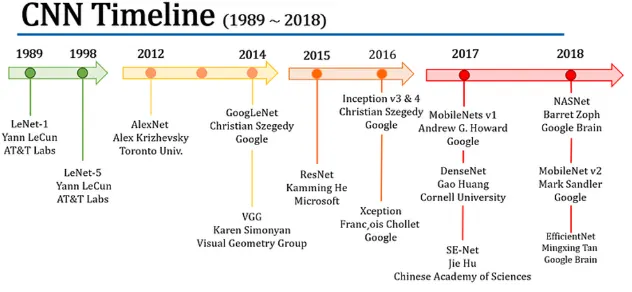
LeNet-5- 1998년 Yann LeCun이 발표
- 구조: Conv - Pool - Conv - Pool - FC - FC
- Convolution size: $5 \times 5$ 필터 + 1 stride
- Pooling: 2 $\times$ 2 max pooling + 2 stride
AlexNet- LeNet에서 모티베이션을 따왔다.
- 파라미터와 학습 데이터를 훨씬 더 크게 늘렸다(605k neurons, 60 million paramters).
- 필터 사이즈가 $11\times11$ 로 아주 크다. 최근에는 이런 큰 필터를 사용하지 않는다.
- 활성화 함수를
ReLU를 사용하고,dropout정규화 기법을 사용했다. - 논문에는 메모리 문제로 두 GPU에 올려서 학습했으며, 그 당시 명암을 조정하기 위해 사용했던 LRN(Local Response Normalization) 기법은 현재는 사용하지 않는다.
- 구조 : Conv - Pool - LRN - Conv - Pool - LRN - Conv - Conv - Conv - Pool - FC - FC - FC
VGGNet- 3x3의 작은 필터와 2x2 max pooling 사용, LRN 제거로 아키텍쳐가 비교적 간단해졌으나 성능은 더 좋아졌다.
- 19 layer로 AlexNet(12 layer)보다 더 깊다.
- 작은 필터크기임에도 불구하고, 더 깊이 층을 쌓아 receptive field의 크기를 키웠다.
- 미리 학습된 feature를 fine-tuning하지 않고도 다른 task에 적용 가능할 정도로 일반화가 잘 되었다.
Receptive field in CNN
Receptive Field(수용 영역)은 컨볼루션 신경망(CNN)에서 출력 레이어의 뉴런 하나에 영향을 미치는 입력 뉴런들의 공간 크기를 의미한다. 만약, $K \times K$ conv과 stride 1 그리고 pooling layer size가 $P \times P$ 라면 수용 영역은 $(P + K - 1) \times (P + K - 1)$ 다.
Receptive field는 CNN 이미지를 인식하는 방식을 이해하는데 중요한 역할을 하는데 이 때 필드가 클수록 더 복잡한 특징을 추출할 수 있지만 출력 이미지의 해상도는 낮아진다.

AlexNet에서 VGGNet으로 발전하면서, 더 깊은 네트워크일수록 더 좋은 성능을 낸다는 것을 확인했다. 그렇다면 과연 층을 단순히 더 깊게 쌓으면, 항상 더 좋은 네트워크를 얻을 수 있을까? 물론 그렇지 않았다. 층을 깊게 쌓으면 쌓을수록 학습을 어렵게 만드는 문제들이 있었다.
- 기울기 소실/폭발(Gradient vanishing/exploding)
- 연산 복잡도 증가(Computationally complex)
- depth가 어느정도 깊어지면, 성능이 떨어지기 시작
Overfitting이 아닐까? → 기울기 소실/폭발로 인해 학습이 더 진행되지 않음
이러한 문제점들을 인식한 채로 새로운 네트워크 형태들이 등장하기 시작했다.
참고 : VGGNet 논문
GoogLeNet- Inception Module 을 여러 층 쌓는 형태를 제안한다.
- 하나의 층에서 다양한 크기의 필터를 사용하여 여러 측면에서에서 살펴본다(depth 확장이 아닌 수평 확장)
- 이 결과들은 모두 concatenation 하여 다음 층으로 넘겨주게 된다.
- 이 때, $1 \times 1$ conv를 한 번 적용해 채널 수를 줄여 계산 복잡도를 떨어뜨린다. 이를 병목(bottleneck) 층이라고 한다.
- $3 \times 3$, $5\times 5$ conv 직전 / pooling 연산 직후
- Inception Module 을 여러 층 쌓는 형태를 제안한다.
ResNet- 최초로 100개가 넘는 layer를 쌓음으로써, 더 깊은 layer를 쌓을수록 성능이 더 좋아진다는 것을 보여준 첫 모델이다. 또한, 인간의 지각 능력을 뛰어넘은 첫 모델이기도 하다.
- 계기
- 네트워크 깊이를 늘리다보면 어느 순간부터 정확도(accuracy) 감수가 포화 상태(saturated)에 이른다.
- 기존 인식(가설)
- 모델 파라미터가 너무 많아지면 overfitting 되어 training error가 더 적고 test error가 더 많은 결과가 나올 것이다.
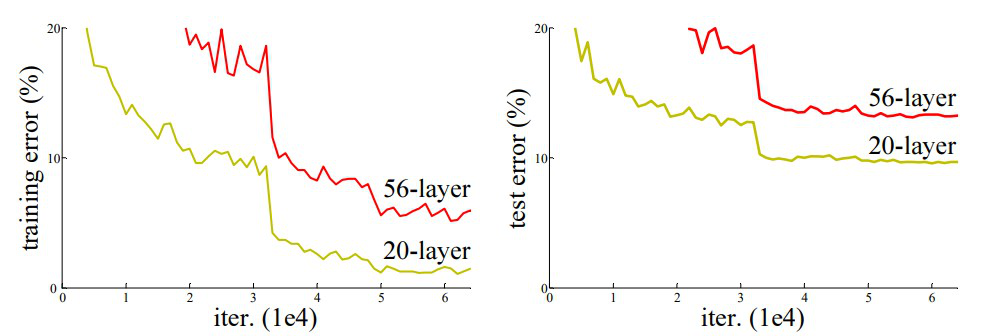
- 실험 결과
- overfitting 문제가 아니라, training error든 test error든 더 깊은 층(56)의 네트워크가 더 얕은 층(20)의 네트워크보다 에러 수가 높게 나온다.
- degradation 문제이다. 기울기 소실 때문에 최적화(optimization)이 덜 되어 깊은 층의 네트워크가 학습이 덜 된 것이다!
residual(skip) connection : 층이 깊어질수록 기존의 input x의 영향력(기울기)이 소실되어 충분히 학습하기 어렵다. 따라서, 몇 개의 층을 지나면 기존의 x와 동일한 값(identity)를 잔차(residual)에 더해주어, 잔여부분만 학습함으로써 학습 부담을 경감시킨다.

- 역전파 시에도 gradient가 원래 네트워크 레이어 쪽과 skip connection 쪽 두 군데로 흐르므로, 한 곳에서 기울기 소실이 일어나더라도 다른 한쪽을 통해 학습을 정상적으로 지속할 수 있게 된다.
- skip connection이 한번 일어날 때마다 역전파 gradient가 흐르는 방법의 경우의 수가 2배로 늘어나므로, 전체 경우의 수는 $2^n$ 개가 된다.
- residual block은 2개의 3x3 conv layer로 이루어져 있다.
- 출력 직전 FC 층은 하나만 존재한다.
참고 : ResNet 논문
EfficientNet- 기존에 네트워크 성능을 높이는 방법
- deep / wide / (high) resolution scaling
- high resolution scaling : 애초에 input 이미지의 resolution이 높으면 성능이 더 좋아진다.
- 그러나 세 방법은 각각 accuracy saturate의 시점이 다르다.
- deep / wide / (high) resolution scaling
- 그래서 세 방법 모두를 적절히 섞은 compound scaling이 등장한다.
- 지금까지 나왔던 모든 방식들을 대상으로, 적은 FLOP에서도 압도적인 성능차를 보였다.

- 기존에 네트워크 성능을 높이는 방법
참고: Modern Convolutional Neural Networks
Vision Transformers
Vision Transformers(ViT)는 자연어 처리에서 뛰어난 성능을 보인 Transformers에서 영감을 받아서 고안된 모델이다.

ViT는 트랜스포머 구조에서 Encoder 구조만 사용한다. 자연어 처리에서 사용하는 것처럼 이미지를 patches 단위로 만드는데, 이 patches를 tokens 라고 한다.
이 토큰들을 linear projection layer 형태인 feature로 만든 후 positional encoding을 붙여서 transformer encoder의 입력값으로 사용한다.
transformer encoder는 self-attention 구조를 통해서 관계성을 학습하여 feature transformation이 일어나게 되고 이런 과정을 거쳐 나온 output이 MLP 입력으로 들어가 task(ex. classification) 작업 결과를 출력한다.
기존의 transformer와 가장 큰 차이점은 input 부분으로 이미지를 고정된 크기의 patches로 쪼갠다.
- $x \in \mathbf{R}^{H \times W \times C} \rightarrow x_p \in \mathbf{R}^{N \times (p^2 \cdot C)}$
- $(H, W)$ : 원본 이미지 사이즈
- $C$ : 채널 개수
- $(P, P)$ : 각각의 이미지 patch의 사이즈
- $N = HW / P^2$ : patches의 개수
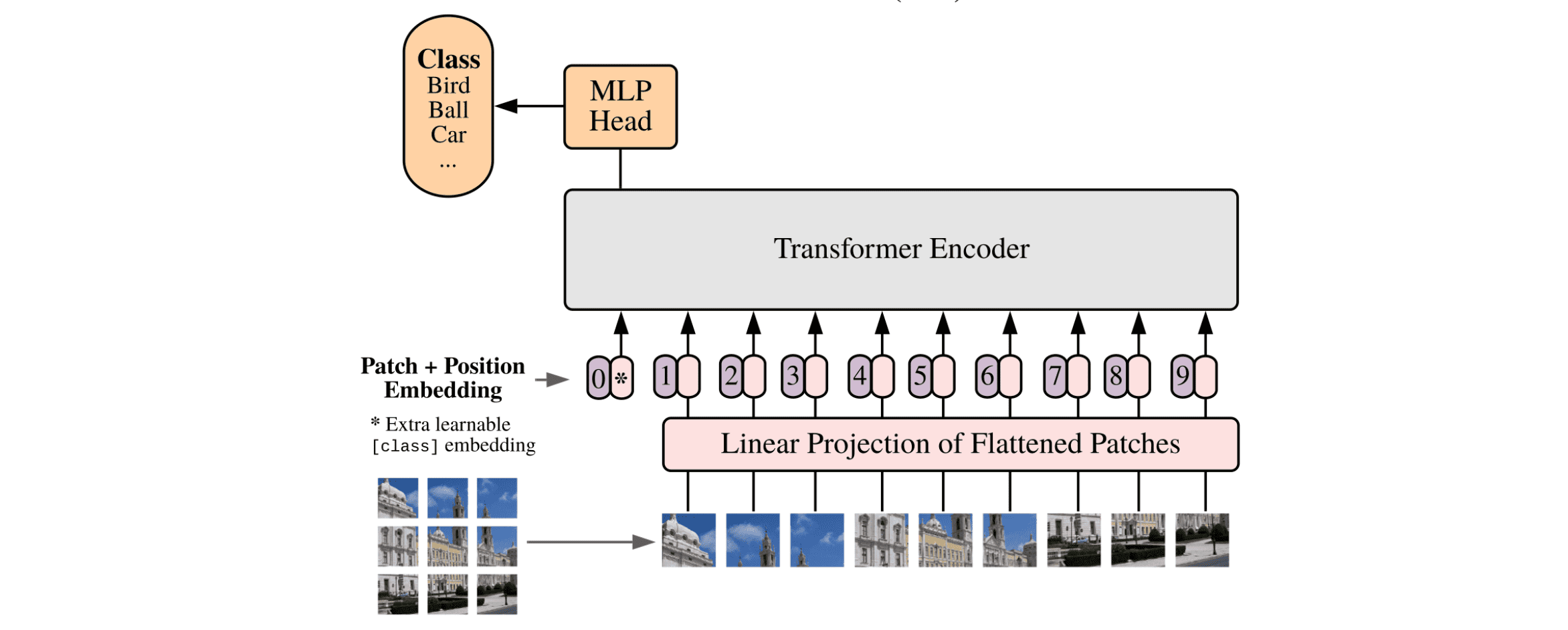
위의 그림에서 자세히 살펴봐야 하는 것은 transformer encoder의 입력 중 맨 처음 입력값이다.
이 값은 classification token(CLS) 으로 처음 입력될 때는 초기화된 상태로 입력되고 이후, 이미지 패치들과 함께 self-attention을 거치면서 전체 이미지를 요약하는 전역 표현을 학습한다. 마지막 레이어에서 이 토큰은 이미지 전체 정보를 대표하는 벡터가 되어, 최종적으로 분류 헤드(MLP)의 입력으로 사용된다.
즉, CLS 토큰은 단순한 입력이 아니라 ‘이미지 전체를 대표하는 요약 정보’를 담아 분류에 직접 활용되는 핵심 요소입니다.”
이때, 입력된 토큰 개수만큼 출력값이 나오는데 CLS 토큰으로 인한 출력 외의 토큰들은 사용하지 않는다.
참고 : ViT 논문
Scaling law
Scaling law란 모델의 크기와 데이터의 크기가 클수록 모델의 성능이 좋아지는 법칙을 의미한다.
주의할 점은 모든 모델에 한해서 만족하는 것은 아니지만, Transformers는 scaling law를 따르는 모델이다.
이러한 결과를 통해 ViT도 실험을 한 결과 마찬가지로 Scaling law를 따른다.
Swin Transformer
ViT는 자연어 처리에서 사용된 Transformers를 가져와 설계한 모델이기 때문에 이미지 데이터의 특성을 제대로 사용하지 못한 모델이다.
이후에, ViT의 단점을 보완한 이미지 데이터의 특징을 잘 사용한 Transformer 모델을 개발하였다.
대표적인 모델로 Swin Transformer 모델이 있다.
Swin Transforemr는 입력을 고해상도 patches로 구성하지만, 블럭들을 나눠서 그 블럭 내에서만 Attention을 수행하는 구조이다. 따라서, 해상도가 높아도 window 내에서만 Attention이 계산되어서 매우 효율적인 계산 복잡도를 가진다.
그리고 layer가 올라갈수록 계층적인 구조로 구성이 되서 영상의 전체적인 맥락을 파악하기 좋은 피라미드 구조로 구성되었다.
또한 각각 layer마다 가지고 있는 특징을 활용해 다른 task를 수행할 수 있다.
- 맨 위 layer : classification
- 중간 layer : segmentation
Swin Transformer는 정보가 지엽적으로 국한되어있는 것을 막기 위해 다음 layer에서는 window의 정의를 shift한다.
Self-supervised training
Transformers 이후부터는 모델의 세부적인 구조보다는 좋은 아키텍처를 이용해 데이터의 양을 늘려 모델의 성능을 늘리는데 좀 더 집중하기 시작했다.
데이터를 늘리기 위해 수집하는 과정 속에서 문제점이 있다. 적용하려는 일상 데이터가 supervised data 형태로 주어지지 않는다는 점이다.
이러한 현실적 문제로 인해 거대 모델을 학습할 때 self-supervised training 기법을 이용한다.
self-supervised training 으로 여러 기법이 있지만 그 중에서 transformers와 잘 어울리는 Masked Autoencoders(MAE) 가 있다.
Masked Autoencoder(MAE)
작동 과정은 다음과 같다.
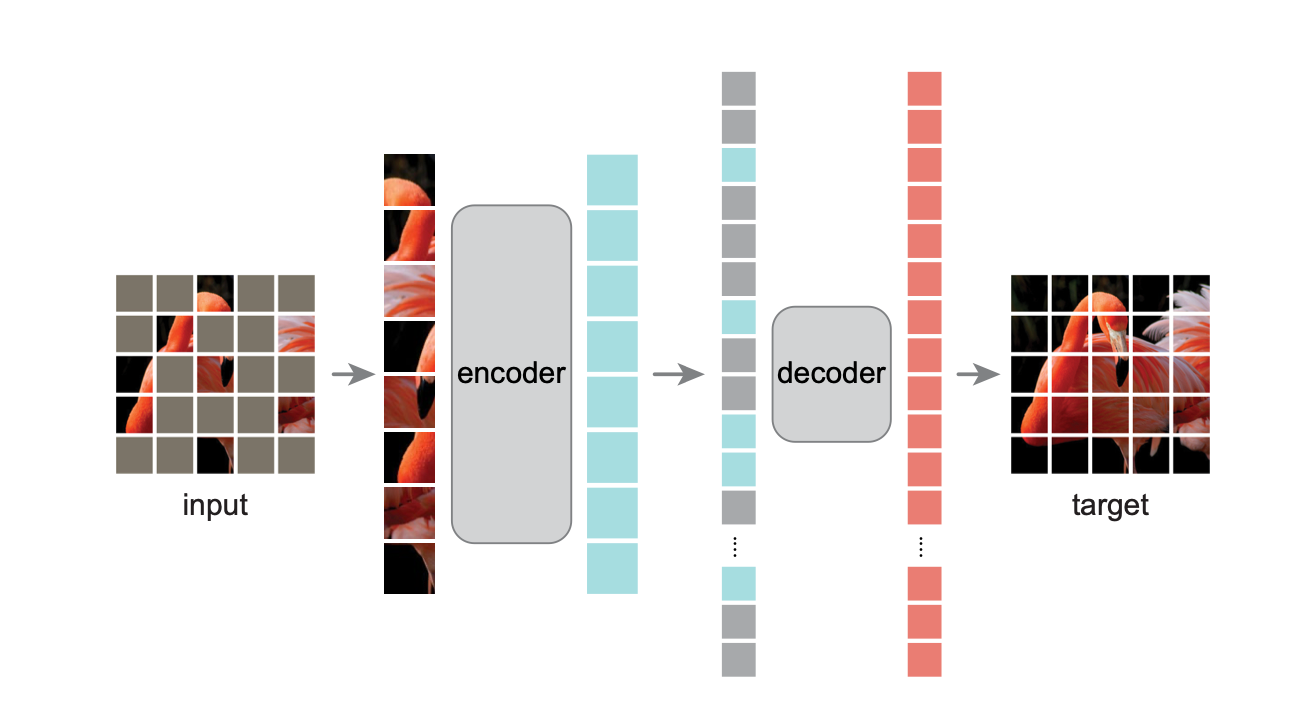
- training을 할 때 input data의 token의 일부를 masking한 뒤 학습을 진행한다.
- econder는 나머지 데이터를 가지고서 self-attention을 하여 효율적으로 feature encoding이 가능하다.
- 위의 출력 결과에 1에서 masking한 token들과 도입하여 decoder의 입력으로 사용한다.
- decoder는 masking한 부분들을 다시 복원하는 형태로 학습한다.
이를 통해, self-supervised training은 관찰되지 않는 부분을 어떻게 생겼는지 주변의 정보를 가지고 생성하는 task를 수행함으로써 visual 데이터의 구성과 생성의 메커니즘에 대한 학습 방식이라고 할 수 있다.
DINO
Transformers에 사용되는 또 다른 self-supervised training으로 DINO가 있다.
DINO는 student-teacher 네트워크 형태로 이루어진 label이 없는 self-distillation Framework 이다.
self-distillation: 하나의 네트워크를 이용하며, 이미지 1개를 데이터 증강(random, rotation)등을 통해서 2개로 만들고, 서로 다른 지식을 일치시키는 방법을 사용한다.즉, 하나의 네트워크를 사용하며, 서로 다른 이미지(ex. 원본 이미지를 crop하여 증강)를 추론했음에도 분포가 같아야하는 모델 일반화가 더 잘되는 방법으로 학습을 유도합니다.

작동 방식은 다음과 같다.

- input을 서로 다른 $x_1$과 $x_2$로 만든다(random transformation).
- data augmentation이라고 볼 수 있음
- $x_1$ 은 student network에 $x_2$는 teacher network의 입력으로 사용한다.
- student network와 teacher network는 같은 architecture 이지만 파라미터는 다르다.
- teacher : 이전에 학습된 좋은 모델
- student : 이번에 학습하는 모델
- 각각의 모델에 대한 출력을 뽑은 후 이 둘의 similarity를 측정하면서 학습을 진행한다.
- 이 때, student 모델만 학습을 하고 teacher 모델은 학습을 하지않는다.
- 학습 하지 못하도록 teacher 모델에
Stop-gradient(sg)걸게하고 student 모델을 출력 $p_1$이 teacher 모델의 출력 $p_2$를 따라가게끔 한다.
- 위의 과정처럼 학습을 한 후
exponential moving average(ema)라는 기법을 통해 기존의 teacher 모델과 studnet 모델을 blending하여 teacher 모델을 업데이트한다. - 새로운 student 모델을 가져와 위의 학습 과정을 진행한다.
DINO 모델을 세부적으로 보면 teacher의 ouput에 centering 이라는 작업을 수행한다. 이 작업은 teacher의 ouput의 특징들을 가운데로 nomalization하고 collapse를 없애주기 위해 진행한다.
centering wkrdjqdms 평균값을 output에서 빼주는 형태로 진행한다.
이외에도 sharpening도 진행한다. 이 기법은 하나의 값으로 매핑되는 것을 막아주기 위해 temperature $T$를 줌으로써 출력값을 증폭해주는 역할을 한다.
- $T$ 값이 커지게 되면 완만한 probability 값이 나온다.
- $T$ 값이 작아지면 튀는 probability 값이 나온다.
정리하면 DINO는 다양하고 많은 데이터로 학습을 하여 label 없이도 pre-training을 하여 target task의 부담을 줄여줄 수 있다.
이 글은 비밀번호로 보호되어 있습니다.