[BoostCamp AI Tech / ML for RecSys] 최신 RecSys 동향 및 통계학 기본
각종 확률분포와 통계학의 개념 및 활용분야를 정리한 포스트입니다.
추천 시스템 최근 동향
추천시스템 발전 방향은 3가지로 나눌 수 있다.
- Shallow Model : 행렬분해를 통해서 추천시스템을 활용하는 방식이다.

Deep Model : Neural Network를 활용한 모델이다.
- AutoRec
- AutoEncoder 구조로 input에 대해서 다시 reconsturction하는 과정을 학습한다.
- 관측이 되지 않은 데이터도 자연스럽게 복원이 된다.

- DNN
- Neural Network를 깊게 쌓아 학습하는 방식
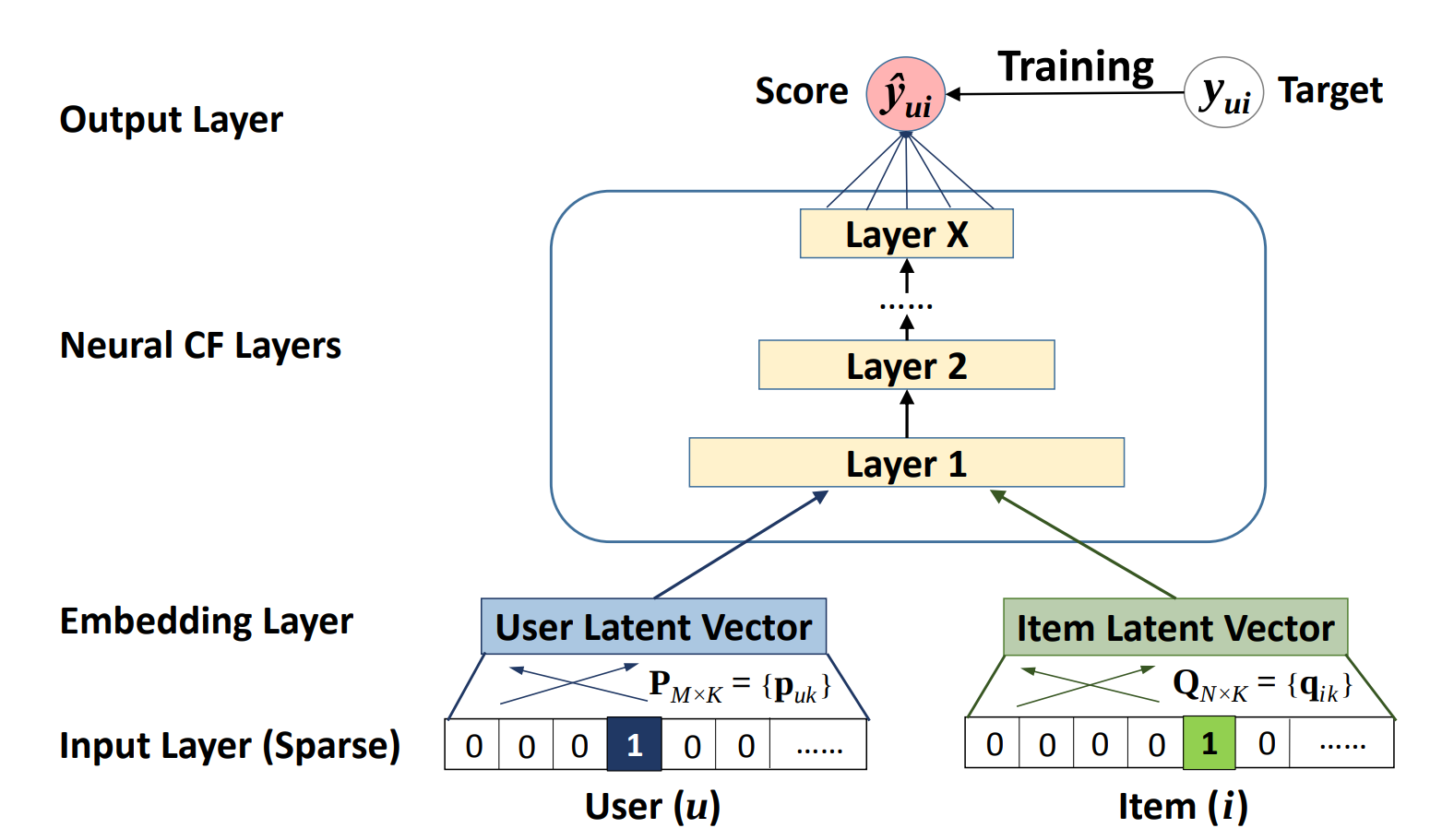
- AutoRec
Large-scale Generative Models
- P5는 T5라는 모델에서 추천 시스템 version 이라고 볼 수 있으며 Text 기반 모델이다.

- 이미지를 다룰 수 있는 멀티모달 모델로도 구현이 가능하다.
- Diffusion 모델 활용
- 특정한 데이터에 대한 일부의 관측값만 주어졌을 때 이 데이터에 노이즈를 주고 이 노이즈를 제거해나가는 과정을 통해 Missing value를 생성하고 그럴듯한 Latent matrix를 만들어낸다.
참고: AutoRec : Auto-encoders Meet Collaborative Filtering
최근 추천시스템에서는 추천 뿐만 아니라 왜 이러한 추천이 일어났는지를 설명하는 것도 중요하다. 이를 Explainability 라고 말한다.
또한, 최근에 활용되는 분야로 Debiasing and Causality 가 있다.
추천시스템의 데이터는 기본적으로 편향성이 가미된 데이터가 대부분이다. 예를 들어, 사용자의 유튜브 데이터는 이미 알고리즘의 영향이 끼친 데이터이고 만약 사용자가 영상을 시청했을 때, 정말로 좋아서 인지 아니면 유명 영상이라서 그냥 클릭했을 수도 있다.
이처럼 여러 편향성을 어떻게 제거할 수 있는지에 대한 방법 중 하나가 Causality(인과성)을 살펴보는 것이다.
생성 모델
Supervised Learning- Data: $(x, y)$
- Goal: $x \rightarrow y$ 로 매핑하는 함수를 학습
Unsupervised Learning- Data: $(x)$
- Goal: 데이터에 숨겨진 구조를 학습
Generative Models- Data: $(x, y)$ or $(x)$
- Goal: 관찰된 여러 샘플들이 추출된 어떠한 분포를 표현하는 모델 학습
- 밀집 추정
Generative Model의 장점은 분포를 통해 새로운 샘플 생성해낼 수 있다. 또한, 생성된 데이터가 어떠한 과정에 의해서 어떠한 분포로 생성이 되었는지 알 수 있다.
변분 추론
생성 모델을 학습하기 위해서는 별도의 과정이 필요하다. 주어진 데이터가 있을 때, 이 데이터를 가장 잘 설명할 수 있는 모델 파라미터를 추론하는 방식으로 학습을 한다.
\[\begin{align*} &\text{The model : } p_{\theta}(x) \\ &\text{The data : } D = \{ x_1, \ldots, x_n \} \\ &\text{Maximum likelihood : } \theta \leftarrow \text{argmax}_{\theta} \frac{1}{N} \sum_{i} log \ p_{\theta} (x_i) \end{align*}\]이 방식을 수행하기 어렵기 때문에 근사하는 방식으로 해결을 하며 이를 variational inference(변본 추론) 이다.
마르코프 연쇄 몬테카를로 방법
생성 모델을 학습하는 또 다른 방법으로 Markov Chain Monte Carlo(MCMC) 가 있다.
MCMC는 가지고 있는 샘플들을 이용해 모집단의 분포가 어떻게 형성이 되었을 지 그리고 이 분포에서 어떻게 데이터를 샘플링을 할 수 있을 지를 추론한다.
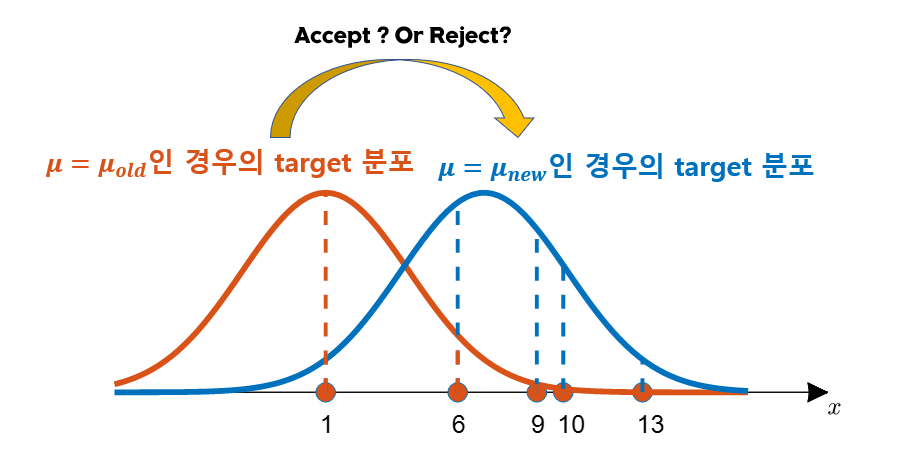
데이터의 가치측정 및 해석
또 다른 방법으로는 데이터의 가치 측정과 인과 추론 이 있다.
Data attribution는 training data instance 마다 가치(value)를 측정하는 방식이다.
Machine Learning Model은 기본적으로, training data로 학습하고, test data에 대해 평가한다.
모델은, training data에서 얻은 knowledge를 기반으로, test data 예측을 진행하고 그 까닭에, test data에 대한 우리 모델의 output을 해석하기 위해서는, training data에 대한 분석이 필요하다.
이 방식은 굉장히 다양한 Vision/NLP Task에서 활용한다.
- Explainability
- 상황: test data x에 대하여, 우리모델이 output y를 도출
- Explainability: 우리모델이 output y를 도출한 이유는 무엇일까?
- Data attribution을 활용하면, test data x에 대하여 output y를 도출하는데에, 가장 크게 기여한 training dataset 들을 제시할 수 있음
- Model Diagnosis
- 상황: 극심한 noisy training dataset으로 모델을 학습시켰더니, test 성능이 매우 저조함
- Model Diagnosis: noisy training dataset 중에서, 어떠한 dataset을 제거하고 재학습해야지, test 성능이 개선될 수 있을까?
- Data Attribution을 이용하면, test dataset에 대해서 loss 가 작아지도록 기여하는 정도를 각 training data마다 계산할 수 있음
인과성과 기계학습
인과성이 있는지를 분석하는 방식과 변수들 사이의 인과 관계를 추론하는 방벙이 있다.
통계학 기본
통계학에서 자주 사용하는 용어의 정의에 대해 먼저 알아보자.
Random variable: 입력으로 sample space(가능한 모든 경우의 수)를 real-valued로 매핑시켜주는 함수Distribution(확률분포): 주어진 상황에서 나올 수 있는 모든 $Y$에 대해서 정의해 준 것을 말한다.
이항 분포
이항 분포(Binomial Distribution)는 연속된 n번의 독립적 시행에서 각 시행이 확률 p를 가질 때의 이산 확률 분포이다.
- ex. 동전 던지기
n=1일 때, 즉 한 번의 시행에 대한 분포는 베르누이 분포라고 한다.
이를 수식으로 표현하면 아래와 같이 표현할 수 있다.
\[p(y) = \binom{n}{y} p^yq^{n-y} \ \ \text{where} \ y = 0, 1, \ldots n \ \text{and} \ 0 \le p \le 1\]균등 분포
균등 분포(Uniform Distribution)는 주어진 구간에서 동일한 확률을 가지는 분포를 말한다.
정규분포
정규분포(Normal distribution) 는 연속적인 확률 분포를 나타낼 때 가장 많이 사용되는 분포이며 다른 말로는 가우시안 분포(Gaussian distribution) 라고 한다.
평균과 분산 값이 정규분포 그래프의 모양을 결정하는데 중요한 역할을 한다.
베타 분포
베타 분포(Beta probability distribution) 0에서 1 사이의 값을 샘플링하며 이러한 특징때문에 특정한 확률값을 모델링할 때 많이 사용한다.

베타 분포는 $\alpha$ 와 $\beta$ 의 값에 따라 굉장히 다양한 분포를 가진다.
중심 극한 정리(CLT)
Central Limit Theorem(CLT)는 어떠한 확률분포인지 모르는 모집단에서 표본이 충분히 크다면, 이 표본평균의 분포는 정규분포에 근사한다는 것이다.
이 때, 표본을 추출할 때는 independent 그리고 identically 해야한다.
Likelihood
Likelihood란 n개의 샘플이 주어졌을 때 이 샘플들이 추출될 경향성을 말한다. 이는 아래의 수식으로 표현된다.
여기서 $\theta$는 데이터가 나오게 될 경향성을 가장 잘 설명하는 파라미터이고 이 값을 추정하는 것이 목표이다.
이를 최대우도법(Maximum likelihood estimator, MLE) 라고 말한다.
- ex. 데이터가 추출된 분포가 가우시안 분포이면 이때의 mean과 covariance를 추론이 목표이다.
데이터가 무한 개로 굉장히 많을 때 MLE를 통해 추정한 값이 실제로 ground truth로 근사된다.
참고: 최대우도법(MLE)
또 다른 접근법으로 이 파라미터 $\theta$를 가정할 수 있다. 이러한 가정 또는 믿음을 prior(사전확률) $p(\theta)$ 라고 한다.
관측된 데이터가 있을 때, 여기에 우리가 가정한 파라미터를 결합된 형태를 posterior(사후확률) 이라고 하며 이를 수식으로 표현하면 아래와 같다.
하지만 posterior를 추정하는 것은 쉽지 않기 때문에 변분추론, MCMC를 이용하는 것이다.
이 글은 비밀번호로 보호되어 있습니다.