[BoostCamp AI Tech / NLP 이론] LSTM과 GRU
Vanishing Gradient 문제를 완화한 LSTM과 GRU의 구조 및 동작 과정을 정리한 포스트입니다.
LSTM(Long Short-Term Memory)
LSTM(Long Short-Term Memory) 모델은 RNN과 같이 매 Time step 마다 반복적으로 동일 모듈을 적용한다. 모델 안에는 4개의 Vector를 계산하는 신경망이 존재한다.

LSTM과 Vanilla RNN과의 차이점은 hidden state를 계산하는 방식이다.
RNN은 전 단계의 hidden state와 현재 input을 통해 현재 hidden state를 구했다. 반면에, LSTM은 hidden state를 계산하는 방법이 훨씬 복잡해졌다.
LSTM에서는 RNN에 없던 cell state가 있는데 전 Time step의 cell state 정보로부터 일부의 정보만을 담도록 변환된 벡터를 해당 Time step의 hidden state가 된다. 즉, cell state가 RNN의 hidden state의 역할을 한다고 말할 수 있다.
cell state의 업데이트 과정이 동일한 $W_{hh}$ 행렬을 반복적으로 곱하는 것이 아니라 좀 더 복잡한 계산을 거쳐서 업데이트를 한다.
이러한 방법은 Gradient Vanishing과 Exploding 문제를 방지한다.
Highway network
LSTM에서는 ResNet 모델에서 사용한 기법인 skip connection을 변형한 Highway network 기법을 사용한다.
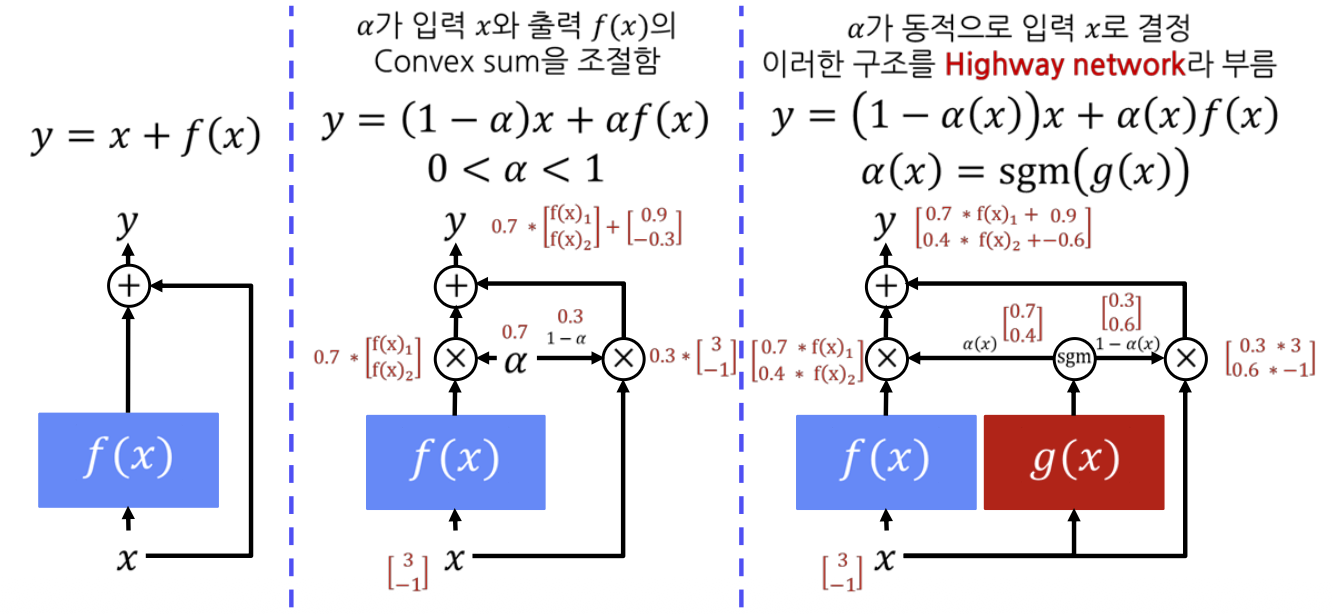
- 첫번째 구조 : skip connection은 입력값과 함수를 거친 출력값을 그대로 더하는 방식이다.
- 두번쨰 구조 : 이를 발전시켜 입력과 함수의 출력값의 비율($\alpha$)를 조정하는 방식으로 계산할 수 있다.
- 여기서 $\alpha$는 고정된 값으로 적용되는 상수라고 볼 수 있다.
- 세번째 구조 : 입력과 함수의 출력값에 곱해지는 가중치 또한 동적으로 만든 방식이다.
- $g(x)$ : 가중치를 계산하는 function
- $\alpha(x)$ 는 $g(x)$를 입력으로 한 sigmoid 함수의 출력값으로 사용하여 0과 1 사이의 값으로 범위를 변경해주는 과정을 거친다.
입력, 출력, 가중치 모두 동일한 차원이다.
LSTM의 구조는 세번째 구조에서 더 발전된 구조를 갖는다.
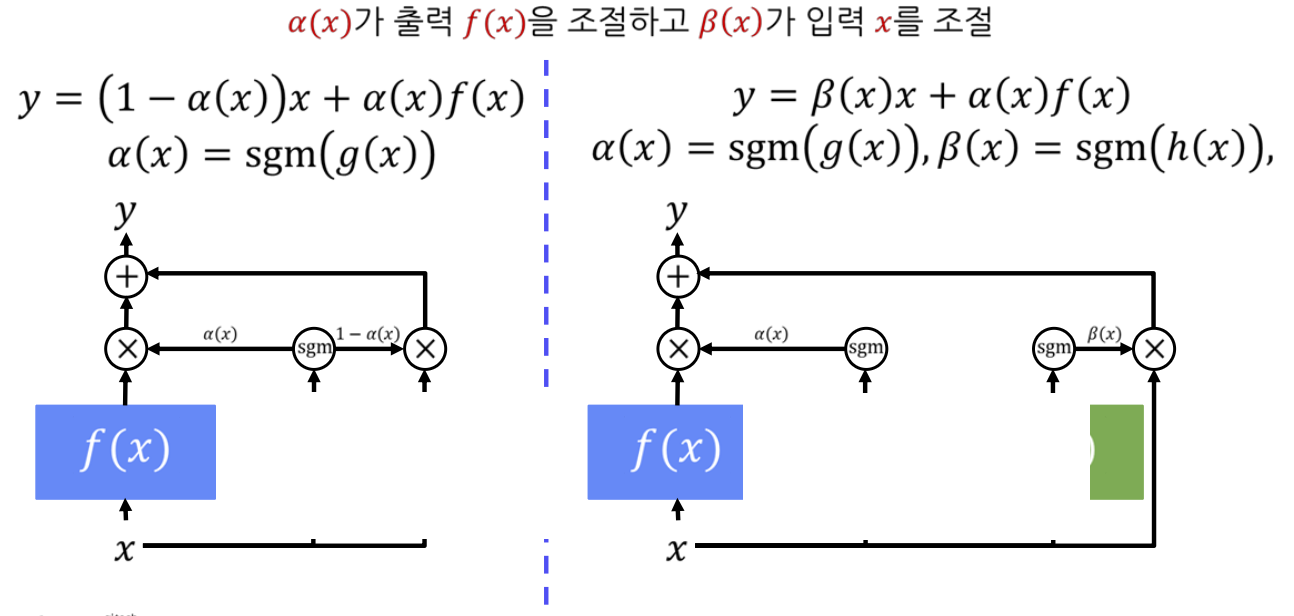
첫번째 구조에서는 입력 $x$와 함수의 출력값 $f(x)$ 모두 $\alpha(x)$ 라는 가중치에 영향을 받는다. 하지만 두번째 구조는 입력과 출력이 동적인 서로 다른 가중치에 영향을 받는다.
최종 결과값은 동적인 서로 다른 가중치의 영향을 받는 값들의 합으로 결정된다.
LSTM의 Notation
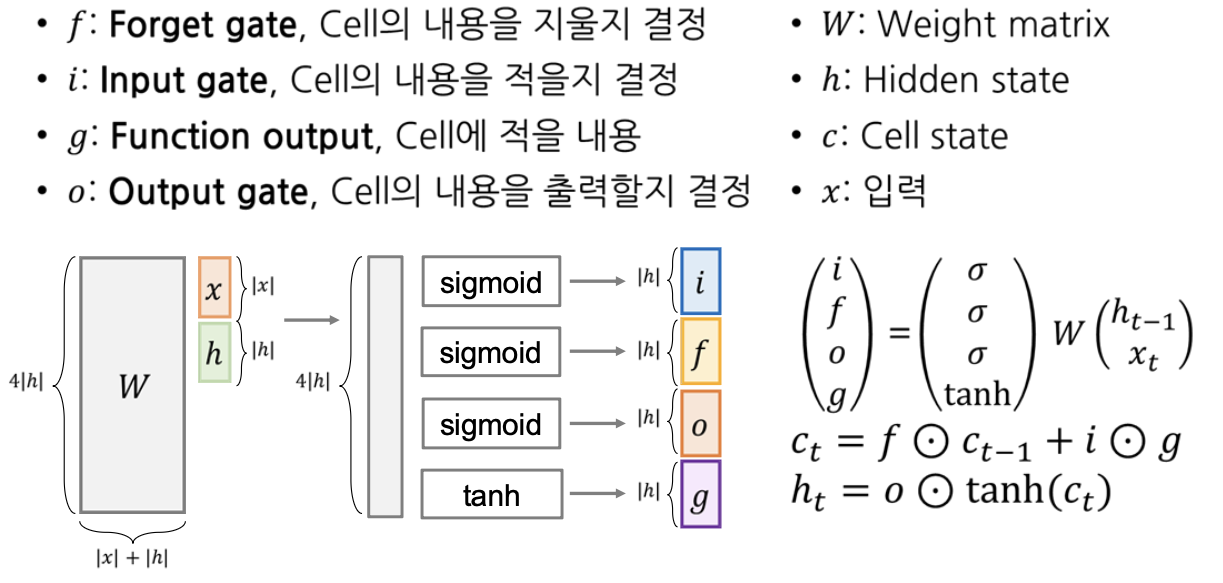
현재 Time step의 입력 벡터 $x$와 이전 Time step의 hidden state를 concat 한 벡터 형태로 입력을 받은 후 $W$ 와 행렬곱하여 선형 변환을 한다. 이 결과값은 hidden state의 차원과 동일한 차원을 갖는다.
이 벡터들 중 3개의 벡터는 sigmoid를 나머지 하나는 tanh 연산을 통해 4개의 gate 만든다.
- $f$ : Forget gate, Cell의 내용을 지울지 결정
- $i$ : Input gate, Cell의 내용을 적을지 결정
- $g$ : Function output, Cell에 적을 내용
- $o$ : Output gate, Cell의 내용을 출력할지 결정
위의 gate를 이용해서 현재 Time step의 cell state와 hidden state를 계산한다. 이때, 벡터의 곱($\odot$)은 element-wise multiplication을 수행한다.
LSTM의 구조
LSTM를 좀 더 자세히 살펴보자.
LSTM의 구조를 보면 위에서 설명한 Highway network 구조를 갖는다.
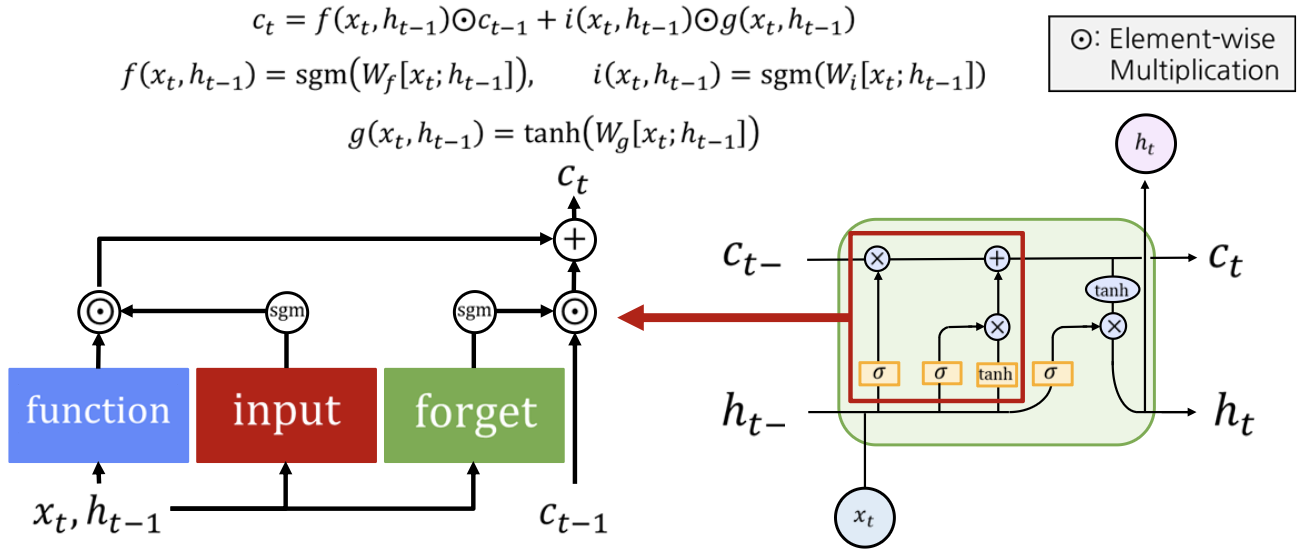
- 이전 Time step에서 넘어온 $c_{t-1}$는 forget gate와 곱해지는데 이 gate는 sigmoid를 지나기 때문에 원소들이 0~1 사이의 값을 가진다.
- $c_t$를 계산하는 식에서 두번쨰 항의 $i(x_t, h_{t-1})$는 input gate로 이 gate는 sigmoid 함수를 통과한 벡터이므로 각각의 원소들이 0~1 사이의 값을 가진다.
즉, input gate가 현재 Time step에서 계산한 정보의 출력을 조절하고, forget gate가 $c_{t-1}$ 을 조절하는 방식이다.
LSTM에서 핵심 아이디어는 Cell state 정보를 어떠한 왜곡 없이 전달할 수 있는 능력을 가지기 때문에 장기 기억 문제(Long-term dependency)를 해결할 수 있다.
LSTM의 cell state는 덧셈 형태로 이전 상태가 전달되기 때문에, gradient가 곱셈으로 계속 축소되지 않고 그대로 전달되어 장기 의존성을 학습할 수 있게 된다.
\[\frac{\partial L}{\partial C_{t-k}} = \frac{\partial L}{\partial C_t} \odot \prod_{i=t-k+1}^t f_i\]역전파 과정을 수식으로 표현하면 위와 같이 표현할 수 있으며 여기서 $f_i$는 0.8~1.0 사이를 유지하기 때문에 RNN의 장기 의존성 문제를 부분적으로 해결이 가능하다.

위에서 계산한 Cell state로부터 Hidden state를 생성한다. 이렇게 생성된 Hidden staet를 그대로 사용하지 않고 Output gate를 통해 조절한다.
이러한 과정을 거친 Hidden state를 다음 Time step으로 전달, 그리고 출력/다음 층으로 전달한다.
Cell staet 계산 예시
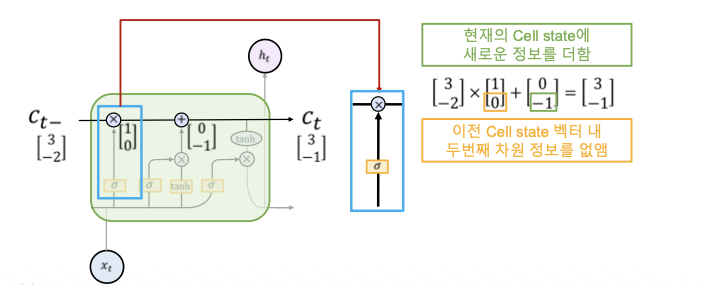
참고: Understanding LSTM Networks
GRU(Gated Recurrent Unit)
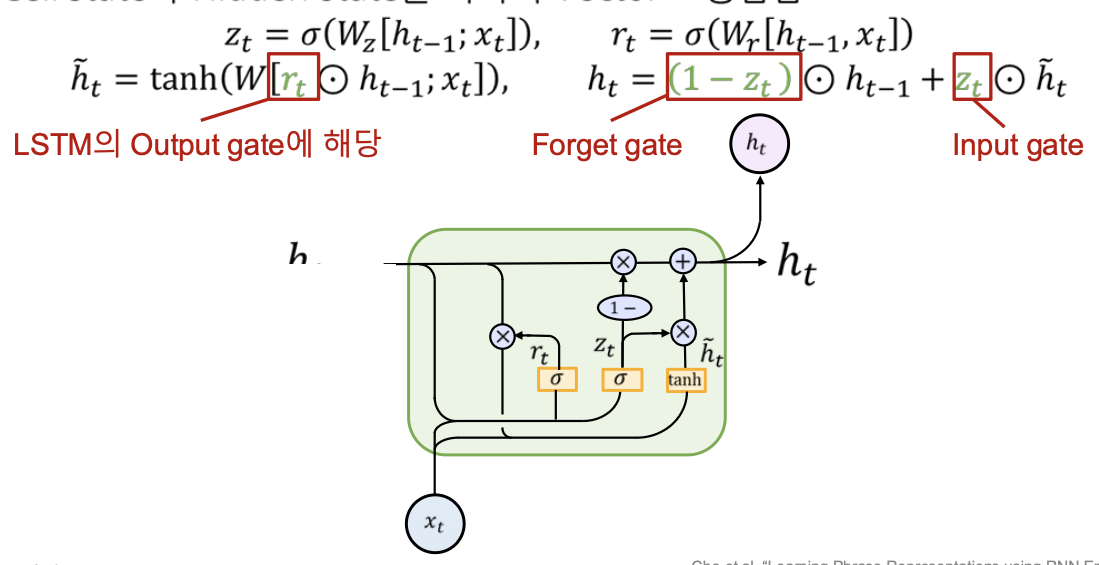
GRU(Gated Recurrent Unit)는 LSTM을 경량화한 모델로 cell state 벡터와 hidden state 벡터를 하나의 벡터로 통합하여 LSTM의 cell state 벡터의 역할을 한다.
이 글은 비밀번호로 보호되어 있습니다.