[파이토치 트랜스포머를 활용한 자연어 처리와 컴퓨터 비전 심층학습] 파이토치 기초(1)
텐서 / 가설 / 손실 함수 / 최적화
텐서
텐서(Tensor)란 넘파이 라이브러리의 ndarray 클래스와 유사한 구조로 배열(Array)이나 행렬(Matrix)과 유사한 자료 구조(자료형)다. 파이토치에서는 텐서를 사용하여 모델의 입출력뿐만 아니라 모델의 매개변수를 부호화(Encode)하고 GPU를 활용해 연산을 가속화할 수 있다.
넘파이와 파이토치
- 공통점: 수학 계산, 선형 대수 연산을 비롯해 전치(Tranposing), 인덱싱(Indexing), 슬라이싱(Slicing), 임의 샘플링(Random Sampling) 등 다양한 텐서 연산을 진행할 수 있다.
- 차이점: 파이토치는 GPU 가속(GPU Acceleration)을 적용할 수 있어 CPU 텐서와 GPU 텐서로 나눠지고, 각각의 텐서를 상호 변환하거나 GPU 사용 여부를 설정한다.
텐서의 형태를 시각화하면 다음과 같다.

- 스칼라(Scalar): 크기만 있는 물리량이지만, 0차원 텐서라고 부른다. 모든 값의 기본 형태로 볼 수 있으며 차원은 없다.
- 벡터(Vector): 스칼라 값들을 하나로 묶은 형태로 간주할 수 있으며 (N, )의 차원을 갖는다.
- [1, 2, 3]과 같은 형태로, 파이썬에서 많이 사용하는 1차원 리스트와 비슷하다.
- 행렬(Matrix): 벡터값들을 하나로 묶은 형태로 간주할 수 있으며 (N, M)으로 표현한다.
- [[1, 2, 3], [4, 5, 6]]과 같은 형태로 회색조(Grayscale) 이미지를 표현하거나 좌표계(Coordinate System)로도 활용될 수 있다.
- 배열(Array): 3차원 이상의 배열을 모두 지칭하며, 각각의 차원을 구별하기 위해 N 차원 배열 또는 N 차원 텐서로 표현한다. 즉, 행렬을 세 개 생성해 겹쳐 놓은 구조로 볼 수 있다.
- 배열의 경우 이미지를 표현하기에 가장 적합한 형태를 띤다.
- 이미지의 경우 (C, H, W)로 표현하며, C는 채널, H는 이미지의 높이, W는 이미지의 너비가 된다.
- 4차원 배열: 3차원 배열들을 하나로 묶은 형태이므로 이미지 여러 개의 묶음으로 볼 수 있다. 파이토치를 통해 이미지 데이터를 학습시킬 때 주로 4차원 배열 구조의 형태로 가장 많이 사용한다.
- 이미지의 경우 (N, C, H, W)로 표현한다. N의 경우 이미지의 개수를 의미한다.
텐서 생성
텐서 생성 방법은 torch.tensor() 또는 torch.Tensor()로 생성할 수 있다.
torch.tensor(): 입력된 데이터를 복사해 텐서로 변환하는 함수이다. 즉, 데이터를 복사하기 때문에 값이 무조건 존재해야 하며 입력된 데이터 형식에 가장 작합한 텐서 자료형으로 변환한다.torch.Tensor(): 텐서의 기본형으로 텐서 인스턴스를 생성하는 클래스다. 인스턴스를 생성하기 때문에 값을 입력하지 않는 경우 비어 있는 텐서를 생성한다.
가능한 자료형이 명확하게 표현되는 클래스 형태의 torch.Tensor()를 사용하는 것을 권장한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
# 텐서 생성
import torch
print(torch.tensor([1, 2, 3]))
print(torch.Tensor([[1,2, 3], [4, 5, 6]]))
print(torch.LongTensor([1, 2, 3]))
print(torch.FloatTensor([1, 2, 3]))
# tensor([1, 2, 3])
# tensor([[1., 2., 3.],
# [4., 5., 6.]])
# tensor([1, 2, 3])
# tensor([1., 2., 3.])
torch.tensor()는 자동으로 자료형을 할당하므로 입력된 데이터 형식을 참조해 Int 형식으로 할당torch.Tensor()는 입력된 데이터 형식이 Int형이지만 Float 형식으로 생성됐는데, 이는 기본 유형이 Float이므로 소수점 형태로 변환torch.LongTensor(),torch.FloatTensor(),torch.IntTensor()모두 데이터 형식이 미리 선언된 클래스다.
텐서 속성
텐서의 속성은 크게 형태(shape), 자료형(dtype), 장치(device)가 존재한다.
- 형태: 텐서의 차원을 의미
- 자료형: 텐서에 할당된 데이터 형식
- 장치: 텐서의 GPU 가속 여부를 의미
텐서 연산을 진행할 때 위의 세 가지 속성이 모두 맞아야 작동이 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
import torch
tensor = torch.rand(1, 2)
print(tensor)
print(tensor.shape)
print(tensor.dtype)
print(tensor.device)
# tensor([[0.8522, 0.3964]])
# torch.Size([1, 2])
# torch.float32
# cpu
차원 변환
차원 변환은 가장 많이 사용되는 메서드 중 하나로 머신러닝 연산 과정이나 입출력 변환 등에 많이 활용된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 텐서 차원 변환
import torch
tensor = torch.rand(1, 2)
print(tensor)
print(tensor.shape)
tensor = tensor.reshape(2, 1)
print(tensor)
print(tensor.shape)
# tensor([[0.6499, 0.3419]])
# torch.Size([1, 2])
# tensor([[0.6499],
# [0.3419]])
# torch.Size([2, 1])
텐서의 차원 변환은 reshape() 메서드를 활용할 수 있다.
자료형 설정
텐서에 있어서 자료형은 가장 중요한 요소다.
1
2
3
4
5
6
7
8
9
# 텐서 자료형 설정
import torch
tensor = torch.rand((3, 3), dtype=torch.float)
print(tensor)
# tensor([[0.6837, 0.7457, 0.9212],
# [0.3221, 0.9590, 0.1553],
# [0.7908, 0.4360, 0.7417]])
텐서의 자료형 설정에 입력되는 인수는 torch.* 형태로 할당한다.
torch.float는 32비트 부동 소수점 형식을 갖지만,float은 64비트 부동 소수점을 갖는다. 이는 메모리 필요를 줄일 수 있다.
장치 설정
장치 설정을 정확하게 할당하지 않으면 실행 오류(Runtime Error)가 발새하거나 CPU 연산이 되어 학습하는 데 오랜 시간이 소요된다. 그러므로 모델 학습을 하기 전에 장치 설정을 확인하는 과정이 필요하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 텐서 GPU 장치 설정
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
cpu = torch.FloatTensor([1, 2, 3])
gpu = torch.cuda.FloatTensor([1, 2, 3])
tensor = torch.rand((1, 1), device=device)
print(device)
print(cpu)
print(gpu)
print(tensor)
# cuda
# tensor([1., 2., 3.])
# tensor([1., 2., 3.], device='cuda:0')
# tensor([[0.1998]], device='cuda:0')
torch.cuda.is_available(): CUDA 사용 여부를 확인할 수 있는 함수
애플 실리콘에서는 MPS를 통한 GPU 가속을 적용한다.
device = "mps" if torch.backends.mps.is_available() and torch.backends.mps.is_built() else "cpu"
장치 변환
CPU 장치를 사용하는 텐서와 GPU 장치를 사용하는 텐서는 상호 간 연산이 불가능하다. 하지만 CPU 장치를 사용하는 텐서와 넘파이 배열 간 연산은 가능하며, GPU 장치를 사용하는 텐서와 넘파이 배열 간 연산은 불가능하다.
넘파이 배열 데이터를 학습에 활용하려면 GPU 장치로 변환해야한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 텐서 장치 변환
import torch
cpu = torch.FloatTensor([1, 2, 3])
gpu = cpu.cuda()
gpu2cpu = gpu.cpu()
cpu2gpu = cpu.to("cuda")
print(cpu)
print(gpu)
print(gpu2cpu)
print(gpu2cpu)
print(cpu2gpu)
# tensor([1., 2., 3.])
# tensor([1., 2., 3.], device='cuda:0')
# tensor([1., 2., 3.])
# tensor([1., 2., 3.], device='cuda:0')
장치(device) 간 상호 변환은 cuda와 cpu 메서드를 통해 할 수 있다.
cuda(): CPU 장치로 선언된 값을 GPU로 변환 가능cpu(): GPU 장치로 선언된 값을 CPU로 변환to(): 장치를 간단하게 변환(MPS 장치로 변환도 가능)
넘파이 배열의 텐서 변환
넘파이나 다른 라이브러리의 데이터를 파이토치에 활용하려면 텐서 형식으로 변환해야 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
# 넘파이 배열의 텐서 변환
import torch
import numpy as np
ndarray = np.array([1, 2, 3], dtype=np.uint8)
print(torch.tensor(ndarray))
print(torch.Tensor(ndarray))
print(torch.from_numpy(ndarray))
# tensor([1, 2, 3], dtype=torch.uint8)
# tensor([1., 2., 3.])
# tensor([1., 2., 3.])
# tensor([1, 2, 3], dtype=torch.uint8)
텐서의 넘파이 배열 변환
텐서를 넘파이 배열로 변환하는 방법은 추론된 결과를 후처리하거나 결과값을 활용할 때 주로 사용된다.
1
2
3
4
5
6
7
8
9
10
# 텐서의 넘파이 배열 변환
import torch
tensor = torch.cuda.FloatTensor([1, 2, 3])
ndarray = tensor.detach().cpu().numpy()
print(ndarray)
print(type(ndarray))
# [1, 2, 3,]
# <class 'numpy.ndarray'>
텐서는 기존 데이터 형식과 다르게 학습을 위한 데이터 형식으로 모든 연산을 추적해 기록한다. 이 기록을 통해 역전파(Backpropagation) 등과 같은 연산이 진행돼 모델 학습이 이뤄진다.
텐서를 넘파이 배열로 변환할 때는 detach() 메서드를 적용한다. 이 메서드는 현재 연산 그래프에서 분리된 새로운 텐서를 반환한다.
가설
가설(Hypothesis)이란 어떤 사실을 설명하거나 증명하기 위한 가정으로 두 개 이상의 변수의 관계를 검증 가능한 형태로 기술하여 변수 간의 관계를 예측하는 것을 의미한다. 가설은 어떠한 현상에 대해 이론적인 근거를 토대로 통계적 모형을 구축하며, 데이터를 수집해 해당 현상에 대한 데이터의 정확한 특성을 식별해 검증한다.
- 연구가설(Research Hypothesis): 연구자가 설명하려는 가설로 귀무가설을 부정하는 것으로 설정한 가설을 증명하려는 가성
- 귀무가설(Null Hypothesis): 처음부터 버릴 것을 예상하는 가설이며 변수 간 차이나 관계가 없음을 통계학적 증거를 통해 증명하려는 가설
- 대립가설(Alternative Hypothesis): 귀무가설과 반대되는 가설로, 귀무가설이 거짓이라면 대안으로 참이 되는 가설이다. 즉, 대립가설은 연구가설과 동일하다고 볼 수 있으며 이를 통해 통계적 가설 검정(Statistical Hypothesis Test)을 진행
머신러닝에서의 가설
머신러닝에서의 가설은 통계적 가설 검정이 되며, 데이터와 변수 간의 관계가 있는지 확률론적으로 설명하게 된다. 즉, 머신러닝에서의 가설은 독립 변수(X)와 종속 변수(Y)를 가장 잘 매핑시킬 수 있는 기능을 학습하기 위해 사용한다. 그러므로 독립 변수와 종속 변수 간의 관계를 가장 잘 근사(Approximation)시키기 위해 사용된다.
가설은 단일 가설(Single Hypothesis)과 가설 집합(Hypothesis Set)으로 표현할 수 있다.
- 단일 가설: 입력을 출력에 매핑하고 평가하고 예측하는 데 사용할 수 있는 단일 시스템을 의미
- $h$로 표현
- 가설 집합: 출력에 입력을 매핑하기 위한 가설 공간(Hypothesis Space)으로, 모든 가설을 의미
- $H$로 표현
임의의 독립 변수(X)와 종속 변수(Y)의 값과 그 값을 시각화하면 다음과 같다.
파란색 점은 임의의 데이터이고 붉은색 선은 가설을 의미하며 선형 회귀를 통해 계산된 값이며, 수식으로 나타내면 다음과 같다.
- 수학적 표현: $y=ax+b$
- $a$: 기울기
- $b$: 절편
- 머신러닝 표현: $H(x)=Wx + b$
- $H(x)$: 가설(Hypothesis)
- $W$: 가중치(Weight)
- $b$: 편향(Bias)
가설은 회귀 분석과 같은 알고리즘을 통해 최적의 가중치와 편향을 찾는 과정이며 학습이 진행될 때마다 가중치와 편향이 지속해서 바뀌게 된다.
마지막으로 학습이 된 결과를 모델(Model)이라 부르며, 이 모델을 통해 새로운 입력에 대한 결과값을 예측(Prediction)한다.
통계적 가설 검정 사례
대표적인 통계적 가설 검정은 t-검정(t-test)이 있으며, 두 가지 범주로 더 세분화할 수 있다.
- 쌍체 t-검정(paired t-test): 동일한 항목 또는 그룹을 두 번 테스트할 때 사용
- ex. 동일 집단에 대한 약물 치료 전후 효과 검정, 동일 집단에 대한 학습 방법 전후 효과 검정에 활용
- 비쌍체 t-검정(unpaired t-test): 등분산성(homoskedasticity)을 만족하는 두 개의 독립적인 그룹 간의 평균을 비교하는 데 사용
- ex. 제약 연구에서 서로 다른 두 개의 독립적인 집단(실험군, 대조군) 간에 유의미한 차이가 있는지 조사
머신러닝의 통계적 가설을 적용한다면 비쌍체 t-검정을 사용해야 한다.
- 독립 변수(X)와 종속 변수(Y) 사이에 유의미한 차이가 있는지 검정
- 변수들의 샘플 데이터는 독립항등분포(independent and identically distributed)를 따름
ex. 사람의 키(cm)가 성별과 관련 있는지 비쌍체 t-검정을 수행
- 귀무가설: $\mu_{man} = \mu_{woman}$
- 대립가설: $\mu_{man} \not= \mu_{woman}$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 성별에 따른 키 차이 검정
import numpy as np
import pandas as pd
import seaborn as sns
from scipy import stats
from matplotlib import pyplot as plt
man_height = stats.norm.rvs(loc=170, scale=10, size=500, random_state=1)
woman_height = stats.norm.rvs(loc=150, scale=10, size=500, random_state=1)
X = np.concatenate([man_height, woman_height])
Y = ["man"] * len(man_height) + ["woman"] * len(woman_height)
df = pd.DataFrame(list(zip(X, Y)), columns=["X", "Y"])
fig = sns.displot(data=df, x="X", hue="Y", kind="kde")
fig.set_axis_labels("cm", "count")
plt.show()
stats.norm.rvs는 특정 평균(loc)과 표준편차(scale)를 따르는 분포에서 데이터를 샘플링하는 함수이다.
- 남성(man)의 평균 키가 여성(woman)의 평균 키보다 높다는 것을 확인할 수 있다.
통계적으로 키(Y)가 성별 차이(X)에 유의미한 요소인지 비쌍체 t-검정으로 확인할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
# 비쌍체 t-검정
statistic, pvalue = stats.ttest_ind(man_height, woman_height, equal_var=True)
print("statistic: ", statistic)
print("pvalue: ", pvalue)
print("*: ", pvalue < 0.05)
print("**: ", pvalue < 0.001)
# statistic: 31.96162891312776
# pvalue: 6.2285854381989205e-155
# *: True
# **: True
성별 차이에 대한 유의미성을 판단하기 위해 통계량(statistic) 또는 유의 확률(pvalue)을 확인한다.
- 통계량이 크고 유의 확률이 작도면 귀무가설이 참일 확률이 낮다.(=’ 남녀 키의 평균이 서로 같다.’의 확률이 낮다고 할 수 있음)
- 유의 확률이 0.05보다 작으면
*표기로 유의하다고 간주 - 유의 확률이 0.001보다 작으면
**표기로 더 많이 유의하다고 판다.
출력 결과의 유의 확률(pvalue)이 매우 작기 때문에 사람의 키(X)가 성별을 구분하는 데 매우 유의미한 변수라는 것을 확인할 수 있다.
손실 함수
손실 함수(Loss Function)는 단일 샘플의 실제값과 예측값의 차이가 발생했을 때 오차가 얼마인지 계산하는 함수를 의미한다. 인공 신경망은 실제값과 예측값을 통해 계산된 오차값을 최소화해 정확도를 높이는 방법으로 학습이 진행된다. 이때 각 데이터의 오차를 계산하는데, 이떄 손실 함수를 사용한다. 다른 말로는 목적함수(Objective Function), 비용함수(Cost Function)라고 부르기도 한다.
- 목적함수: 함숫값의 결과를 최댓값과 최솟값으로 최적화하는 함수
- 비용 함수: 전체 데이터에 대한 오차를 계산하는 함수
포함 관계는 $손실 함수 \in 비용 함수 \in 목적 함수$의 포함 관계를 갖는다.
모집단에서 X의 값을 $H(x) = Wx + b$에 넣어 값을 구하면 예측값이 되며, 오차는 (실제값 - 예측값)이 된다.
오차를 통해 예측값이 얼마나 실제값을 잘 표현하는지 알 수 있다. 하지만 개별 데이터에 대한 오차를 확인할 수 있는 방법으로 가설이 얼마나 실제값을 정확하게 표현하는지는 알 수 없다. 그러므로 실제값을 가설이 얼마나 잘 표현하는지 계산해야한다.
제곱 오차
제곱 오차(Squared Error, SE)는 실제값에서 예측값을 뺀 값의 제곱을 의미한다.
\[SE = (Y_i - \hat{Y_i})^2\]- 오차의 방향보다는 오차의 크기가 중요하여 제곱을 취함
- 절댓값이 아닌 제곱을 취하는 이유는 오차가 큰 값을 더 두드러지게 확대시키기 떄문에 오차의 간극을 빠르게 확인
오차 제곱합
오차 제곱합(Sum of Squared for Error,SSE)은 제곱 오차를 모두 더한 값을 의미한다.
\[SSE = \sum_{i=1}^{n}(Y_i - \hat Y_{i})^2\]평균 제곱 오차
평균 제곱 오차(Mean Squared Error, MSE) 방법은 단순하게 오차 제곱합에서 평균을 취하는 방법이다. 평균값을 사용하지 않는 경우 오차가 많은 것인지 데이터가 많은 것인지 구분하기가 어려워지므로 모든 데이터의 개수만큼 나누어 평균을 계산한다.
\[MSE = \frac{1}{n} \sum_{i=1}^{n}(Y_i - \hat Y_{i})^2\]평균 제곱 오차는 가설의 품질을 측정할 수 있으며, 오차가 0에 가까워질수록 높은 품질을 갖게 된다. 주로 회귀 분석에서 많이 사용되는 손실 함수이며, 최대 신호 대 잡음비(Peak Signal-to-noise ratio, PSNR)를 계산할 때도 사용된다.
MSE에 루트(Root)를 씌우는 경우에는 평균 제곱근 오차(Root Mean Squared Error, RMSE)가 된다. 루트를 통해 평균 제곱 오차에서 발생한 왜곡을 감소시키면 정밀도(Precision)를 표현하기에 적합한 형태가 된다.

단, 오차에 제곱을 적용해 오차량이 큰 값을 크기 부풀렸기 때문에 왜곡이 발생한다.
교차 엔트로피
교차 엔트로피(Cross-Entropy)는 이산형 변수를 위한 손실 함수이다. 교차 엔트로피는 실제값의 확률분포와 예측값의 확률분포 차이를 계산한다.
\[CE(y, \hat y) = -\sum_j y_jlog \hat{y_j}\]- 실제 확률분포: $y$
- 예측된 확률분포: $\hat y$
최적화
최적화(Optimization)란 손실(목적) 함수의 결과값을 최적화하는 변수를 찾는 알고리즘을 의미한다. 손실 함수의 값을 최소가 되는 변수를 찾는다면 새로운 데이터에 대해 더 정교한 예측을 할 수 있다.
최적화 알고리즘은 실제값과 예측값의 차이를 계산해 오차를 최소로 줄일 수 있는 가중치와 편향을 계산한다.
여기서 최적의 가중치와 편향을 갖는 가설은 오차값이 0에 가까운 함수가 되며 이는 가중치와 오차에 대한 도함수의 변화량이 0에 가깝다는 의미다. 즉, 가중치와 오차에 대한 그래프의 극값(Extreme Value)이 가설을 가장 잘 표현하는 가중치와 오차가 된다.
가설 $H(x) = wx + b$
손실함수
\((y - \hat{y})^2 = {y - (wx + b)}^2 \\ = y^2 - 2y(wx+b) + (wx + b)^2 \\ = w^2x^2 + 2wxb + b^2 - 2wxy - 2yb + y^2\)
위의 식에서 변수는 w이므로, 위 함수는 1개의 최적해를 갖는 이차 함수 형태인 것을 알 수 있다.
그러므로, 손실함수의 개형은 아래와 같다.

손실함수의 그래프에서 기울기(Gradient)가 0에 가까워질 때 최적의 가중치를 갖는 것을 알 수 있다.
기울기가 0인 지점을 향해 이동을 해야한다. 이 떄 현재 지점에서 0으로 가기 위해서 어느 방향으로 얼마나 아동을 해야 하는지 알 수 없기 때문에 최적화 방법을 사용한다.
경사 하강법
경사 하강법(Gradient Descent)이란 함수의 기울기가 낮은 곳으로 계속 이동시켜 극값에 도달 할 때까지 반복하는 알고리즘이다. 함수의 기울기가 가장 낮은 곳에 도달한다면 최적의 해를 갖게 된다.
\[W_0 = Initial \ Value \\ W_{i+1} = W_{i} + \alpha \nabla f(W_{i})\]경사 하강법을 포함한 최적화 함수들은 초기값(W_0)을 설정해 다음 가중치(W_1, W_2, …)를 찾는다.
- $\nabla f(W_i)$는 앞의 기울기를 의미
- 새로운 가중치는 기울기의 부호와 관계없이 기울기가 0인 방향으로 학습이 진행
- 기울기가 0을 갖게 되는 가중치를 찾을 때까지 반복
- $\alpha$는 기울기가 한 번에 이동하는 간격(Step Size)을 조정
가중치 갱신 방법
가설과 손실 함수는 아래와 같다.
\[\hat{Y_i} = W_i \times x + b_i \\ MSE(W, b) = \frac{1}{n}\sum_{i=1}^{n}(Y_i - \hat{Y_i})^2\]가중치를 갱신할 때 W에 대해 편미분을 진행한다.
가중치 갱신 방법을 일반화하면 다음과 같다.
\[W_{i+1} = W_i + \alpha \times E[(\hat{Y_i} - Y_i) \times x]\]학습률
가중치를 갱신할 때 $\alpha$를 곱해 가중치 결과를 조정하는 것을 확인했다. 머신러닝에서는 $\alpha$ 값을 학습률(Learning Rate)이라고 한다. 초기값(W_0)을 임의의 값으로 설정해 주듯이 이 학습률($\alpha$)도 임의의 값으로 설정한다.
학습률에 따라 다음 가중치($W_{1}$, $W_{2}$, …)의 변화량이 결정되며, 이에 따라 최적의 해를 찾기 위한 반복 횟수가 결정된다. 만약 적절하지 않은 학습률을 선택하면 너무 많은 반복이 필요하거나, 아무리 반복을 시도해도 최적의 해를 찾기 어려울 수 있다.
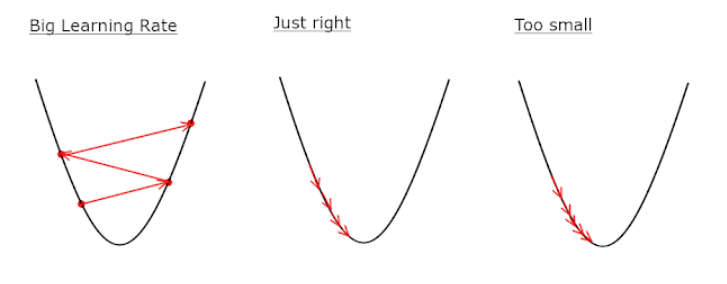
최적화 문제
학습률을 너무 낮거나 높게 잡으면 최적의 가중치를 찾는 데 오랜 시간이 걸리거나, 그래프가 발산하여 아예 값을 찾지 못할 수 있다. 학습률을 낮게 잡고 많은 연산을 하더라도 최적의 가중치를 찾을 수 있는 것처럼 보이지만 찾지 못할 수도 있다.
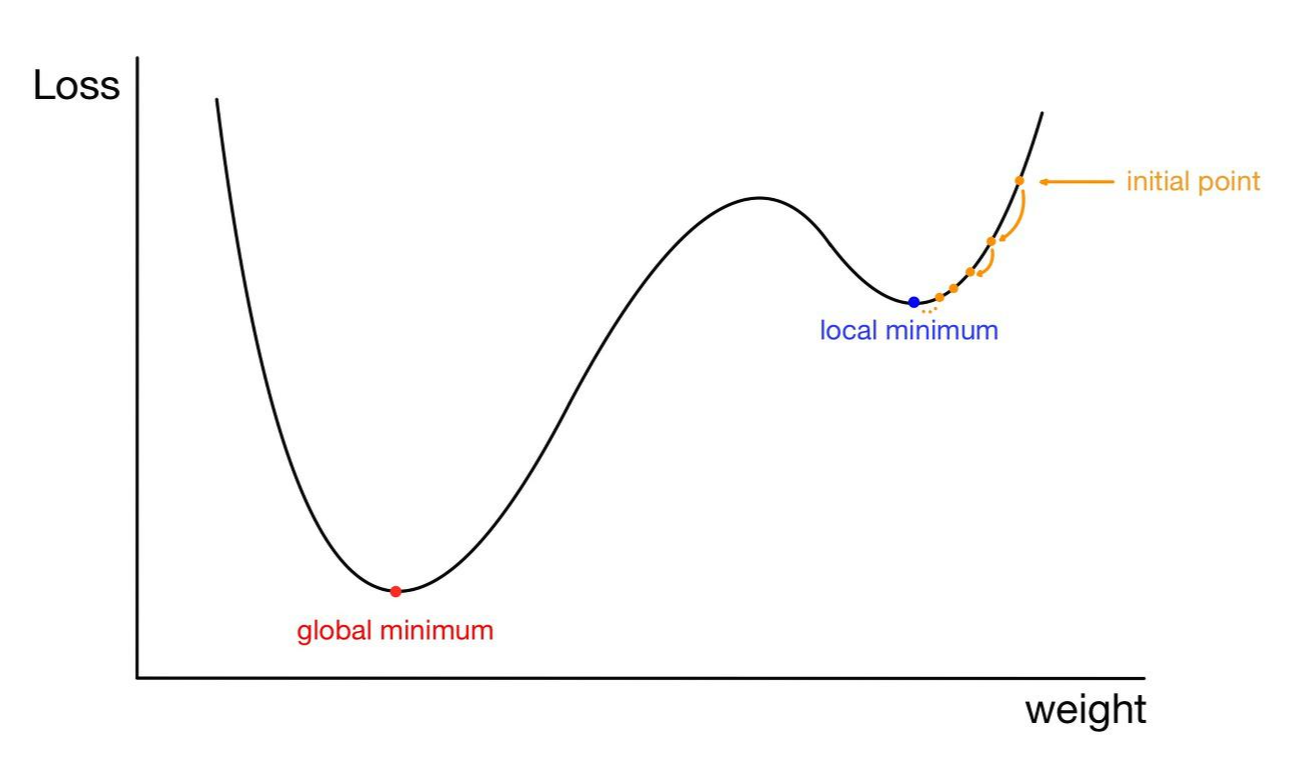
기울기가 0이 되는 지점은 극값은 최댓값(Global Maximum), 최솟값(Global Minimum), 극댓값(Local Maximum), 극솟값(Local Minimum)으로 구분할 수 있다. 초기 가중치나 학습률을 설정할 때 시작점이 적절하지 않거나 학습률이 너무 낮으면 최솟값이 아닌, 극솟값에서 가중치가 결정될 수 있다.
즉, 학습률을 너무 낮게 잡으면 극소 지점을 넘지 못해 지역적 최솟값으로 가중치가 결정된다. 또한 안장점(Saddle Point)이 존재하는 함수에서도 적절한 가중치를 찾을 수 없다.

안장점은 특정 방향(아래에서 위로, 위에서 아래로)에서 바라볼 경우 최댓값(또는 극댓값)이 되지만, 다른 방향에서 보면 최솟값(또는 극솟값)이 되는 지점을 의미한다.
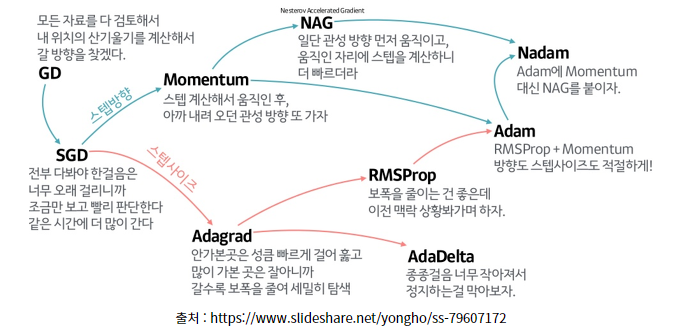
최적화 알고리즘은 경사 하강법처럼 목적 함수가 최적의 값을 찾아갈 수 있도록 최적화되게끔 하는 알고리즘이다. 어떤 최적화 알고리즘을 사용하느냐에 따라 모델의 정확도가 달라진다.
학습에 사용하는 데이터의 형태나 가설, 손실 함수 등에 따라 적합한 최적화 알고리즘을 사용해야 하며 앞의 극소 문제와 안장점 문제 등에 강건한 기법도 존재한다.
경사 하강법 이외에도 다양한 최적화 알고리즘이 있다.
단순 선형 회귀: 넘파이
넘파이를 활용해 지도 학습 중 하나인 단순 선형 회귀를 구현할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# 데이터 선언(넘파이)
import numpy as np
x = np.array(
[[1], [2], [3], [4], [5], [6], [7], [8], [9], [10],
[11], [12], [13], [14], [15], [16], [17], [18], [19], [20],
[21], [22], [23], [24], [25], [26], [27], [28], [29], [30]]
)
y = np.array(
[[0.94], [1.98], [2.88], [3.92], [3.96], [4.55], [5.64], [6.3], [7.44], [9.1],
[8.46], [9.5], [10.67], [11.16], [14], [11.83], [14.4], [14.25], [16.2], [16.32],
[17.46], [19.8], [18], [21.34], [22], [22.5], [24.57], [26.04], [21.6], [28.8]]
)
# 하이퍼 파리미터 초기화
weight = 0.0
bias = 0.0
learning_rate = 0.005
# 에폭 설정
for epoch in range(10000):
# 가설과 손실 함수 선언
y_hat = weight * x + bias
cost = ((y - y_hat) ** 2).mean()
# 가중치와 편향 갱신(넘파이)
weight = weight - learning_rate * ((y_hat - y) * x).mean()
bias = bias - learning_rate * (y_hat - y).mean()
# 학습 기록 출력
if (epoch + 1) % 1000 == 0:
print(f"Epoch: {epoch + 1:4d}, Weight: {weight:.3f}, Bias : {bias:.3f}, Cost: {cost:.3f}")
weight: 가중치($W_0$)bias: 편향learning_rate: 학습률epoch: 에폭은 인공 신경망에서 순전파와 역전파 과정 등의 모델 연산을 전체 데이터세트가 1회 통과하는 것을 의미- 각 에폭은 모델이 데이터를 학습하고 가중치를 갱신하는 단계를 나타내며, 여러 에폭을 반복해 모델을 학습
초기값에 따른 학습 결과
초기값의 설정은 학습에 큰 영향을 끼친다. 초기값을 할당했을 때 하이퍼파라미터 튜닝을 진행하며, 하이퍼파라미터 튜닝을 통해 원할한 학습을 진행할 수 있다.
단순 선형 회귀: 파이토치
넘파이가 아닌 파이토치를 이용해서 단순 선형 회귀를 구현할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# 프레임워크 선언
import torch
from torch import optim # 최적화 함수가 포함돼 있는 모듈
# 데이터 선언(파이토치)
x = torch.FloatTensor(
[[1], [2], [3], [4], [5], [6], [7], [8], [9], [10],
[11], [12], [13], [14], [15], [16], [17], [18], [19], [20],
[21], [22], [23], [24], [25], [26], [27], [28], [29], [30]]
)
y = torch.FloatTensor(
[[0.94], [1.98], [2.88], [3.92], [3.96], [4.55], [5.64], [6.3], [7.44], [9.1],
[8.46], [9.5], [10.67], [11.16], [14], [11.83], [14.4], [14.25], [16.2], [16.32],
[17.46], [19.8], [18], [21.34], [22], [22.5], [24.57], [26.04], [21.6], [28.8]]
)
# 하이퍼파라미터 초기화
weight = torch.zero(1, requires_grad=True)
bias = torch.zero(1, requires_grad=True)
learning_rate = 0.001
# 최적화 선언
optimizer = optim.SGD([weight, bias], lr=learning_rate)
# 에폭, 가설, 손실 함수 선언
for epoch in range(10000):
hypothesis = x * weight + bias
cost = torch.mean((hypothesis - y) ** 2)
# 가중치와 편향 갱신
optimizer.zero_grad()
cost.backward()
optimizer.step()
if (epoch + 1) % 1000 == 0:
print(f"Epoch : {epoch+1:4d}, Weight: {weight.item():.3f}, Bias : {bias.item():.3f}, Cost : {cost.:3f}")
requires_grad: 모든 텐서에 대한 연산을 추적하며 역전파 메서드를 호출해 기울기를 계산하고 저장- 파이토치에서 지원하는 자동 미분(Autograd) 기능의 사용 여부
optim.SGD(): 확률적 경사 하강법으로 일부 데이터만 계산하여 빠르게 최적화된 값을 찾는 방식- 변수(
params)와 학습률(lr)로 최적화를 적용1 2 3 4 5
optimizer = torch.optim.SGD( params, lr, **kwargs )
- 변수(
zero_grad(), cost.backward(), optimizer.step()
zero_grad(): 파라미터 초기화cost.backward(): 역전파 계산optimizer.step(): 확률적 경사 하강법을 수행한 결과를 파라미터에 반영
신경망 패키지
신경망 패키지는 torch.nn에 포함돼 있으며 from torch import nn의 형태로 선언한다.
1
2
3
4
5
6
7
8
# 선형 변환 클래스
layer = torch.nn.Linear(
in_features,
out_features,
bias=True,
device=None,
dtype=None
)
선형 변환 클래스는 $y = Wx + b$ 형태의 선형 변환을 입력 데이터에 적용한다.
in_features: 입력 차원 크기out_features: 출력 데이터 차원 크기bias: 계층에 편향 값 포함 여부
1
2
3
4
5
6
7
8
9
10
11
12
13
# 모델 선언
model = nn.Linear(1, 1, bias=True)
criterion = torch.nn.MSELoss() # 평균 제곱 오차 계산
learning_rate = 0.001
# 순방향 연산
for epoch in range(10000):
output = moddel(x)
cost = criterion(output ,y)
optimizer.zerop_grad()
cost.backward()
optimizer.step()