[BoostCamp AI Tech / NLP 이론] Tokenization
토큰화가 무엇인지 그리고 토큰화의 종류에 대해 정리한 포스트입니다.
Tokenization(토큰화)란 주어진 Text를 Token 단위로 분리하는 방법을 말하며 Token(토큰)은 자연어 처리 모델이 각 타임스텝에서 주어지는 각 단어로 다루는 단위를 말한다.
- 자연어 처리 모델은 Tokenization 방식에 따라 Text를 Token으로 나누어 입력을 처리
- 모델이 처리할 수 있는 단어는 사전에 정의되어 있음 → Vocabulary (단어 사전)
- categorical 로 볼 수 있으며 이를
one-hot vector로 표현할 수 있다.
- categorical 로 볼 수 있으며 이를
Tokenization은 크게 3가지 방식으로 구군할 수 있다.
- Word-level Tokenization
- Character-level Tokenization
- Subword-level Tokenization
Word-Level Tokenization
Token을 단어(Word) 단위로 구분한다.
- 일반적으로
단어는 띄어쓰기를 기준으로 구분- 입력: “The devil is in the details”
- 출력: [‘The’, ‘devil’, ‘is’, ‘in’, ‘the’, ‘details’]
- 한국어에서는
형태소를 기준으로도 단어를 구분하기도 함- 입력: “나는 밥을 먹었다.”
- 출력: [‘나’, ‘는’, ‘’, ‘밥’, ‘을’, ‘’, ‘먹’, ‘었다’]
단점은 사전에 없는 단어가 등장하는 경우, 모두 “Unknown” 토큰으로 처리되며 이러한 문제를 Out-of-vocabulary(OOV) 라고 말한다.
Character-level Tokenization
Token을 철자(Character) 단위로 구분한다.
- 입력: “The devil is in the details”
- 출력: [‘T’, ‘h’, ‘e’, ‘’, ‘d’, ‘e’, ‘v’, ‘i’, ‘l’, ‘’, ‘i’, ‘s’, ‘’, ‘i’, ‘n’, ‘’, ‘t’, ‘h’, ‘e’, ‘’, ‘d’, ‘e’, ‘t’, ‘a’, ‘i’, ‘l’, ‘s’]
장점은 다른 언어라도 같은 철자를 사용하는 경우 Token으로 처리가 가능하며 단어 단위 Tokenization의 단점은 OOV 문제를 해결할 수 있다.
하지만, 주어진 텍스트에 대한 Token의 개수가 지나치게 많다. 또한, 토큰 단위로 인코딩할 때 각각의 토큰이 어떤 유의미한 의미를 내포하는 것이 좋지만 철자 단위 토큰화는 유의미한 의미를 가지기 어렵다.
따라서, 일반적으로 이 토큰화를 사용했을 떄는 모델이 낮은 성능을 보인다는 단점이 있다.
Subword-level Tokenization
Token을 Subword 단위로 구분하며 이 방법은 Word-level과 Character-level를 적절히 섞은 방식이다.
- 입력: “The devil is in the details”
- 출력: [‘The’, ‘’, ‘de’, ‘vil’, ‘’, ‘is’, ‘’, ‘in’, ‘’, ‘the’, ‘’, ‘de’, ‘tail’, ‘s’]
Subword Tokenization 방법론에 따라 Subword 단위는 다양하게 결정한다. Subword 토큰화 또한 사전을 구축할 필요가 있다.
- ex. Byte-pair Encoding (BPE)
- 철자들로만 이루어진 단어장을 구성
- 가장 빈번하게 등장하는 n-gram 쌍을 단어장에 추가
이 방법의 장점은 다음과 같다.
- 철자 단위 Tokenization 방식에 비해 사용되는 Token의 평균 개수가 적음
- 각각의 단일 character도 사전에 포함하기 때문에 OOV 문제가 없음
- Subword 단위 Tokenization 기반 모델들의 뛰어난 성능
Byte Pair Encoding (BPE)
Subword-Level Tokenization의 대표적인 예시로 Byte Pair Encoding이 있다.
BPE를 수행하는 방식은 다음과 같다.
- 철자 단위의 단어 목록을 만든다.
- 가장 빈도수가 높은 단어 Pair를 Token으로 추가한다.
- Token으로 추가한 단어 Pair를 철자 단위로 취급하여 단어 Pair 빈도수를 갱신한다.
- 위의 과정을 반복하여 최대로 등록할 수 있는 단어 수에 도달할 때 까지 단어 사전을 구축한다.
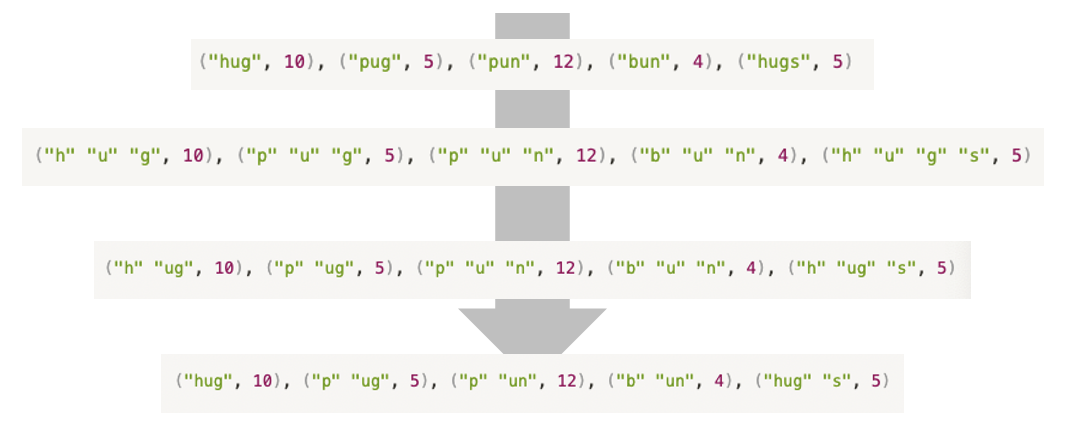
이러한 방식은 단일 Character 토큰화하는 것보다 더 유의미한 의미를 담은 토큰이 담긴 단어 사전을 구축할 수 있으다.
만약, 주어진 입력 텍스트에 대해 Tokenization 하는 방식은 입력된 String을 Character 단위로 왼쪽에서부터 차례로 사전에 정의된 가장 긴 문자열을 토큰으로 매칭한다.
더 자세한 내용은 아래 사이트를 참고하자.
참고: 바이트 페어 인코딩이란?
Other Subword Tokenization Methods
WordPiece- 학습 데이터 내의 likelihood(조건부확률) 값을 최대화하는 워드 쌍을 Vocabulary에 추가
- 활용 모델 - BERT, DistilBERT, ELECTRA
SentencePiece- 공백을 Token으로 활용
- Subword의 위치가 띄어쓰기 뒤에 등장하는지, 다른 Subword에 이어서 등장하는지 구분
- 활용 모델 – ALBERT, XLNet, T5
이 글은 비밀번호로 보호되어 있습니다.