[BoostCamp AI Tech / ML LifeCycle] 선형대수: Linear Classifier and Softamx Classifier
Linear Classifier의 개념과 한계, Softmax와 Sigmoid 개념 그리고 Loss Function과 최적화 개념 및 방법에 대한 내용을 정리한 포스트입니다.
Linear Classifier
입력(이미지 $x$)을 레이블 점수(클래스 $y$)에 매핑하는 함수 $f$를 말한다.
매개변수적 접근
이때 Function $f$는 입력 픽셀의 가중치 합계를 가지고 있여야 한다.
- $W_{1, 1}x_{1, 1} + W_{1, 2}x_{1, 2} + \ldots + W_{M, N}x_{M, N}$
이떄, $W$ 파라미터는 클래스 개수만큼 가지고 있다.
그리고, 각 클래스가 올바른 이미지에 대해 가장 높은 점수를 받도록 $W$의 값을 결정해야한다. 이 값들 중 가장 높은 점수가 나온 클래스로 매핑한다.
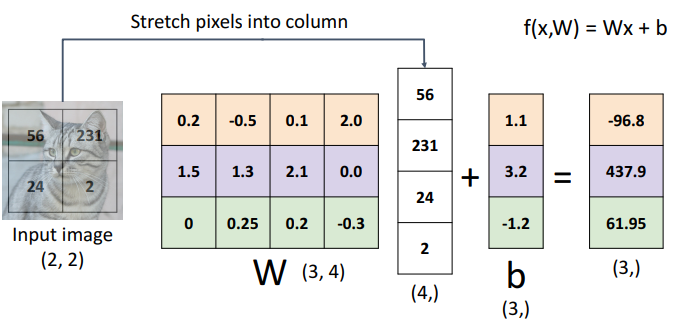
ex. 이미지 분류에 대한 각 변수의 차원
\[f(x, W) + Wx + b\]- 이미지 $x$ : $32 \times 32 \times 3 = 3072$
- 레이블 10개
- $f(x, W)$ : $10 \times 1$
- 각 클래스별로 10개의 독립적인 classifier
- $x$ : $3072 \times 1$
- $W$ : $10 \times 3072$
- 가중치 혹은 파라미터
- $b$ : $10 \times 1$
- 편향(bias)는 데이터 $x$와 상호 작용하지 않고 출력에 영향을 미친다.
- 데이터가 특정 클래스에 쏠여있을 때, 이를 반영하여 값을 설정함으로써 가중치 $W$가 데이터 자체에 더 집중할 수 있도록 하는 역할을 한다.
이를 수식으로 표현하면 다음과 같다.
\[f(x, W) = Wx + b = [W \ \ b] \begin{bmatrix} x \\ 1 \end{bmatrix}\]매개변수적 모델의 장점은 다음과 같다.
- 학습이 완료되면 가중치 $W$만을 필요로 합니다. 방대한 학습 데이터 셋을 저장할 필요가 없습니다.
- 공간 효율성이 높습니다.
- 테스트 시 단일 행렬-벡터 곱($Wx$)으로 예제를 평가할 수 있습니다.
- 모든 훈련 데이터와 비교하는 것보다 훨씬 빠릅니다.
기하학적 관점
- 각 선형 바운더리는 $W$의 해당 행에서 나온다.
- $W$의 값이 변경되면 해당 decision 바운더리가 회전한다.
- $b$가 변경되면 해당 decision 바운더리가 위/아래로 이동한다.
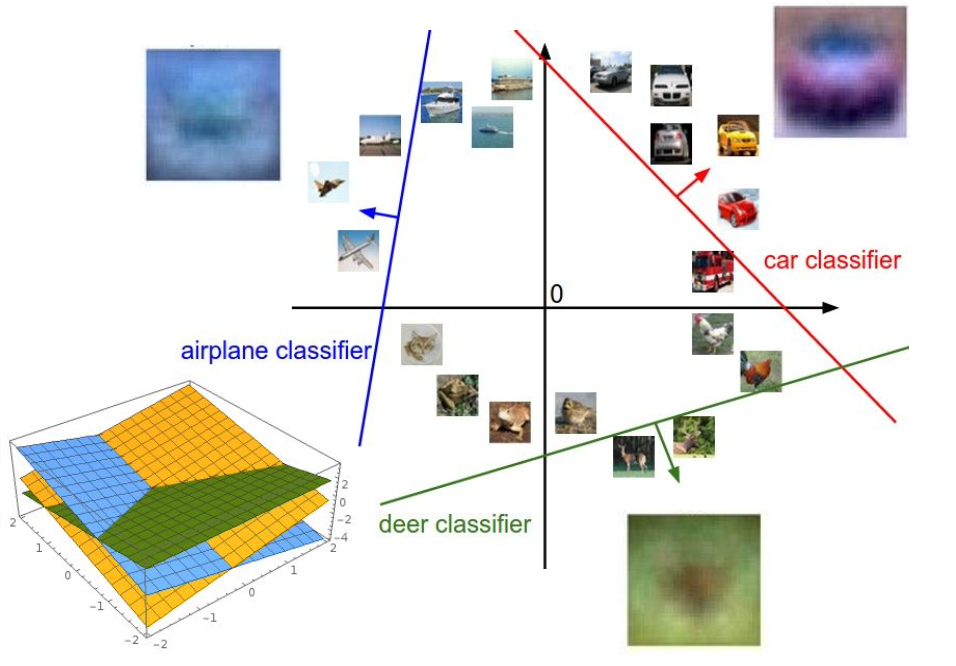
시각적 관점
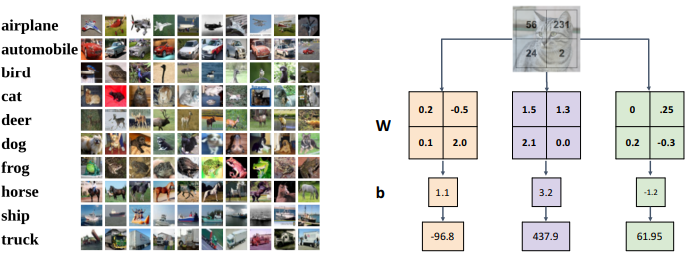
Linear Classifier가 하는 일은 아래와 같다.
- 훈련 시: 훈련 데이터에서
템플릿 학습 - 테스트 시: 새로운 예제로
템플릿 매칭
둘 다 거리를 비교한다는 점에서 kNN과 비슷하지만, 선형 분류기는 K개의 클래스만 비교하는 반면 kNN은 N개의 훈련 예제와 비교한다는 점에서 차이가 있다. (일반적으로 K « N)
ex. K = 10이면, 테스트 데이터가 들어왔을 떄 10개의 클래스만 비교하면 된다. 반면, NN Classifier은 모든 훈련 데이터와 비교를 해야한다.
Softmax Classifier
Linear Classifier은 결과값의 제한이 없으며 그 점수가 의미하는 것이 무엇인지를 해석하기 어렵다.
그러므로 0과 1 사이의 경계 점수를 얻어서 확률로 해석할 수 있다면 의미하는 바가 더 뚜렷해질 것이다.
점수는 아래와 같이 의미를 해석할 수 있다.
ex. 이미지가 각 클래스에 속할 확률에 대해 정의해 보겠습니다.
- 2개의 클래스가 있다고 가정
- $s_1 > s_2$라면: 해당 이미지가 클래스2보다 클래스1에 있을 확률이 높다.
- 클래스 간 갭$(s_1 -s_2)$이 더 클수록, $x \in c_1$일 확률이 더 높다.
반대의 경우도 마찬가지입니다.
- $s_2 - s_1$이 클수록 $x \in c_2$일 가능성이 높습니다
이를 함수로 만든 함수가 sigmoid 함수이다.

- $p(y = c_1 | x) = \frac{1}{1 + e^{-(s1-s2)}}$
- $p(y = c_2 | x) = \frac{1}{1 + e^{-(s2-s1)}}$
클래스가 $n > 2$ 인 경우에 대해서도 일반화하면
\[p(y=c_i|x) = \frac{e^{s_i}}{e^{s_1} + e^{s_2} + \ldots + e^{s_n}} = \frac{e^{s_i}}{\sum_{j} e^{s_j}}\]이 함수를 softmax function이라고 한다.
가중치 설정 방법
- 모델의 형식($f(x,W) = Wx$)을 디자인하고 랜덤하게 매개변수($W$)의 값을 설정합니다.
- 그 후, 학습 데이터 $x$를 입력해 라벨 $\hat{y}$ 을 예측한다.
- 추정값 $\hat{y}$ 을 기준값 라벨 $y$와 비교하여 현재값이 얼마나 좋은지/나쁜지를 비교한다(손실함수)
- 손실값에 따라 매개변수($W$)를 업데이트하는데 이를
최적화라고 한다. - $\hat{y} ≈ y$ 가 될 때까지 이 과정을 반복한다.
손실함수
손실함수는 해당 머신 러닝 모델이 얼마나 좋은지, 혹은 나쁜지를 정량화한다.
추정값 $\hat{y}$ 와 기준값 레이블 $y$ 에 해당하는 함수: $\mathcal{L}(\hat{y}, y)$
$\hat{y}$ 과 $y$ 가 어떻게 다른지에 따라 모델에 페널티를 주는 양수를 출력한다.
- $\hat{y} = y$ 인 경우 모델에 패널티를 주고 싶지 않으므로 손실은 (약) 0이 되어야 한다..
- $\hat{y} \approx y$ 인 경우 모델에 패널티를 주어 미세 조정할 수 있다.
- $\hat{y}$ 와 $y$ 사이의 격차가 크면 크게 패널티를 주어야 한다.
차별적(Discriminative) 설정
이진 분류의 경우, 기준값(ground truth)은 $y = {+1, -1 }$ 이다.
- 모델은 하나의 점수 $\hat{y} \in \mathbb{R}$ 를 예측한다.
- $\hat{y}$ 이 0보다 크면 포지티브 클래스로, 그렇지 않으면 네거티블 클래스로 분류한다.
마진 기반 손실- 손실은 $y\hat{y}$ 에 따라 결정된다.
- 부호가 같으면(즉, 분류가 정확하면) 손실이 작아지거나 0이 된다.
- 부호가 다르면(잘못된 분류) 손실이 커진다.
- $y\hat{y}$ 의 값의 절댓값이 커질수록 모델이 확실하게 예측했다라고 판단할 수 있다.
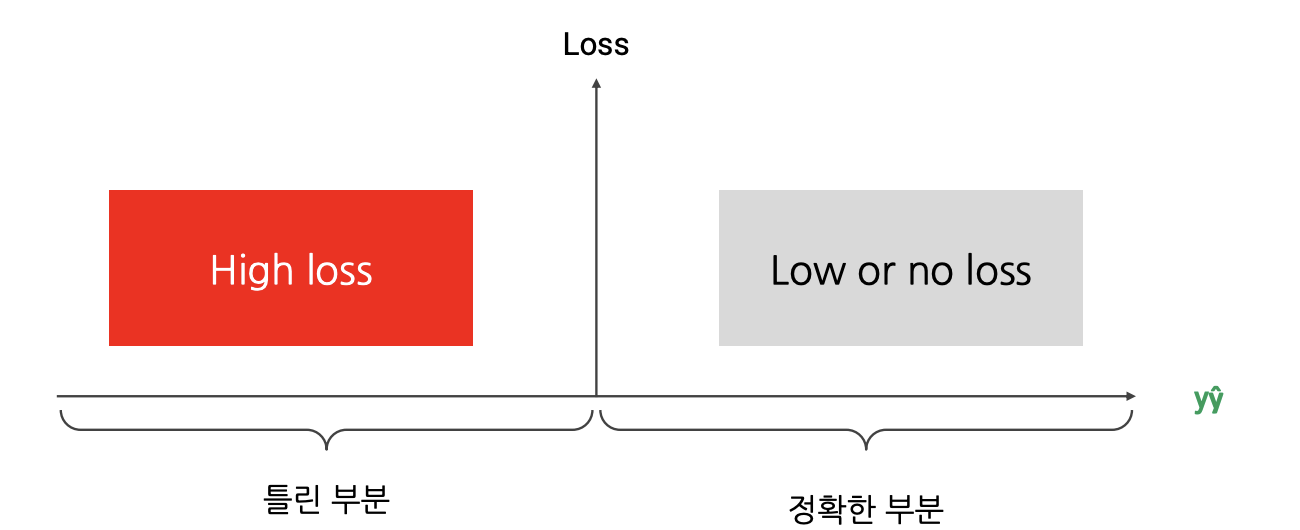
마진 기반 손실
마진 기반 손실 방법을 가지고 손실 함수를 구현한 것으로 unit function이 있다.
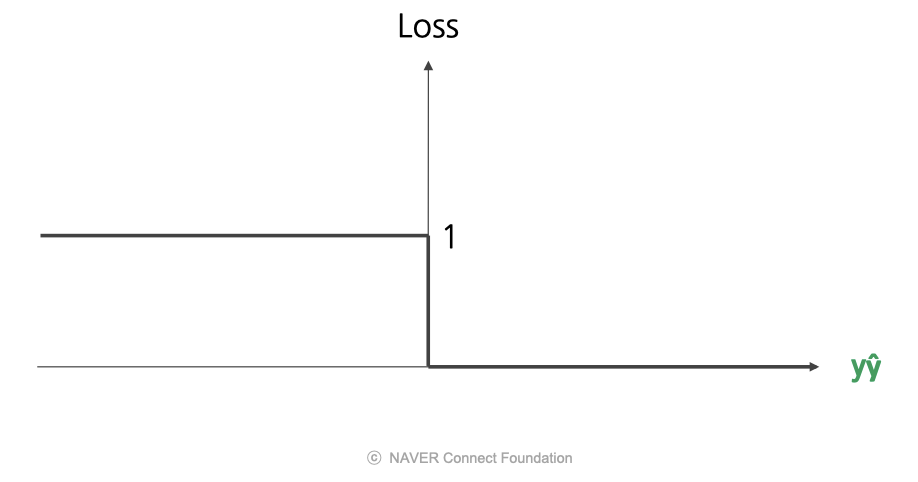
- $y\hat{y}$ 이 양수일 경우, 맞는 예측이므로 손실은 0을 줌.
- $y\hat{y}$ 이 음수일 경우, 틀린 예측이므로 손실은 1을 줌.
- 장점: 단순함
- 단점: $y\hat{y}$ 인 지점에서 미분 불가
이를 보완한 것이 로그 손실이다. 이 함수는 연속함수이기 때문에 어느시점에서는 미분 가능하다.
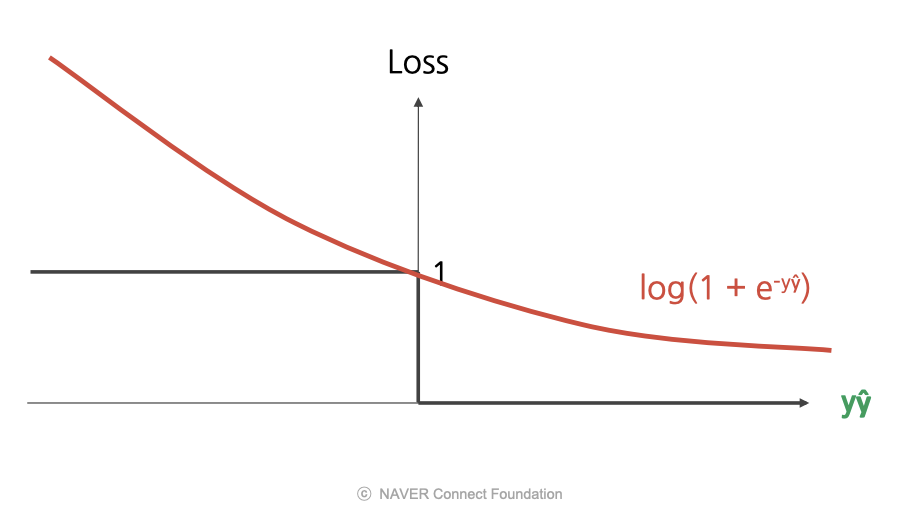
- $y\hat{y}$ 이 양수일 경우, 맞는 예측이므로 손실을 적게 줌.
- $y\hat{y}$ 이 음수일 경우, 틀린 예측이므로 손실을 크게 줌.
- 즉, 예측이 정확할수록 페널티가 작아짐.
- 장점: 연속 함수이므로 모든 지점에서 미분 가능하며, 출력을 $P(y|x)$ 로 볼 수 있어 해석이 쉬움.
로그 손실과 유사하지만 더 극단적인 형태로, 지수 손실이 있다.
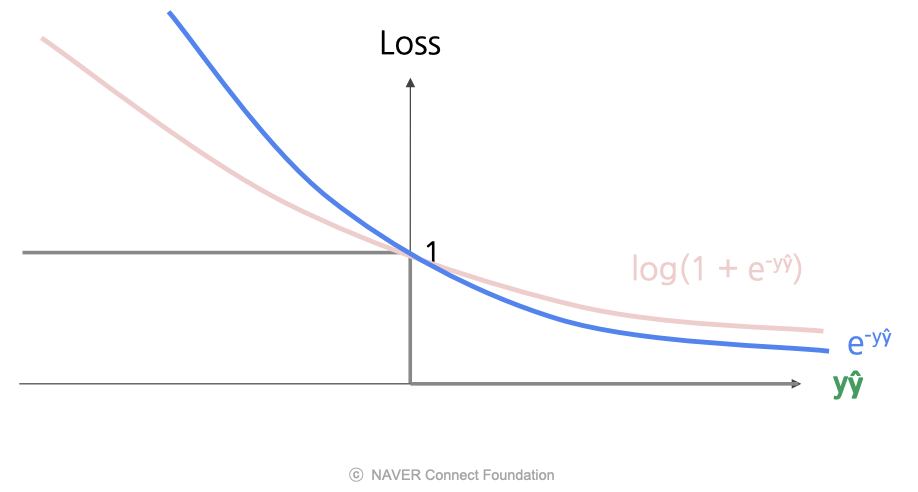
- 로그 손실의 곡선보다 가파르며 잘못된 경우에는 더 엄격하게 페널티를 주고, 올바른 경우에는 적은 페널티를 준다.
- 장점: 로그 손실과 마찬가지로 모든 지점에서 미분 가능
- 단점: Outlier에 매우 큰 손실을 할당하므로 Outlier의 영향을 강하게 받음(→ 노이즈가 많은 data에 적합 X)
또다른 손실 함수로는 Hinge 손실(Hinge Loss)가 있다.
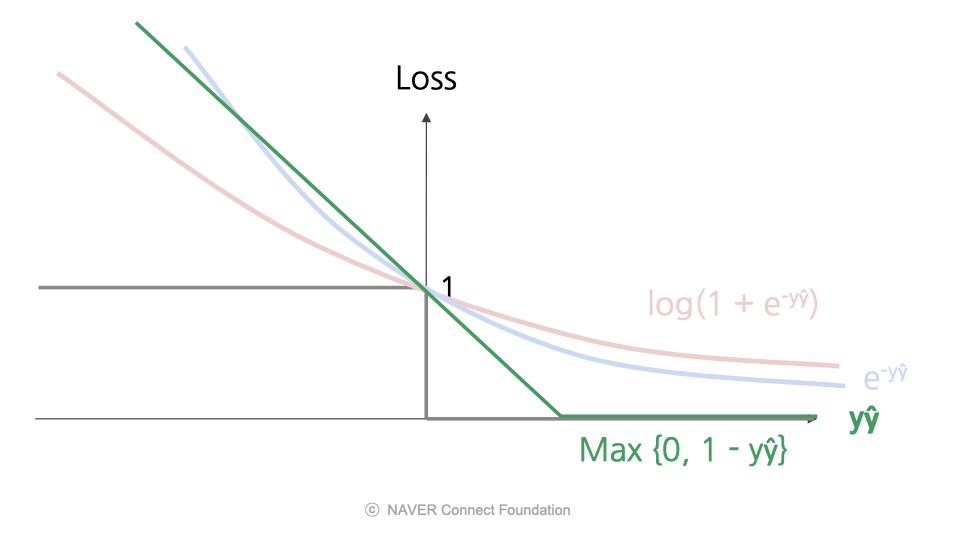
- 어느정도 자신있는 예측 + 맞는 예측 → 손실을 주지 않음.
- 자신없게 예측 or 틀린 예측 → 손실을 줌.
- 즉, 오류에 대한 페널티가 선형적으로 증가하며, 오차 범위 내에서 정답인 경우에도 약간의 페널티를 받음.
- 장점: 계산적으로 효율적임. (미분값이 0 혹은 1이라 미분을 하지 않아도 되므로)
널리 사용하는 손실함수는 Hinge 손실과 Loss 손실이다.
확률적 설정
실제 딥러닝에서는 확률적 설정을 사용한다.
이진 분류 문제에 대하여, 기준값은 $y = { 0, 1 }$입니다.
- 이 모델은 한 클래스의 확률인 하나의 점수 $\hat{y}$ 를 예측이다.
- 다른 클래스의 확률은 $1 - \hat{y}$ 이다.
- 점수 차이에 시그모이드 함수를 적용하는 것이 좋다.
$K > 2$ 클래스에서는 다음과 같다.
- 기준값은 1열 벡터로 표현: $y = [0, 0, 0, 0, 1, 0, 0]$
- 모델은 $K - 1$ 점수를 예측하고 마지막 점수를 ‘1 - 합계’로 남긴다.
소프트맥스를 사용하며 예측값이 0에서 1 사이이고 합계가 1이다.
이 설정에서 손실 함수는 기본적으로 두 개의 (GT와 예측) 확률 분포를 비교한다.
Cross Entropy
일반적 정의는 아래와 같다.
\[\mathcal{L} = -\frac{1}{N} \sum_{i=1}^{N}\sum_{k=1}^{K} y_{ik} \ log \ (\hat{y}_{ik})\]이진 정의는 다음과 같다.
\[\mathcal{L} = -\frac{1}{N} \sum_{i=1}^{N} [y_i log \ (\hat{y}_i) + (1 - y_i)\ log \ (1 - \hat{y}_i)]\]위의 수식을 분석을 해보자.
모든 클래스(K)에 걸쳐 합산하더라도 단 하나의 k에 대해 $y_{ik}=1$ 이 있으므로 한 항만 남는다.
- $y_i = 0$ 인 경우 : $\mathcal{L} = -\frac{1}{N} \sum_{i=1}^{N} [0 \ log \ (\hat{y}_i) + (1 - 0) \ log \ (1 - \hat{y}_i)]$
- $y_i = 1$ 인 경우 : $\mathcal{L} = -\frac{1}{N} \sum_{i=1}^{N} [1 \ log \ (\hat{y}_i) + (1 - 1) \ log \ (1 - \hat{y}_i)]$
즉, 이를 간단히 하면 아래와 같이 수식으로 표현할 수 있다.
\[\mathcal{L} = -\frac{1}{N} \sum_{i=1}^{N} log \ (\hat{y}_i T_i) \ \ \ T_i \text{: ground truth index}\]위의 수식은 모든 샘플에 대한 $-log(\text{“올바른 클래스에 대한 예측 확률”})$ 의 합계이다.
[0, 1] 구간에서 $-log \ (x)$ 는 0에 가까워질수록 $\infty$로 향하며 1에 가까워질수록 0에 가까워진다.
이를 활용하면 추정치가 1에 가까우면 손실이 0에 수렴하고, 0에 가까워지면 손실이 증가한다.
Kullback - Leibler(KL) 발산
두 개의 확률분포가 있을 때, 확률분포의 유사성을 측정하는 metric이다.
\[D_{KL}(P || Q) = \sum_{i} P(i) \ log \ \frac{P(i)}{Q(i)}\] \[D_{KL}(P || Q) = \int_{} P(i) \ log \ \frac{P(i)}{Q(i)} \ dx\]구성요수는 아래와 같다.
- 비대칭 : $D_{KL}(P | | Q) \ne D_{KL}(Q | | P)$
- $D_{KL}(P | | Q) \ge 0$
- 항상 삼각형 부등식을 만족하지는 않는다.
최적화
최적화(optimization)는 가중치를 업데이트하는 과정을 의미한다.
- 최적의 가중치 $W$ 및 편향 $b$를 찾는 과정
- 손실 함수 $L(\hat{y},y)$ 의 값을 최소화하는 파라미터를 구하는 과정
- 예측값 $\hat{y}$ 과 실제값 $y$ 의 차이를 최소화하는 네트워크 구조와 파라미터를 찾는 과정
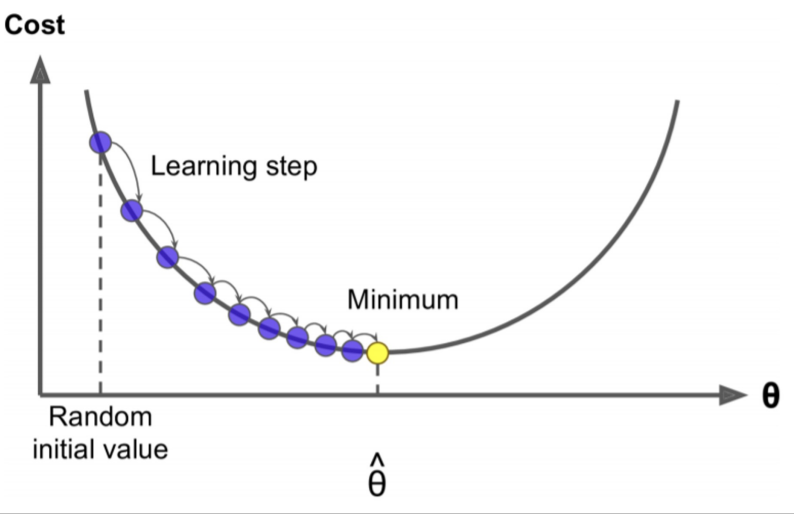
경사하강법(Gradient Descent)
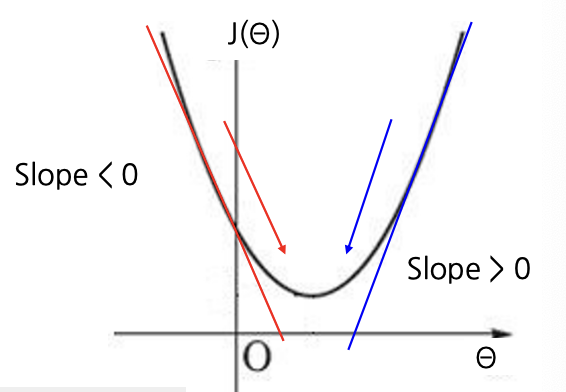
최소화하고자 하는 비용 함수 $J(\theta)$가 있다.
- $\theta$ 의 현재 값에 대해 $J(\theta)$ 의 기울기를 계산한 다음 음의 기울기 방향으로 작은 단계를 밟고, 이를 반복한다.
- 한 지점에서 함수의 기울기(또는 미분)는 해당 지점에서 함수에 대한 가장 좋은 선형 근사치이다.
이를 수학식으로 표현하면 다음과 같이 표현할 수 있다.
- 업데이트 방정식(벡터 표기법)
- 업데이트 방정식(단일 매개변수)
1
2
3
4
5
6
theta = rand(vector)
while True:
theta_grad = evaluate_gradient(J, data, theta)
theta = theta - alpha * theta_grad
if norm(theta_grad) <= beta:
break
그레디언트 경사하강법에도 한계가 있다.
- Local Minimum에 빠지기 쉽다.
- Saddle Point(안장점)을 벗어나지 못할 수 있다.
- 손실 함수가 미분 불가능하면 사용할 수 없다.
- Global Minimum으로 수렴하는 속도가 상당히 느릴 수 있다.
- 모든 데이터셋을 계산하여 결정을 내려야하기 때문에 많은 연산량이 요구된다.
Stochastic Gradient Descent
- 모든 훈련 예제에 대해 그라데이션을 계산하는 대신 무작위로 샘플링된 하위 집합에 대해서만 수행합니다.
- 가장 극단적인 경우는 모든 샘플에 대해 파라미터를 업데이트하는 것입니다.
- 가장 일반적인 방법 : 32, 64, 128, 256, …, 8192 크기의
미니 배치로 수행하는 것입니다.- 최적의 크기는 문제, 데이터 및 하드웨어(
메모리)에 따라 다릅니다.
- 최적의 크기는 문제, 데이터 및 하드웨어(
- 미니 배치가 작을 때, 두 배로 늘리면 기울기 추정이 훨씬 안정적이지만, 파라미터 업데이트하는데 오랜 시간이 걸린다.
이 글은 비밀번호로 보호되어 있습니다.