[파이토치 트랜스포머를 활용한 자연어 처리와 컴퓨터 비전 심층학습] 임베딩(1)
언어 모델 / N-gram / TF-IDF
컴퓨터는 텍스트 자체를 이해할 수 없으므로 텍스트를 숫자로 변환하는 텍스트 벡터화(Text Vectorization) 과정이 필요하다.
텍스트 벡터화란 텍스트를 숫자로 변환하는 과정을 의미한다. 기초적인 텍스트 벡터화로는 원-핫 인코딩(One-Hot Encoding), 빈도 벡터화(Count Vectorization) 등이 있다.
- 원-핫 인코딩: 문서에 등장하는 각 단어를 고유한 색인 값으로 매핑한 후, 해당 색인 위치를 1로 표시하고 나머지 위치를 모두 0으로 표시하는 방식이다.
- ‘I like apples’ 문장과 ‘I like bananas’ 문장을 원-핫 인코딩으로 표현
- I like apples: [1, 1, 1, 0]
- I like bananas: [1, 1, 0, 1]
- ‘I like apples’ 문장과 ‘I like bananas’ 문장을 원-핫 인코딩으로 표현
- 빈도 벡터화: 문서에서 단어의 빈도수를 세어 해당 단어의 빈도를 벡터로 표현하는 방식이다.
- apples라는 단어가 총 4번 등장 → apples의 백터값 = 4
이러한 방법은 단어나 문장을 벡터 형태로 변환하기 쉽고 간단하다는 장점이 있지만, 벡터의 희소성(Sparsity)이 크다는 단점이 있다. 또한, 텍스트의 벡터가 입력 텍스트의 의미를 내포하고 있지 않아 두 문장이 의미론적으로 유사해도 벡터가 유사하게 나타나지 않을 수 있다.
이를 해결하는 방법으로 단어의 의미를 학습해 표현하는 워드 임베딩(Word Embedding) 기법을 사용한다.
- Word2Vec
- fastText
워드 임베딩은 고정된 임베딩을 학습하기 때문에 다의어나 문맥 정보를 다루기 어렵다는 단점이 있어 인공 신경망을 활용해 동적 임베딩(Dynamic Embedding) 기법을 사용한다.
언어 모델
언어 모델(Language Model)이란 입력된 문장으로 각 문장을 생성할 수 있는 확률을 계산하는 모델을 의미한다. 이를 위해 주어진 문장을 바탕으로 문맥을 이해하고, 문장 구성에 대한 예측을 수행한다.
언어모델은 다양한 자연어 처리 분야에서 활용된다.
- 자동 번역
- 음성 인식
- 텍스트 요약
주어진 문장 뒤에 나올 수 있는 문장은 매우 다양하기 때문에 완성된 문장 단위로 확룔을 계산하는 것은 매우 어렵다. 이 문제를 해결하기 위해 하나의 토큰 단위로 예측하는 방법인 자기회귀 언어 모델이 고안됐다.
자기회귀 언어 모델
자기회귀 언어 모델(Autoregressive Language Model)은 입력된 문장들의 조건부 확률을 이용해 다음에 올 단어를 예측한다. 즉, 언어 모델에서 조건부 확률은 이전 단어들의 시퀀스가 주어졌을 때, 다음 단어의 확률을 계산하는 것을 의미한다.
이전에 등장한 모든 토큰의 정보와 문장의 문맥 정보를 파악하여 다음 단어를 생성한다. 다음 단어는 다시 이전 단어를 기반으로 예측이 이루어지며, 이 과정이 반복된다.
\[P(w_t|w_1, w_2, ...,w_{t-1}) = \frac{P(w_1, w_2, w_3, ..., w_t)}{P(w_1, w_2, ..., w_{t-1})}\]언어 모델에서 조건부 확률을 계산하기 위해 이전에 등장한 시퀀스($w_1, w_2, … , w_{t-1}$)를 기반으로 다음 단어($w_t$)의 확률을 계산한다. 위의 수식에 조건부 확률의 연쇄법칙(Chain rule for conditional probability)을 적용한다면 아래의 수식과 같다.
\[P(w_t|w_1, w_2, ..., w_{t-1}) = P(w_1)P(w_2|w_1)...P(w_t|w_1, w_2, ...,w_{t-1})\]언어 모델에서 조건부 확률은 연쇄법칙을 이용해 계산된다. 이전 단어들의 시퀀스가 주어졌을 때, 다음에 등장하는 단어의 확률을 이전 단어들의 조건부 확률을 이용해 계산한다.
모델의 출력값이 다음 모델의 입력값으로 사용되는 특징 때문에 자기회귀라는 이름이 붙였다. 자기회귀 언어 모델은 시점별로 다음에 올 토큰을 예측하는 것이므로 토큰 분류 문제로 정의할 수 있다.
통계적 언어 모델
통계적 언어 모델(Statistical Language Model)은 언어의 통계적 구조를 이용해 문장이나 단어의 시퀀스를 생성하거나 분석한다. 시퀀스에 대한 확률 분포를 추정해 문장의 문맥을 파악해 다음에 등장할 단어의 확률을 예측한다.
일반적으로 통계적 언어 모델은 마르코프 체인(Markov Chain)을 이용해 구현된다.
- 마르코프 체인: 빈도 기반의 조건부 확률 모델 중 하나로 이전 상태와 현재 상태 간의 전이 확률을 이용해 다음 상태 예측
이 방법은 단어의 순서와 빈도에만 기초해 문장의 확률을 예측하기 때문에 생기는 문제점이 있다.
- 문맥을 제대로 파악하지 못하면 불완전하거나 부적절한 결과를 생성
- 한 번도 등장한 적이 없는 단어나 문장에 대해서는 정확한 확률을 예측하기가 어려움 → 데이터 희소성(Data sparsity)
하지만 통계적 언어 모델은 기존에 학습한 텍스트 데이터에서 패턴을 찾아 확률 분포를 생성하므로, 이를 이용하여 새로운 문장을 생성할 수 있으며, 다양한 종류의 텍스트 데이터를 학습할 수 있다. 이 언어 모델은 대규모 자연어 데이터를 처리하는 데 효과적이며, 딥러닝 등의 인공지능 기술이 발전하면서 더욱 강력한 모델을 구현할 수 있게 됐다.
최근 자연어 처리 기법은 언어 모델을 활용해 가중치를 사전 학습한다.
- GPT
- BERT
N-gram
가장 기초적인 통계적 언어 모델은 N-gram모델이다. N-gram 모델은 텍스트에서 N개의 연속된 단어 시퀀스를 하나의 단위로 취급하여 특정 단어 시퀀스가 등장할 확률을 추정한다.
- 입력 텍스트를 N개의 토큰으로 묶어서 분석하고 연속된 N개의 단어를 하나의 단위로 취급하여 추론하는 모델
- N = 1인 경우: 유니그램(Unigram)
- N = 2인 경우: 바이그램(Bigram)
- N = 3인 경우: 트라이그램(Trigram)
- N > 3인 경우: N-gram
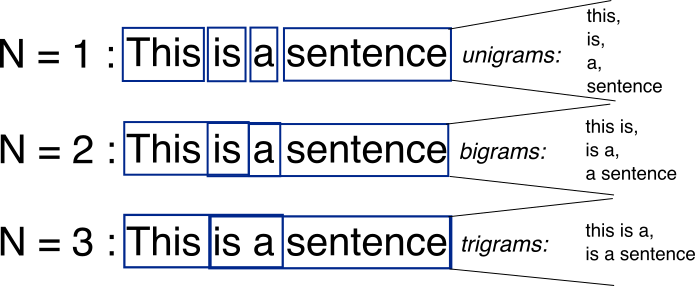
N-gram 언어 모델은 모든 토큰을 사용하지 않고 $N-1$개의 토큰만을 고려해 확률을 계산한다.
\[P(w_t|w_{t-1}, w_{t-2}, ... , w_{t-N+1})\]- $w_t$: 예측하려는 단어
- $w_{t-1}, … w_{t-N+1}$: 예측에 사용되는 이전 단어
이전 단어들의 개수를 결정하는 $N$의 값을 조정하여 N-gram 모델의 성능을 조정할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# N-gram 구현
import nltk
def ngrams(sentence, n):
words = sentence.split()
ngrams = zip(*[words[i:] for i in range(n)])
return list(ngrams)
sentence = "안녕하세요 만나서 진심으로 반가워요"
unigram = ngrams(sentence, 1)
bigram = ngrams(sentence, 2)
trigram = ngrams(sentence, 3)
# nltk 라이브러리를 이용한 N-gram
unigram = nltk.ngrams(sentence.split(), 1)
bigram = nltk.ngrams(sentence.split(), 2)
trigram = nltk.ngrams(sentence.split(), 3)
N-gram은 작은 규모의 데이터세트에서 연속된 문자열 패턴을 분석하는 데 큰 효과를 보인다. 또한 관용적 표현 분석에도 활용되며 단어의 순서가 중요한 자연어 처리 작업 및 문자열 패턴 분석에 활용된다.
TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency)란 텍스트 문서에서 특정 단어의 중요도를 계산하는 방법으로, 문서 내에서 단어의 중요도를 평가하는 데 사용되는 통계적 가중치를 의미한다. 즉, TF-IDF는 BoW(Bag-of Words)에 가중치를 부여하는 방법이다.
- BoW: 문서나 문장을 단어의 집합으로 표현하는 방법으로, 문서나 문장에 등장하는 단어의 중복을 허용해 빈도를 기록한다.
- BoW를 이용한 벡터화는 모든 단어에 동일한 가중치를 부여한다.

단어 빈도
단어 빈도(Term Frequency, TF)란 문서 내에서 특정 단어의 빈도수를 나타내는 값이다.
문서 내에서 단어가 등장한 빈도수를 계산하며, 해당 단어의 상대적인 중요도를 측정하는데 사용된다.
- ‘movie’라는 단어가 3개의 문서에서 4번 등장: TF = 4
TF 값이 높으면 두 가지 경우로 해석될 수 있다.
- 해당 단어가 특정 문서에서 중요한 역할을 함
- 단어 자체가 특정 문서 내에서 자주 사용되는 단어이므로 전문 용어나 관용어로 간주
TF는 단순히 단어의 등장 빈도수를 계산하기 때문에 문서의 길이가 길어질수록 해당 단어의 TF 값도 높아질 수 있다.
문서 빈도
문서 빈도(Document Frequency, DF)란 한 단어가 얼마나 많은 문서에 나타나는지를 의미한다. 특정 단어가 많은 문서에 나타나면 문서 집합에서 단어가 나타나는 횟수를 계산한다.
- ‘movie’라는 단어가 3개의 문서에서 4번 등장: DF = 3
DF는 단어가 몇 개의 문서에서 등장하는지 계산한다.
- DF 값이 높은 경우: 특정 단어가 많은 문서에서 등장하며 그 단어가 일반적으로 널리 사용되므로 사용 중요도가 낮을 수 있다.
- DF 값이 낮은 경우: 특정 단어가 적은 수의 문서에만 등장한다는 뜻이므로 특정한 문맥에서만 사용되는 단어일 가능성이 있으며, 중요도가 높을 수 있다.
역문서 빈도
역문서 빈도(Inverse Document Frequency, IDF)란 전체 문서 수를 문서 빈도로 나눈 다음에 로그를 취한 값을 말한다. 이는 문서 내에서 특정 단어가 얼마나 중요한지를 나타낸다.
문서 빈도가 높을수록 해당 단어가 일반적이고 상대적으로 중요하지 않다는 의미가 된다. 이를 문서 빈도의 역수를 취하면 단어의 빈도수가 적을수록 IDF 값이 커지게 보정하는 역할을 한다.
→ 문서에서 특정 단어의 등장 횟수가 적으면 IDF는 상대적으로 커진다.
\[IDF(t, D) = log \bigg( \frac{count(D)}{1 + DF(t, D)} \bigg)\]TF-IDF
TF-IDF는 단어 빈도와 역문서 빈도를 곱한 값을 사용한다.
\[TF-IDF(t, d, D) = TF(t,d) \times IDF(t, d)\]문서 내에 단어가 자주 등장하지만, 전체 문서 내에서 해당 단어가 적게 등장한다면 TF-IDF 값은 커진다. 이는 전체 문서에서 자주 등장할 확률이 높은 관사나 관용어 등의 가중치가 낮아진다.
TF-IDF 계산은 파이썬의 사이킷런(Scikit-learn) 라이브러리를 활용한다.
1
2
3
4
5
6
7
8
9
10
11
12
# TF-IDF 클래스
tfidf_vectorizer = sklearn.feature_extraction.text.TfidfVectorizer(
input="content",
encoding="utf-8",
lowercase=True,
stop_words=None,
ngram_range(1, 1),
max_df=1.0,
min_df=1,
vocabulary=None,
smooth_idf=True,
)
- 입력값(
input): 입력될 데이터의 형태를 의미- 기본값으로 설정된
content는 문자열 데이터 혹은 바이트 형태의 입력값을 의미한다. - 파일 객체를 사용한다면
file로 입력하며, 파일 경로를 사용하는 경우filename으로 입력한다.
- 기본값으로 설정된
- 인코딩(
encoding): 바이트 혹은 파일을 입력값으로 받을 경우 사용할 텍스트 인코딩 값을 의미 - 소문자 변환(
lowercase): 입력받은 데이터를 소문자로 변환 여부True로 설정하면 모든 입력 텍스트를 소문자로 변환
- 불용어(
stop_words): 분석에 도움이 되지 않는 의미없는 단어들을 의미하며, 입력받은 단어들은 단어 사전에 추가되지 않음 - N-gram 범위(
ngram_range): 사용할 N-gram의 범위로 (최솟값, 최댓값) 형태로 입력(1, 1)은 유니그램,(1, 2)는 유니그램과 바이그램을 사용
- 최댓값 문서 빈도(
max_df): 전처 문서 중 일정 횟수 이상 등장한 단어는 불용어로 처리- 정수를 입력하면 해당 등장 횟수를 초과해 등장하는 단어를 불용어 처리
- 1 이하의 실수를 입력하면 해당 비율을 초과해 등장한 단어를 불용어 처리
- 최솟값 문서 빈도(
min_df): 전체 문서 중 일정 횟수 미만으로 등장한 단어를 불용어 처리- 최댓값 문서 빈도가 동일 패턴
- 단어 사전(
vocabulary): 미리 구축한 단어사전이 있다면 해당 단어 사전을 사용하지만 입력하지 않는다면 자동으로 TF-IDF학습 시 구축 - IDF 분모처리(
smooth_idf): IDF 계산 시 분모에 1을 더함
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# TF-IDF 계산
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
"That movie is famous movie",
"I like that actor",
"I don't like that actor"
]
tfidf_vectorizer = TfidfVectorizer()
tfidf_vectorizer.fit(corpus)
tfidf_matrix = tfidf_vectorizer.transform(corpus)
print(tfidf_matrix.toarray()) # (문서 수) * (단어 수)
print(tfidf_vectorizer.vocabulary_) # 딕셔너리의 키, 값
# [[0. 0. 0.39687454 0.39687454 0. 0.79374908 0.2344005 ]
# [0.61980538 0. 0. 0. 0.61980538 0. 0.48133417]
# [0.4804584 0.63174505 0. 0. 0.4804584 0. 0.37311881]]
# {'that': 6, 'movie': 5, 'is':3, 'famous':2, 'like':4, 'actor':0, 'don': 1}
- TF-IDF에서 점수가 가장 높은 값을 세 개만 추려 색인으로 정리: [[2, 3, 5], [0, 4, 6], [0, 1, 4]]
- 단어 사전과 매핑하면 [[famous, is, movie], [actor, like, that], [actor, don, like]]가 된다.
이를 통해 문서마다 중요한 단어만 추출할 수 있으며, 벡터값을 활용해 문서 내 핵심 단어를 추출할 수 있다.
하지만 빈도 기반 벡터화는 문장의 순서나 문맥을 고려하지 않는다. 그러므로 문장 생성과 같이 순서가 중요한 작업에는 부적합하며 벡터가 해당 문서 내의 중요도를 의미할 뿐, 벡터가 단어의 의미를 담고 있지는 않다.