Attention 구조를 이용해서 Transformer 라는 모델을 구현할 수 있다.
하지만 다음과 같이 아직 해결되지 않은 질문들이 존재한다.
- input과 ouput 모두 sequence 형태이다. 하지만 수행하려는 task는 분류(classification) 또는 회귀(regression)와 같은 작업들이다.
- Transformer model을 학습시키고 모델의 prediction을 Ground Truth와 어디서 비교하고 Loss는 어디서 어떻게 구하는가?
- RNN과 다르게 token의 순서가 무시된다. 이를 어떤 방식으로 모델링 할 수 있을까?
이 질문들의 답을 구하고 좀 더 자세히 Transformer 구조를 살펴보자.
Token Aggregation
분류(classification) 또는 회귀(regression)와 같은 task를 수행하는 방법으로는 여러 방법이 있다.
Average Pooling
수행하려는 task가 분류(classification) 또는 회귀(regression)와 같은 작업을 할 때 가장 간단한 작업은 바로 평균을 구하는 것이다.
- transformers에서 나온 revised token embeddings ${ z_1^{(L)}, \ldots, z_N^{(L)}}$ 전체에 대해서 평균을 취하면, 전체 Input에 대한 single embedding $z$를 얻게 된다.
- 위에서 얻은 값을 가지고 classifier 나 regressor 모델을 훈련시킬 수 있다.
만약, 시퀀스가 매우 길지 않고 relatively homogeneous한 경우 평균을 구하는 것이 효과적이지 않은 경우는 MLP를 사용할 수도 있다.
Classification Token
또다른 방법으로는 attention mechanism 에 의존하는 것이다.
- 집계된 embedding은 시퀀스 내에서 정보를 제공하는 부분만 선택적으로 attend하도록 훈련된다.
- 그러나 $z_i$는 token $i$와의 관련성을 기반으로 계산되므로, 각 $z_i$는 전체 sequence가 아닌 특정 $x_i$를 나타낸다.
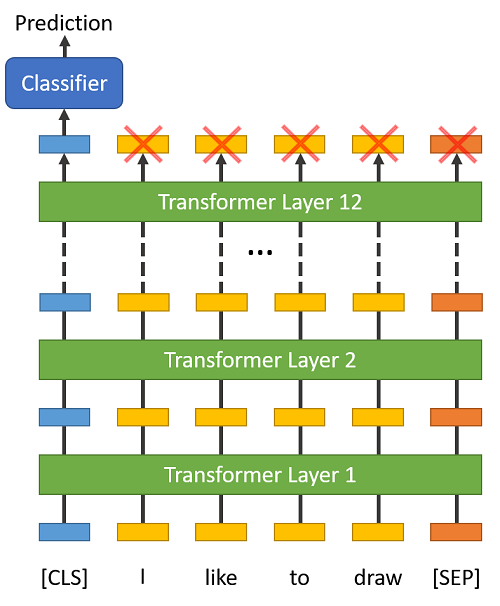
전체 시퀀스의 특징을 나타내기 위해 고안한 방법이 바로 더미 토큰 classification token; [CLS] 를 이용하는 것이다.
CLS 를 입력 시퀀스에 추가하여 이를 embedding으로 사용한다.- 더미 입력은 어떤 의미도 전달하지 않기 때문에 특정한 토큰에만 치우치지 않는다.
CLS에서 나온 출력을 classifier/regressor의 입력으로 사용한다.
실제로 CLS token을 사용하는 방법을 훨씬 많이 사용한다.
- 마지막 레이어의 output embedding에는 classifier 또는 regressor를 배치한다.