[BoostCamp AI Tech / NLP 이론] RNN과 Language Modeling
자연어 처리 분야에서 Recurrent Neural Network(RNN)를 활용하는 방법과 Language Modeling에 대한 설명을 정리한 포스트입니다.
RNN(Recurrent Neural Network)
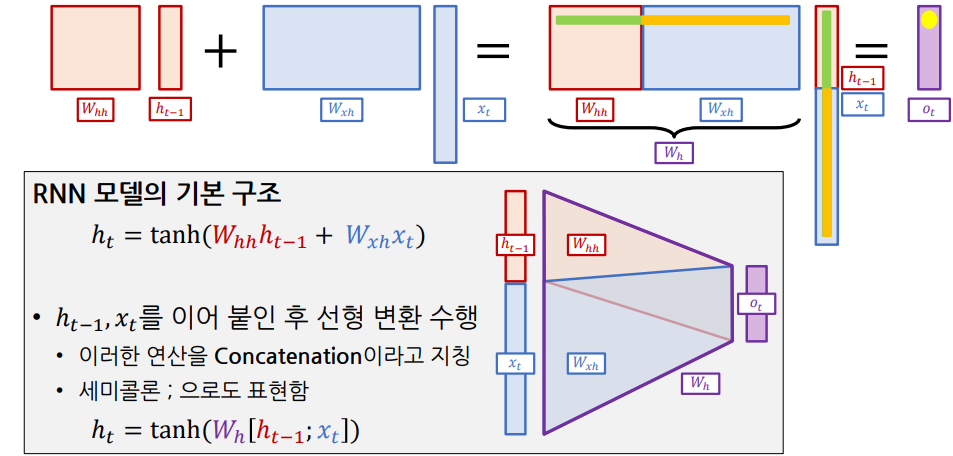
RNN(Recurrent Neural Network)은 자연어 처리 및 시계열 데이터를 다루는데 특화된 모델로 어떤 가변적인 길이의 Sequence 데이터를 입력으로 받아서 어떤 벡터 형태의 output을 매 Time step에서 반복적으로 출력한다. 또한, 이름에서 알 수 있듯이 무언가 반복적, 재귀적으로 호출되는 함수의 형태를 가지고 있다.

$W_{hh}$, $W_{xh}$ : $h_t$로 션형 변환하기 위한 가중치 행렬
- Activation function으로 주로 Zero-centered인 Tanh를 사용
- 추가로, Target을 예측하기 위하여 $h_t$ 를 사용해 $y_t$ 출력할 수 있음
- e.g. $y_t = W_{hy}h_t$
모든 Time step에서 같은 함수 $f_{\theta}$ 와 같은 Parameter $\theta$ 적용
Hidden-State Vector 계산
Rolled / Unrolled RNN
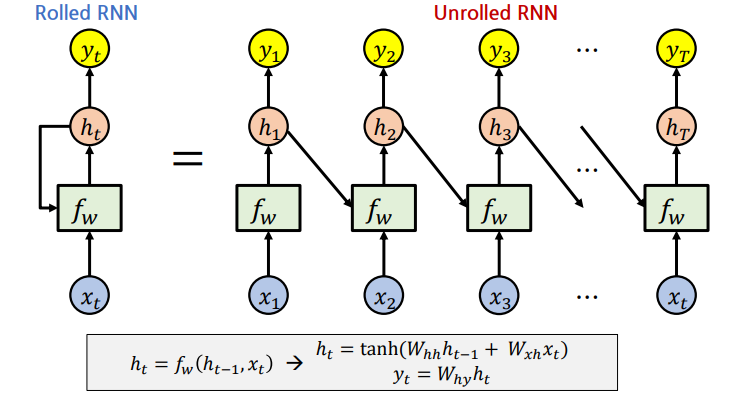
Rolled RNN: RNN의 기본 입출력 세팅을 재귀적인 형태- RNN의 출력이 $h_t$로 나왔을 때 다음 Time-step에서는 이 $h_t$를 $h_{t-1}$ 자격으로 다시 RNN 모델에 입력되는 방식으로 나타낸다.
Unrolled RNN: 여러 Time-step을 펼쳐두고 RNN의 입출력 구조를 이전 Time-step에서 다음 Time-step으로 넘어가는 형태- 각 Time-step에서 나온 hidden state vector가 그 다음 Time-step의 입력으로 들어가며 그 중 맨 처음에 입력되는 $h_0$는 zero vector로 입력으로 주는 것이 일반적이다.
RNN의 응용
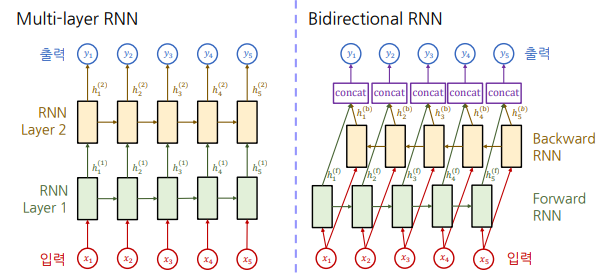
주어진 입력 sequence를 RNN으로 다룰 때 여러 layer에 걸쳐서 RNN을 쌓아 나갈 수도 있다.
이렇게 모델의 출력을 다시 입력으로 사용해 순차적으로 예측하는 모델을 Auto-regressive 모델이라고 함.
Multi-layer RNN- 첫 번째 layer는 입력을 통해 hidden state를 만들고 그 다음 layer부터는 이전에 만들어낸 hidden state vector을 입력으로 받음
- 입력 시퀀스의 길이를 유지하는 것을 동시에 이 정보들을 계속 축적해나가는 방식으로 조금 더 유의미한 정보가 담긴 벡터들로 변환할 수 있음
Bidirectional RNN- 왼쪽 → 오른쪽, 오른쪽 → 왼쪽 방향으로 각각 정보를 축적한 뒤 concat
- 기본적인 RNN은 왼쪽에서 오른쪽 방향으로 정보를 축적함.
- 오른쪽에서 나타나는 정보를 반영해야 하는 경우에 유리 (e.g. I read books that he gave.)
- 왼쪽 → 오른쪽, 오른쪽 → 왼쪽 방향으로 각각 정보를 축적한 뒤 concat
RNN의 형태
입력뿐만 아니라 출력도 sequence 형태로 받을 수 있다.
입력과 출력의 형태가 단일/시퀀스 인지에 따라 RNN을 분류할 수 있다.
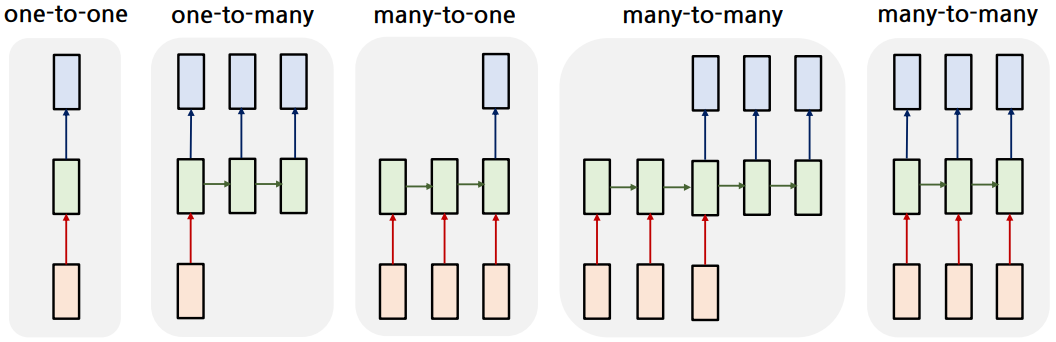
one-to-one: 평범한 Neural Network (e.g. 자동차 사진 → “자동차”)one-to-many: Image captioning 등에 사용 (e.g. 자동차 사진 → “전시장”, “의”, “자동차”)- 입력이 없는 경우는 zero-vector를 사용함.
many-to-one: 감정 분류 등에 사용 (e.g. “재미있는”, “영화”, “였어요” → “긍정”)many-to-many(1): 기계 번역 등에 사용 (e.g. “I”, “love”, “you” → “당신을”, “사랑”, “합니다”)- 입력 시퀀스를 끝까지 읽은 후 출력 시퀀스를 Time-step 마다 하나씩 출력
many-to-many(2): 지연이 없어야 하는 실시간 처리에 사용- 입력 시퀀스를 읽으면서 바로 출력 시퀀스를 바로 출력
- Frame 단위 Video classification, Language Modeling 등
Language Modeling
Language Model은 딜레이없이 매 Time-step마다 예측을 수행하는 구조로 다음에 어떤 단어(혹은 토큰)이 올 지 예측한다.
문자열 단위 Language Model
- Vocabulary: [h, e, l, o]
- 학습 문자열
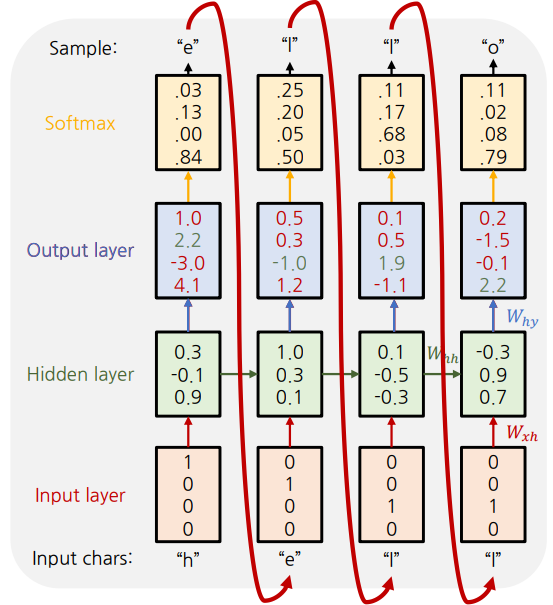
- 각 문자를
One-hot encoding으로 입력
각 문자를 One-hot encoding으로 표현하는 이유
- ‘h’: 1, ‘e’: 2, ‘l’: 3, … 으로 표현하면 각 문자에 Continuous한 순서가 생김.
- 실제론 순서가 존재하지 않으며, 2.5같은 index는 존재하지 않음.
One-hot encoding으로 표현하면 각 문자는 독립성을 유지하며, 일종의 Categorical variable로 생각할 수 있음.
- 입력 $x_t$으로 Hidden state $h_t$ 계산
- $h_t = tanh(W_{hh}h_{t-1} + W_{xh}x_t)$
- Hidden state $h_{t}$ 에서 출력 $y_{t}$ 를 계산
- $y_t = W_{hy}h_{t}$
- Softmax를 통해 각 문자의 확률 계산
Cross-entropy loss계산 및 학습- 학습은 softmax에 출력된 확률값들 중 정답 문자에 대한 확률값이 높게 예측되도록 학습이 진행한다.
이렇게 학습을 마친 모델은 추론할 때 한 글자씩 예측값을 생성한다.
현재 예측된 출력값을 다음 Time-step의 입력값으로 사용하는 방식을
auto-regressive라고 한다.
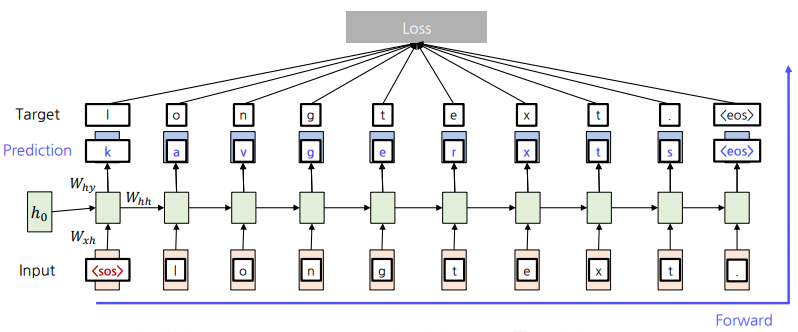
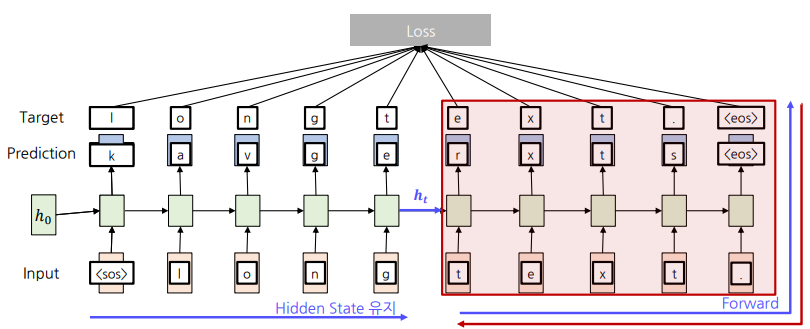
문자열 단위 Language Model 학습
- Forward 과정에서 예측값과 Ground-truth 값의 Softmax Loss를 계산한다.
- 사전이 시작 토큰
<sos>와 마침 토큰<eos>를 미리 정의하여 문장의 시작과 끝을 알져준다.
- Backward 과정에서 가중치($W_{xh}$, $W_{hy}$, $W_{hh}$)를 Update함.
- Output과 정답 (Ground-truth) 간의 차이가 발생할 시에 Loss를 이용
- 가중치는 모든 Timestep에서 공유함
- 빨간색 Backward 경로의 가중치들이 Gradient flow를 통해 Update
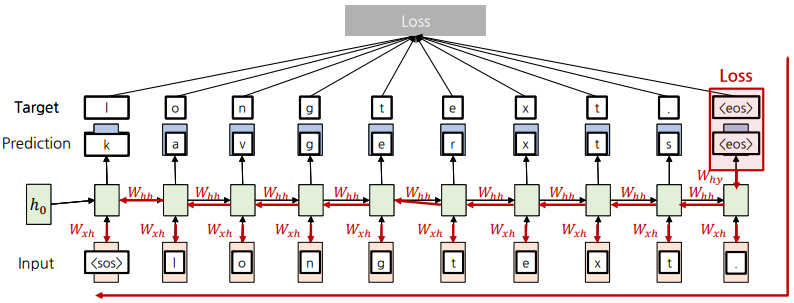
Backpropagation을 위해 전체 Sequence에 대한 Gradient 계산하는 방식을 BPTT(Backpropagation Through Time)이라고 한다. 이 방식의 문제점은 계산 비용이 많이 들고 메모리 요구량이 크다는 점이다. 이를
이를 해결하기 위한 방법이 바로 Truncated Backpropagation Through Time 이다.
Truncated Backpropagation Through Time
Sequence를 Chunk 단위로 나눠 Forward와 Backward를 진행한다.
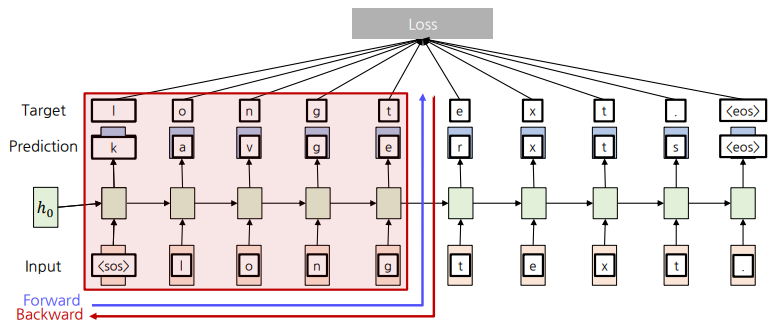
Backpropagation을 Chunk 안에서만 진행해 계산량을 줄인다.
- 파라미터를 Update를 한 후에 이 값들을 GPU에서 모두 지우고 새로운 다음 Chuck를 GPU에 할당한다.
이 글은 비밀번호로 보호되어 있습니다.