[BoostCamp AI Tech / Product Serving] Batch Serving과 Airflow
Batch Serving 개념과 이를 구현하기 위한 핵심 워크플로우 관리 도구 Apache Airflow에 대한 내용을 정리한 포스트입니다.
Batch Serving은 일정 기간 데이터 수집 후 일괄 학습 및 결과 제공하는 특성이 있으며 대량의 데이터 처리할 때 효율적이며 주로 모델을 주기적으로 학습시킬 때 사용하는 방법이다.
- 예측 코드를 주기적으로 실행해서 예측 결과를 제공
- Job Scheduler는 Apache Airflow를 주로 사용
- 학습과 예측을 별도 설정을 통해 수행
- 학습: 1주일에 1번
- 예측: 10분, 30분, 1시간에 1번씩
Batch processing
Batch processing 은 소프트웨어 프로그램을 자동으로 실행하는 방법으로 예약된 시간에 자동으로 실행하는 것을 의미한다.
🔎 Batch Processing과 Batch Serving의 차이
Batch Processing: 일정 기간 동안 일괄적으로 작업을 수행
Batch Serving: 일정 기간 동안 일괄적으로 머신러닝 예측 작업을 수행Batch Processing이 더 큰 개념이며, Batch로 진행하는 작업에 Airflow를 사용할 수 있다.
Crontab
Aifrlow 등장 전에는 대표적으로 Linux의 Crontab을 사용하였다.
- (서버에서) crontab -e 입력
- 실행된 에디터에서 0 * * * * predict.py 입력(0 * * * * 은 매 시 0분을 의미)
- OS에 의해 매 시 0분에 predict.py가 실행
- Linux는 일반적인 서버 환경이고, Crontab도 기본적으로 설치되어 있기 때문에 매우 간편
- 간단하게 Batch Processing을 할 때 Crontab도 가능한 선택
이 때 Cron 표현식을 활용하며 Batch Processing의 스케줄링을 정의한 표현식이다.
이 표현식은 다른 Batch Processing 도구에서도 자주 사용된다(Airflow에서도 사용).

Cron 표현식이 익숙하지 않을 때 참고할 사이트
Linux Crontab의 문제점이 있다.
- 재실행 및 알림
- 파일을 실행하다 오류가 발생한 경우, Crontab이 별도의 처리를 하지 않음
- ex. 매주 일요일 07:00에 predict.py를 실행하다가 에러가 발생한 경우, 알림을 별도로 받지 못함
- 실패할 경우, 자동으로 몇 번 더 재실행(Retry)하고, 그래도 실패하면 실패했다는 알림을 받아야 대응할 수 있음
- 과거 실행 이력 및 실행 로그를 보기 어려움
- 여러 파일을 실행하거나, 복잡한 파이프라인을 만들기 힘듦
Crontab은 간단히 사용할 수는 있지만, 실패 시 재실행, 실행 로그 확인, 알림 등의 기능은 제공하지 않기 때문에 좀 더 정교한 스케줄링 및 워크플로우 도구가 필요하다.
여러 도구가 등장했지만 이 중 가장 많이 사용하는 도구는 Airflow 다.
Apache Airflow
Airflow 등장 후, 스케줄링 및 워크플로우 도구의 표준이다.
- 에어비앤비(Airbnb)에서 개발했으며 2점대 버전이 존재. 업데이트가 매우 빠름
- 스케줄링 도구로 무거울 수 있지만, 거의 모든 기능을 제공하고, 확장성이 좋아 일반적으로 스케줄링과 파이프라인 작성 도구로 많이 사용
- 데이터 엔지니어링 팀, MLOps 팀에서 많이 사용
Airflow를 많이 사용하는 이유는 워크플로우 관리 도구로써 코드로 작성된 데이터 파이프라인 흐름을 스케줄링하고 모니터링하는 목적이다. 또한 데이터 처리 파이프라인을 효율적으로 관리하여 시간과 자원을 절약하도록 한다.
Airflow의 주요 기능은 아래와 같다.
- 파이썬을 사용해 스커줄링 및 파이프라인 작성
- 스케줄링 및 파이프라인 목록을 볼 수 있는 웹 UI 제공
- 성공/실패/진행 중 상태를 확인 가능
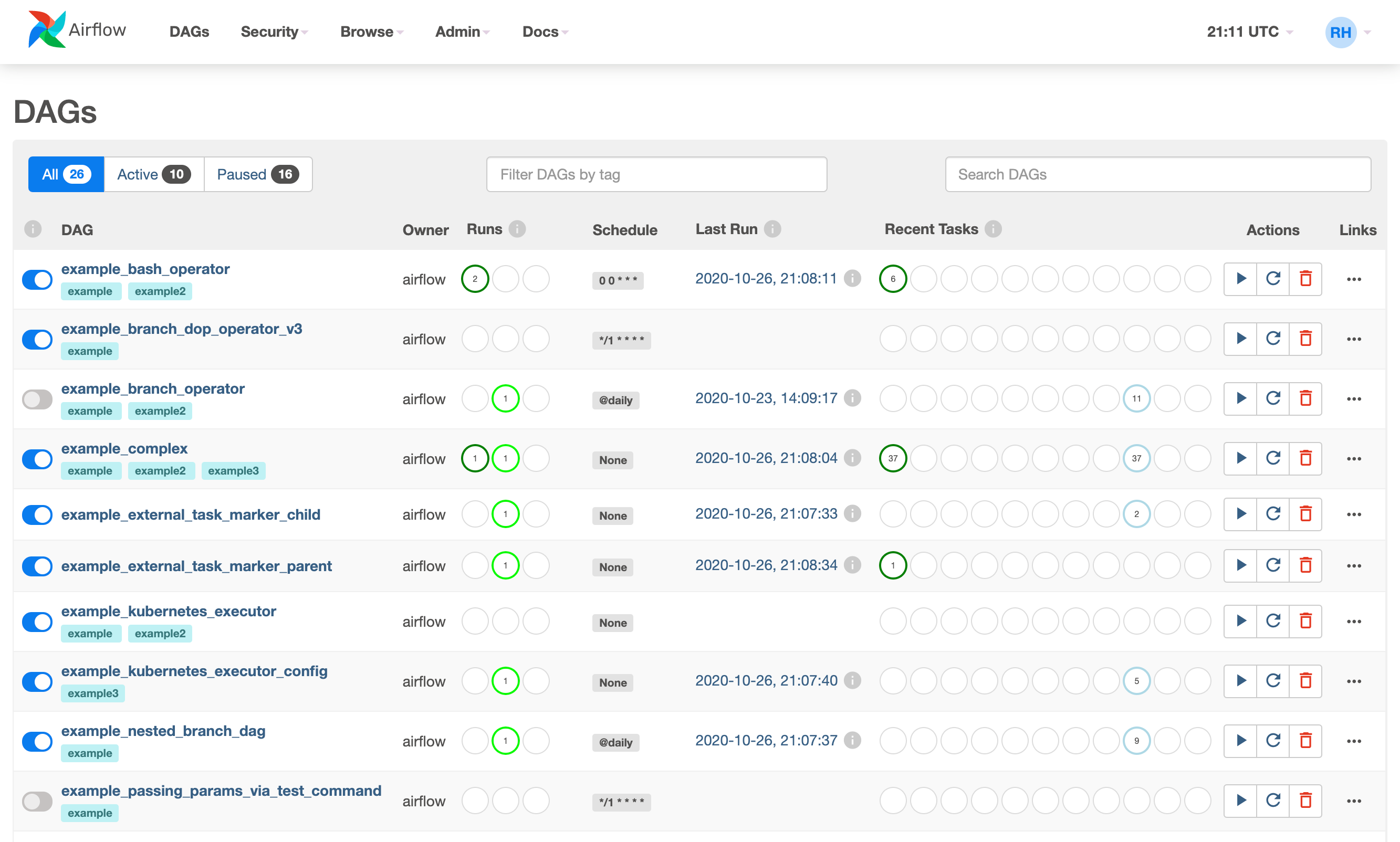
특정 조건에 따라 작업을 분기할 수도 있음(Branch 사용)

Airflow의 핵심 개념으로 4가지가 있다.
DAGs(Directed Acyclic Graphs)- Airflow에서 작업을 정의하는 방법, 작업의 흐름과 순서 정의
Operator- Airflow의 작업 유형을 나타내는 클래스
- BashOperator, PythonOperator, SQLOperator 등 다양한 Operator 존재
Scheduler- Airflow의 핵심 구성 요소 중 하나. DAGs를 보며 현재 실행해야 하는지 스케줄을 확인
- DAGs의 실행을 관리하고 스케줄링
Executor- 작업이 실행되는 환경
- LocalExecutor, CeleryExecutor 등 다양한 Executor가 존재
Airflow의 기본 아키텍처는 아래 그림과 같이 표현한다.
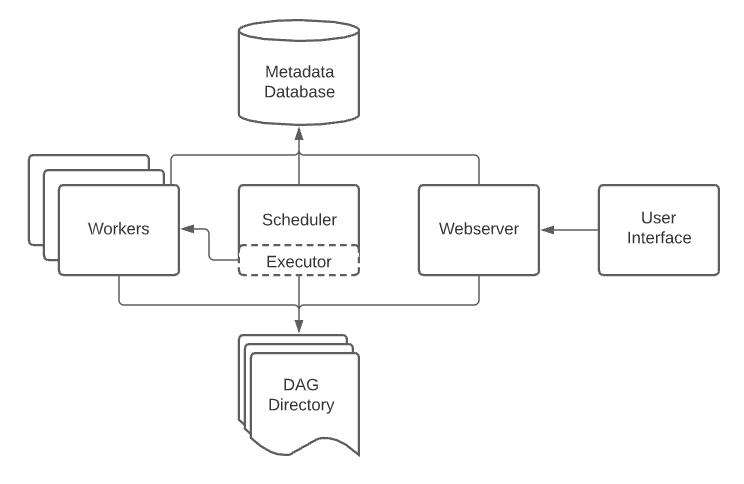
Airflow에서 Batch Scheduling을 위한 DAG 생성을 하는 과정은 다음과 같다.
먼저 Airflow에서는 스케줄링할 작업을 DAG이라고 부릅니다. DAG은 Directed Acyclic Graph의 약자로, Airflow에 한정된 개념이 아닌 소프트웨어 자료구조에서 일반적으로 다루는 개념이며 이름 그대로 ‘순환하지 않는 방향이 존재하는 그래프’를 의미합니다.
Airflow는 Crontab처럼 단순히 하나의 파일을 실행하는 것이 아닌, 여러 작업의 조합도 가능합니다.
DAG 1개 : 1개의 파이프라인
Task : DAG 내에서 실행할 작업
하나의 DAG은 여러 Task의 조합으로 구성되며, 이러한 DAG 파일들은 DAG Directory를 통해 물리적으로 관리됩니다.
DAG Directory- DAG 파일들을 저장
- 기본 경로는
$AIRFLOW_HOME/dags - DAG_FOLDER 라고도 부르며, 이 폴더 내부에서 폴더 구조를 어떻게 두어도 상관없음
- Scheduler에 의해 .py 파일은 모두 탐색되고 DAG이 파싱
Airflow DAG 작성
DAG 작성을 요약하자면 다음과 같다.
- AIRFLOW_HOME 으로 지정된 디렉토리에 dags 디렉토리를 생성하고 이 안에 DAG 파일을 작성
- DAG은 파이썬 파일로 작성. 보통 하나의 .py 파일에 하나의 DAG을 저장
- DAG 파일을 저장하면, Airflow 웹 UI에서 확인할 수 있음
- Airflow 웹 UI에서 해당 DAG을 ON으로 변경하면 DAG이 스케줄링되어 실행
- DAG 세부 페이지에서 실행된 DAG Run의 결과를 볼 수 있음
이때, DAG 파일은 크게 3가지로 구성되어있다.
- DAG 정의
- Task 정의
- Task 순서 정의
Operator
Operator 란?
Airflow의 작업 유형을 나타내는 클래스로 다양한 Operator가 존재한다. 이 중 자주 사용하는 Operator는 다음과 같다.
PythonOperator- 파이썬 함수를 실행
- 함수 뿐 아니라, Callable한 객체를 파라미터로 넘겨 실행할 수 있음
- 실행할 파이썬 로직을 함수로 생성한 후, PythonOperator로 실행
BashOperator- Bash 커맨드를 실행
- 실행해야 할 프로세스가 파이썬이 아닌 경우에도 BashOperator로 실행 가능
- ex. shell 스크립트, scala 파일 등
DummyOperator- 아무것도 실행하지 않음
- DAG 내에서 Task를 구성할 때, 여러 개의 Task의 SUCCESS를 기다려야 하는 복잡한 Task 구성에서 사용
SimpleHttpOperator- 특정 호스트로 HTTP 요청을 보내고 Response를 반환
- 파이썬 함수에서 requests 모듈을 사용한 뒤 PythonOperator로 실행시켜도 무방
- 다만 이런 기능이 Airflow Operator에 이미 존재하는 것을 알면 좋음
BranchPythonOperator- 특정 조건에 따라 실행을 제어하는 Operator
- 특정 상황엔 A 작업, 없으면 Pass
- ex. 학습한 결과 Accuracy가 기존 모델보다 좋으면 저장 후 모델 업데이트, 좋지 않으면 저장만 진행
- ex. 특정 일자 전에는 A 모델, 그 이후엔 B 모델
클라우드 기능 추상화한 Operator도 존재(AWS, GCP 등) - Provider Packages
💡 Tip
외부 Third Party와 연동해 사용하는 Operator의 경우 (docker, aws, gcp 등) Airflow 설치 시에 다음처럼 extra package를 설치해야 함 ex.
pip install “apache-airflow[aws]”
Operator를 정의하는 방법을 코드로 구현하면 아래의 코드와 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# Task1 정의
t1 = BashOperator(
task_id="print_hello",
bash_command="echo Hello",
owner="heumsi",
retries=3,
retry_delay=timedelta(minutes=5),
)
# Task2 정의
t2 = PythonOperator(
task_id="print_world",
python_callable=print_world,
depends_on_past=True,
owner="heumsi",
retries=3,
retry_delay=timedelta(minutes=5),
)
# Task 순서 : t1 실행 후 t2를 실행
t1 >> t2
어떤 인자가 들어가는지 확인하고 인자를 주입하는 방식으로 구현할 수 있다.
이외에도 Airflow DAG을 더 풍부하게 작성할 수 있는 개념들이 있다.
- Variable : Airflow Console에서 변수(Variable)를 저장해 Airflow DAG에서 활용
- Connection & Hooks : 연결하기 위한 설정(MySQL, GCP 등)
- Sensor : 외부 이벤트를 기다리며 특정 조건이 만족하면 실행
- XComs : Task 끼리 결과를 주고받은 싶은 경우 사용
- Jinja Template : 파이썬의 템플릿 문법. FastAPI에서도 사용
Airflow 아키텍처
Airflow 아키텍처는 아래 그림과 같이 표현할 수 있다.
Scheduler
먼저 Airflow의 Scheduler의 역할을 살펴보자.
Scheduler는 각종 메타 정보의 기록을 담당한다. 또한 DAG Directory 내 .py 파일에서 DAG을 파싱하여 DB에 저장, 스케줄링 관리 및 담당하고 실행 진행 상황과 결과를 DB에 저장한다.
또한 Executor를 통해 스케줄링 기간이 된 DAG을 실행하는 Airflow에서 가장 중요한 컴포넌트라고 할 수 있다.
여기서 Executor은 스케줄링 기간이 된 DAG을 실행하는 객체로 크게 2종류로 나뉜다.
Local Executor: DAG Run을 프로세스 단위로 실행- 하나의 DAG Run을 하나의 프로세스로 띄워서 실행하고 최대로 생성할 프로세스 수를 정해야 하며 주로 Airflow를 간단하게 운영할 때 적합하다.
- Sequential Executor
- 하나의 프로세스에서 모든 DAG Run들을 처리
- Airflow 기본 Executor로, 별도 설정이 없으면 이 Executor를 사용
- Airflow를 테스트로 잠시 운영할 때 적합하며 잘 사용하진 않음
Remote Executor: DAG Run을 외부 프로세스로 실행- Celery Executor
- DAG Run을 Celery Worker Process로 실행
- 보통 Redis를 중간에 두고 같이 사용
- Local Executor를 사용하다, Airflow 운영 규모가 좀 더 커지면 Celery Executor로 전환
- Kubernetes Executor
- 쿠버네티스 상에서 Airflow를 운영할 때 사용
- DAG Run 하나가 하나의 Pod(쿠버네티스의 컨테이너 같은 개념)
- Airflow 운영 규모가 큰 팀에서 사용
- Celery Executor
Workers
Workders는 DAG의 작업을 수행하는 컴포넌트로 Scheduler에 의해 생기고 실행된다. 또한 DAG Run을 실행하는 과정에서 생긴 로그를 저장한다.
Metadata Database
Metadata Database는 이름 그대로 메타데이터를 저장하는 데이터베이스이다.
Scheduler에 의해 Metadata가 저장하며 보통 MySQL이나 PostgresQL를 사용한다.
이때, 주로 다음의 데이터를 저장한다.
- 파싱한 DAG 정보, DAG Run 상태와 실행 내용, Task 정보 등
- User와 Role (RBAC)에 대한 정보 저장
- Scheduler와 더불어 핵심 컴포넌트
- 트러블 슈팅 시, 디버깅을 위해 직접 DB에 연결해 데이터를 확인하기도 함
실제 운영 환경에서는 GCP Cloud SQL이나, AWS Aurora DB 등 클라우드 DB를 사용한다.
Webserver
Webserver는 WEB UI를 담당하며 Metadata DB와 통신하며 유저에게 필요한 메타 데이터를 웹 브라우저에 보여주고 시각화한다.
보통 Airflow 사용자들은 이 웹서버를 이용하여 DAG을 ON/OFF 하며 현재 상황을 파악하는데 사용한다.
하지만, REST API도 제공하므로 꼭 WEB UI를 통해서 통신하지 않아도 되기 때문에 웹서버가 당장 작동하지 않아도, Airflow에 큰 장애가 발생하지 않음
⚠️ 반면 Scheduler의 작동 여부는 매우 중요하다
전체적인 흐름을 시각화하면 아래 그림과 같다.
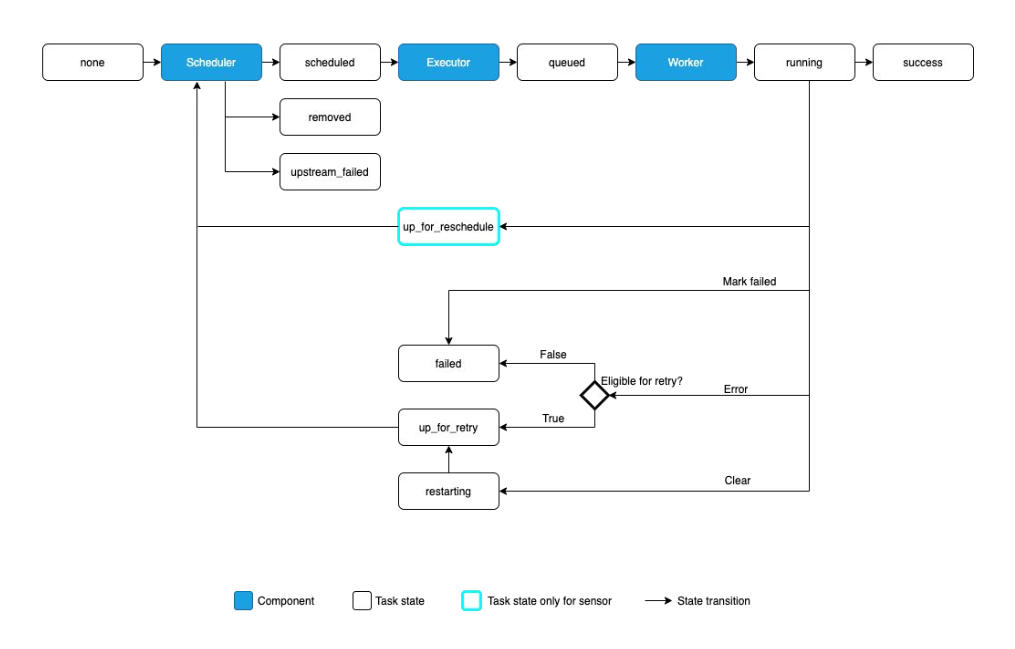
실무에서 Airflow를 구축 과정
실무에서는 Airflow를 구축하는 방법으로 보통 3가지 방법을 사용한다.
- Managed Airflow : 클라우드 서비스 형태로 Airflow를 사용하는 방법(GCP Composer, AWS MWAA)
- 장점
- 설치와 구축을 클릭 몇번으로 클라우드 서비스가 다 진행
- 유저는 DAG 파일을 스토리지(파일 업로드) 형태로 관리
- 단점
- 높은 비용과 적은 자유도, 클라우드에서 기능을 제공하지 않으면 불가능한 제약이 많음
- 장점
VM + Docker compose : 직접 VM 위에서 Docker compose로 Airflow를 배포하는 방법
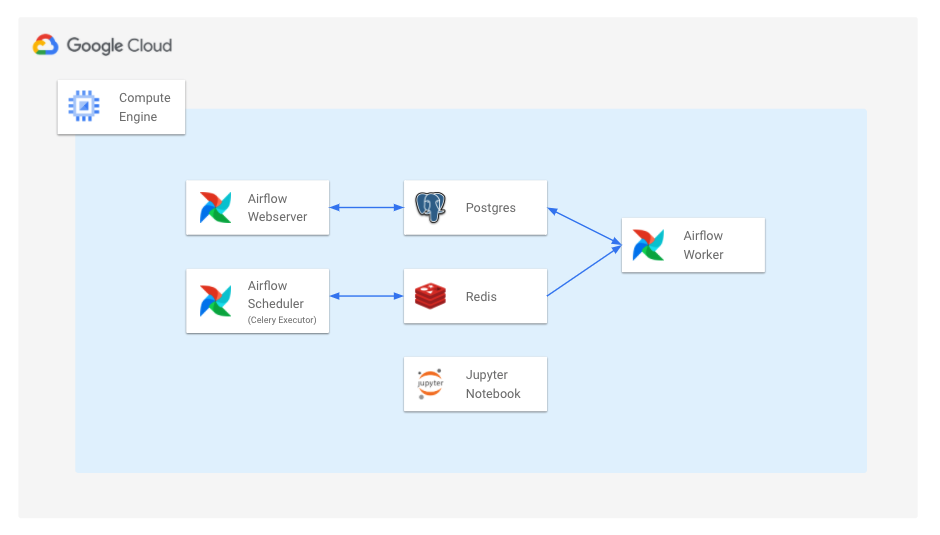
- 장점
- Managed Service 보다는 살짝 복잡하지만, 어려운 난이도는 아님
- (Docker와 Docker compose에 익숙한 사람이라면 금방 익힐 수 있음)
- 하나의 VM만을 사용하기 때문에 단순
- 단점
- 각 도커 컨테이너 별로 환경이 다르므로, 관리 포인트가 늘어남
- 예를 들어, 특정 컨테이너가 갑자기 죽을 수도 있고, 특정 컨테이너에 라이브러리를 설치했다면, 나머지 컨테이너에도 하나씩 설치해야 함
- 장점
- Kubernetes + Helm
- 장점
- 특정 시간에 배치 프로세스를 실행시키는 Airflow와 궁합이 매우 잘 맞음
- Airflow DAG 수가 몇 백개로 늘어나도 노드 오토 스케일링으로 모든 프로세스를 잘 처리할 수 있음
- 단점
- 하지만 쿠버네티스 자체가 난이도가 있는만큼 구축과 운영이 어려움
- 장점
💡Kubernetes 란?
여러 개의 VM을 동적으로 운영하는 일종의 분산환경으로, 리소스 사용이 매우 유연한게 대표적인 특징(필요에 따라 VM 수를 알아서 늘려주고 줄여줌)
관련 추천 글
이 글은 비밀번호로 보호되어 있습니다.