[BoostCamp AI Tech / Product Serving] 웹 프로그래밍
REST API, 클라이언트-서버 아키텍처, 그리고 웹 서비스의 구축과 유지에 대한 내용을 정리한 포스트입니다.
Online Serving 이란 실시간으로 데이터를 처리하고 즉각적인 결과 반환을 할 때 사용한다. 실시간성을 요구하는 경우에 유용하며 주로 Cloud 나 On-Premise 서버에서 모델 호스팅 후, 요청 들어오면 모델이 예측 반환하는 구조이다.
Online Serving 구현
Online Serving을 구현하는 방법은 크게 3가지가 있다.
- 직접 웹 서버 개발: Flask, FastAPI 등 활용해 서버 구축
- 클라우드 서비스 활용: AWS의 SageMaker, GCP의 Vertex AI 등
- 오픈소스 활용: Tensorflow Serving, Torch Serve, MLFlow, BentoML 등
직접 웹 서버 개발
Flask, FastAPI 등을 사용해 서버를 구축한다.
localhost/(ex. www.naver.com/)웹 서버 예시/는 root를 의미
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# Flask 구현
from flask import Flask
app = Flas(__name__)
@app.route("/")
def hello_world():
return "<p>Hello, World"
# FastAPI
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def read_root():
return {"Hello": "World"}
클라우드 서비스 활용
- AWS의 SageMaker, GCP의 Vertex AI 등
- 다양한 서비스들이 존재
클라우드 서비스를 활용하면 얻는 장점은 다음과 같다.
- MLOps의 다양한 부분을 이미 클라우드 회사에서 구축해 제공하기 때문에 활용만 하면 된다.
- 초기에 클라우드에 익숙해져야 하는 러닝커브가 있지만 이 커브만 극복하면 유용하다.
- 회사에서 사람이 적은 경우(=리소스가 적은 경우)에 사용
단점은 다음과 같다.
- 매니지드 서비스를 이용하는 것이기 때문에 직접 구축 대비 운영 비용이 더 나갈 수 있다.
- 해당 서비스에 디펜던시가 생기고, 내부 구현 방식을 정확히 확인하지 못하는 경우도 있다.
오픈소스 활용
- Tensorflow Serving, Torch Serve, MLFlow, BentoML 등
- Fast API 등 활용할 수 있지만, 처음에 서버에 대한 이해가 충분하지 않으면 어려울 수 있음
- 다양한 방식으로 개발할 수 있지만, 매번 추상화된 패턴을 가질 수 있음
- 추상화된 패턴을 잘 제공하는 오픈소스가 여러 개 존재
1
2
3
4
5
6
7
8
9
10
11
# import the IrisClassifier class defined above
from iris_classifier import IrisClassifier
# Create a iris classifier service instance
iris_classifier_service = IrisClassifier()
# Pack the newly trained model artifact
iris_classifier_service.pack('model', clf)
# Save the prediction service to disk for modeling serving
saved_path = iris_classifier_service.save()
(예시) BentoML: 위 코드 실행 및 학습 후 CLI에서 명령어를 입력하면 배포 끝!
bentoml serve IrisClassifier:latest
어떤 방법을 쓰느냐는 주어진 환경(일정, 인력, 예산, 모델 성능 등)에 따라 다르게 선택할 수 있으며
클라우드 매니지드 서비스 → 직접 서버 개발 → 서빙 오픈소스 활용 방식 권장한다.
Online Serving할 때 Serving 할 때 Python 버전, 패키지 버전 등 Dependency가 굉장히 중요하기 때문에 이를 위해 Docker Image, Docker Compose에 익숙해지는 것이 좋다.
또 고려해야할 점은 Latency이다.
실시간 예측을 하기 때문에 예측할 때 지연 시간(Latency)를 최소화해야 한다.
Latency 최소화 방법은 아래와 같다.
- 데이터 전처리 서버 분리 or Feature를 미리 가공(Feature Store)
- 모델 경량화
- 병렬 처리
- 예측 결과 캐싱
병목 지점이 모델 서버가 아닌 데이터를 가지고 오는 Database 일 수 있으므로 유동적으로 성능 확인해서 문제를 해결하는 역량이 필요하다.
Server 아키텍처
실제 회사에서는 하나의 큰 API 서버를 운영하거나 여러 대의 작은 API 서버를 운영하는 경우가 있다.
이를 각각 모놀리스 아키텍처, 마이크로 서비스 아키텍처 라고 부른다.
모놀리스 아키텍처
- 하나의 큰 서버로 개발
- 모든 로직이 하나의 거대한 코드 베이스에 저장
- 일반 서비스와 ML 서비스 코드가 혼재
- 배포해야 할 코드 프로젝트가 하나
- Github : 모노레포
아키텍처를 시각화하면 아래 그림과 같다.
- Client는 하나의 Server (혹은 Load Balancer)에게 요청
- Server는 내부적으로 처리하고 요청을 반환
장점
- 서비스 개발 초기에는 단순하고 직관적
- 관리해야 할 코드 베이스가 하나라 심플
단점
- 모든 서비스 로직이 다 하나의 저장소에 저장
- 나중엔 너무 커져서 이해하기 어려움(=복잡도 증가)
- 서비스 코드 간 결합도가 높아서, 추후에 수정이나 추가 개발하기 어려울 수 있음
- 의존성 및 환경을 하나로 통일
Usecase
- 서비스 초기 단계에 개발하는 경우
- 협업하는 개발자가 많지 않은 경우
- 아직 코드와 결합도에 대한 복잡성을 느끼지 못하는 경우
마이크로서비스 아키텍처
- 작은 여러개의 서버로 개발
- 모든 로직이 각각의 개별 코드에 저장
- 일반 서비스와 ML 서비스 코드가 분리
- 배포해야 할 코드 프로젝트가 여러개
아키텍처를 시각화하면 아래 그림과 같다.
- Client는 하나의 Server (혹은 Load Balancer)에게 요청
- Server는 이 요청을 처리할 각각의 내부적인 Server(요리 담당, 비품 담당)로 요청
- 내부적인 Server들이 이 요청을 처리하고 다시 요청했던 Server로 반환
- Server는 이 응답을 받아 필요에 맞게 변환 후 Client에게 반환
장점
- 거대한 코드 베이스를 작게 나눌 수 있음(마치 거대한 코드를 리팩토링 하는 것과 유사함)
- 필요에 따라 각 담당 서버 단위로 스케일 업/다운이 가능함
- ex. 요리 담당 서버가 바쁜 경우, 요리 담당 서버만 더 늘릴 수 있음
- 의존성 및 환경을 담당 서버 별로 다르게 둘 수 있음
단점
- 전체적인 구조와 통신이 복잡해짐
Usecase
- 서비스가 어느정도 고도화되고, 서비스와 개발팀의 규모가 커졌을 경우
- 서비스별로 독립된 환경, 의존성, 스케일 업/다운이 필요한 경우
그럼 어떤 상황에 어떤 아키텍처를 사용해야할까?
- 규모가 작고, 개발 조직이 하나인 회사인 경우
- 모놀리스 아키텍처를 사용할 가능성이 존재
- 개발팀과 커뮤니케이션을 잘해야 하고, 서비스 로직 코드도 어느정도 볼 수 있어야 함
- 서버 코드가 Python으로 개발된 경우, 보통 해당 서버 코드의 환경, 의존성 패키지를 따라야 함
- 만약 Python이 아닌 경우, 내가 개발한 Python 코드를 메인 서버 로직에서 스크립트 성으로 실행시킬 가능성이 있음
- 규모가 있고, 개발과 ML이 분리되어 있는 회사의 경우
- 마이크로서비스 아키텍처를 사용할 가능성이 큼
- 이 경우, 개발팀과는 API 스펙을 통해서 커뮤니케이션을 주로 하게 됨.
- 메인 서비스 코드와 분리되어 있기 때문에, 서버 코드의 환경, 의존성 패키지를 서비스 로직과 별도로 가져갈 수 있음
API
API는 “Application Programming Interface”의 약자로, 소프트웨어 응용 프로그램들이 서로 상호 작용하기 위한 인터페이스를 총칭하는 말이다.
쉽게 말해 특정 소프트웨어에서 다른 소프트웨어를 사용할 때의 인터페이스를 말하며 기본적으로 사람을 위한 인터페이스(UI, User Interface)가 아니라, 소프트웨어를 위한 인터페이스이다.
API의 구현에는 웹 API, 라이브러리, OS 시스템 콜 등 다양한 종류가 존재한다.
- Web API : Web에서 사용되는 API
- 라이브러리 API나 시스템 콜 등의 API는 Web에서 사용되지 않고, Web을 이용하지 않음
- 주로 HTTP를 통해 웹 기슬을 기반으로 하는 인터페이스
💡 HTTP란?
- HTTP(Hyper Text Transfer Protocol) : 정보를 주고 받을 때 지켜야 하는 통신 프로토콜(규약), 약속
- 한번 더 질문하거나 예외 처리할 수 있지만, 많은 정보가 오고 갈 땐 이 부분이 이슈가 됨
- HTTP는 기본적으로 80번 포트를 사용하고 있으며, 서버에서 80번 포트를 열어주지 않으면 HTTP 통신이 불가능
Web API로 주로 다음 방법들이 많이 사용된다.
- REST (Representational State Transfer)
- GraphQL
- RPC (Remote Procedure Call)
REST API
REST API는 Representational State Transfer의 약자로 “자원을 표현하고 상태를 전송하는 것”에 중점을 둔 API 이다.
정확히 말하면 REST라고 부르는 아키텍처 “스타일”로 HTTP 통신을 활용하며 가장 대중적이고, 현대의 대부분의 서버들이 이 API 방법을 채택했다.
REST API는 각 요청이 어떤 동작이나 정보를 위한 것을 요청 모습 자체로 추론할 수 있다.
- 기본적인 데이터 처리 : 조회 작업, 새로 추가, 수정, 삭제
- CRUD : Create, Read, Update, Delete
그리고 Resource, Method, Representation of Resource로 구성된다.
- Resource : Unique한 ID를 가지는 리소스, URI
- Method : 서버에 요청을 보내기 위한 방식 : GET, POST, PUT, PATCH, DELETE
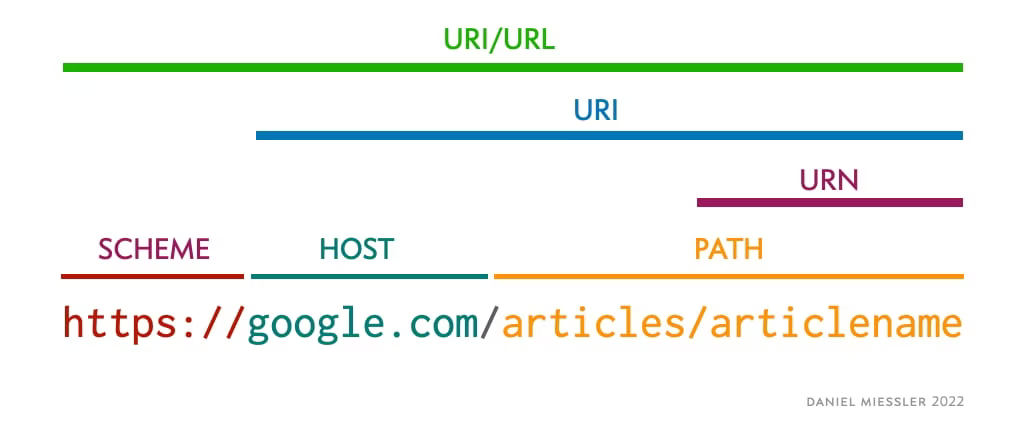
💡 URI와 URL
- URL : Uniform Resource Locator로 인터넷 상 자원의 위치
- URI : Uniform Resource Identifier로 인터넷 상의 자원을 식별하기 위한 문자열의 구성 URI는 URL을 포함하게 되며, URI가 더 포괄적인 범위이다.
REST API 예시
GET http://localhost:8080/users?name=seongyun 을 받았다고 하지
GET- HTTP Method 부분
- 하고자 하는 것을 주 표현함 (그래서 동사)
- HTTP Method 종류로 주로 사용되는 것
- GET: 리소스를 조회할 때
- POST: 리소스를 생성할 때
- PUT: 생성된 리소스 하나를 전체 업데이트할 때
- PATCH: 생성된 리소스 하나를 부분 업데이트할 때
- DELETE: 생성된 리소스 하나를 삭제할 때
- 위 API는 users라는 리소스를 조회하는 API 호출
http://localhost:8080/users?name=seongyun- HTTP URL 부분
- 다루고자 하는 대상이 되는 것을 주로 표현
http://- URL 내 Schema. 사용하는 프로토콜
- 여기서는 프로토콜로 HTTP를 사용하겠다는 의미
- HTTP의 경우 항상 http:// (혹은 https://)가 되어야 함
- 만약 HTTP를 사용하지 않는 Web API의 경우, 이 부분은 바뀔 수 있음 (tcp, udp등)
localhost- URL 내 Host 부분
- IP가 될 수도 있고, Domain Name이 될 수도 있음
- localhost는 127.0.0.1이라는 IP의 예약된 Domain Name
- 127.0.0.1은 외부 네트워크에서 접근 불가능한 내 컴퓨터의 로컬 IP
8080- URL 내 Port 부분
- 하나의 호스트 내에서도 여러 Port를 가질 수 있음
- ex. localhost:3030에는 서버 1을, localhost:8080에는 서버 2를 실행시킬 수 있음
- 각 프로세스(서버)는 하나의 Port를 사용하여 네트워크 통신
- 즉, 위 API 호출은 localhost(내 컴퓨터)의 8080 포트에서 리슨하고 있는 서버로 HTTP 요청하는 것
- 위 요청에 대한 응답이 정상적으로 오려면, localhost(내 컴퓨터)의 8080 포트에 서버가 실행되고 있어야 함
/users- URL 내 Path 부분
- API 엔드포인트(Endpoint)라고도 불림
- 위 케이스 : /users 라는 엔드포인트가 있고, 이 엔드포인트를 호출하면 유저 목록을 반환해줄 것이라는 것을 예상 가능
- ML 관련 API는 보통 /predict, /train와 같은 엔드포인트를 사용
URL Parameters
URL 내 Parameter가 있으며 크게 2가지 구성으로 나눌 수 있다.
- Query Parameter
- URL의 끝에 추가하며, 특정 리소스의 추가 정보를 제공 또는 데이터를 필터링할 때 사용
- Parameter가 Query String에 저장
- API 뒤에 입력 데이터를 함께 제공하는 방식으로 사용
- Query String은 Key, Value의 쌍으로 이루어지며 &로 연결해 여러 데이터를 넘길 수 있음
- ex. http://localhost:8080/users
?name=seongyun

- 정렬, 필터링을 해야 하는 경우(선택적인 정보) : Query Parameter가 더 적합
- Path Parameter
- 리소스의 정확한 위치나 특정 리소스를 찾을 때 사용
- Parameter가 Path에 저장
- ex. http://localhost:8080/users
/seongyun - users/ 뒤에 나오는 Path Parameter 값은 /users/chulsoo, /users/younghee 처럼 바뀔 수 있음
- ex. /books/{bookId}
- 책에서 특정 책을 찾는 것
- Resource를 식별해야 하는 경우(필수적인 정보) : Path Parameter가 더 적합
- 리소스의 정확한 위치나 특정 리소스를 찾을 때 사용
HTTP Header, Payload
HTTP Method와 URL뿐이 아니라, HTTP Header와 HTTP Payload를 사용하여 요청할 수 있다.
ex. curl -X POST -H “Content-Type: application/json” -d ‘{“name”: “seongyun”}’ http://localhost:8080/users
curl: 터미널(CLI) 환경에서 HTTP 요청을 할 때 주로 사용하는 도구-X POST: HTTP 메서드로 POST를 사용-H "Content-Type: application/json"HTTP Header에 Content-Type: application/json 이라는 key: value를 추가- 우리가 지금 보내는 데이터가 JSON 타입임을 표현
- HTTP Header에 key: value 형태로 데이터를 저장할 수 있음
-d '{"name": "seongyun"}'- Payload로 JSON을 추가
- Payload는 앞 뒤에 따옴표(“)를 붙여야 함
http://localhost:8080/users- HTTP URL 부분
- 요청을 어디로 보낼 것인지 표현
Status Code
- 클라이언트 요청에 따라 서버가 어떻게 반응하는지를 알려주는 Code
- 1xx(정보) : 요청을 받았고, 프로세스를 계속 진행함
- 2xx(성공) : 요청을 성공적으로 받았고, 실행함
- 3xx(리다이렉션) : 요청 완료를 위한 추가 작업이 필요
- 4xx(클라이언트 오류) : 요청 문법이 잘못되었거나 요청을 처리할 수 없음
- 5xx(서버 오류) 서버가 요청에 대해 실패함
- 미리 정의되어 있음
IP
IP는 네트워크에 연결된 특정 PC의 주소를 나타내는 체계이다.
- Internet Protocol의 줄임말, 인터넷상에서 사용하는 주소체계
- 네 덩이의 숫자로 구성된 IP 주소 체계를 IPv4라고 함
- 각 덩어리마다 0~255로 나타낼 수 있음. 2^32 = 약 43억개의 IP 주소를 표현할 수 있음
이미 몇가지 용도가 정해져있다.
- localhost, 127.0.0.1 : 현재 사용 중인 Local PC
- 0.0.0.0, 255.255.255.255 : broadcast address, 로컬 네트워크에 접속된 모든 장치와 소통하는 주소
- 개인 PC 보급으로 누구나 PC를 사용해 IPv4로 할당할 수 있는 한계점 진입, IPv6이 나옴
Port
IP 주소 뒤에 나오는 숫자(ex. 127.0.0.1:8080)로 PC에 접속할 수 있는 통로(채널)이다.
- 사용 중인 포트는 중복할 수 없음
- Jupyter Notebook은 8888
- Port는 0 ~ 65535까지 존재
UseCase
- 0~1023는 통신을 위한 규약에 예약됨
- 22 : SSH
- 80 : HTTP
- 443 : HTTPS
이 글은 비밀번호로 보호되어 있습니다.