[BoostCamp AI Tech / Pytorch] Tensor 생성과 조작
Tensor의 생성과 변형에 사용된는 함수 및 메서드 정리 포스트입니다.
Tensor의 생성
Tensor를 생성하는 방법은 굉장히 다양하다.
특정한 값으로 초기화된 Tensor 생성 & 변환
Tensor을 생성할 때 특정한 값을 정하여 초기화할 수 있다.
- 0으로 초기화된 Tensor를 생성하는 표현
torch.zeros([2, 3, 4])
- 1로 초기화된 Tensor를 생성하는 표현
torch.ones([1, 2, 5])
생성 뿐만 아니라 특정한 값으로 변환하여 Tensor를 생성하는 것도 가능하다.
- 크기와 자료형이 같은 0으로 초기화된 Tensor로 변환하는 표현
torch.zeros_like(e)
- 크기와 자료형이 같은 1로 초기화된 Tensor로 변환하는 표현
torch.ones_like(b)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
import torch
# 0으로 초기화된 Tensor 생성
torch.zeros(5) # tensor([0., 0., 0., 0., 0.])
# 1로 초기화된 Tensor 생성
torch.ones(3) # tensor([1., 1., 1.])
a = torch.ones([3, 2])
b = torch.zeros([2, 3])
# 크기와 자료형이 같은 0으로 초기화된 Tensor로 변환
torch.zeros_like(a)
"""
tensor([[0., 0.],
[0., 0.],
[0., 0.]])
"""
# 크기와 자료형이 같은 1로 초기화된 Tensor로 변환
torch.ones_like(b)
"""
tensor([[1., 1., 1.],
[1., 1., 1.]])
"""
난수로 초기화된 Tensor 생성 & 변환
특정한 값이 아니라 난수로 초기화된 Tensor를 생성할 수도 있다.
- [0, 1] 구간의 연속균등분포 난수 Tensor 생성
torch.rand([2, 3])- 파라미터 초기화를 하는 경우
- 무작위 데이터를 생성하는 경우
연속균등분포: 특정한 두 경계값 사이의 모든 값에 대해 동일한 확률을 가지는 확률분포르 두 경계값은 [0, 1] 사이에 존재해야한다.
\[f(x) = \frac{1}{b-a} (a \le x \le b)\]연속균등분포의 모수는 다음과 같다.
- 평균(기대값): $\mu = \frac{a + b}{2}$
- 분산: $\sigma^2 = \frac{(a-b)^2}{12}$
- 표준편차: $\sigma = \sqrt{\frac{(a-b)^2}{12}} = \frac{a-b}{2\sqrt{3}}$
- 표준정규분포에서 추출한 난수로 Tensor 생성
torch.randn([3, 2])
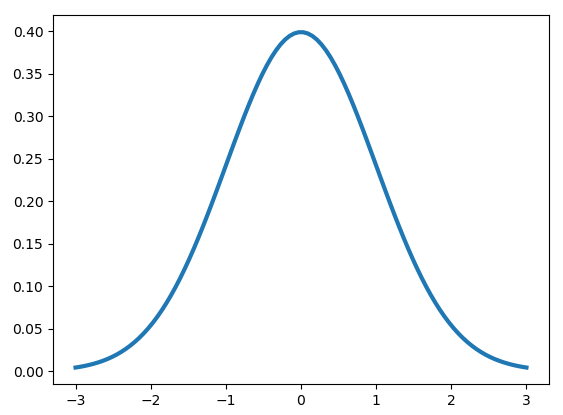
표준정규분포: 평균이 0이고 표준편차가 1인 종모양의 곡선
\(f(x) = \frac{1}{\sqrt{2\pi}} e^{-\frac{x^2}{2}}\)
- 평균(기대값): $\mu = 0$
- 분산: $\sigma^2 = 1$
- 표준편차: $\sigma = 1$
생성 뿐만 아니라 변환하는 함수 또한 존재한다.
- 크기와 자료형이 같은 연속균등분포 난수 Tensor로 변환
torch.rand_like(k)
- 크기와 자료형이 같은 표준정규분포 난수 Tensor로 변환
torch.randn_like(i)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 연속균등분포 난수 Tensor
torch.rand(3) # tensor([0.9701, 0.3271, 0.2040])
# 표준정규분포 난수 Tensor
torch.randn(3) # tensor([-0.8471, 0.8292, -0.4368])
k = torch.randn(3)
i = torch.rand(3)
# 크기와 자료형이 같은 연속균등분포 난수 Tensor로 변환
torch.rand_like(k) # tensor([0.8607, 0.4303, 0.1227])
# 크기와 자료형이 같은 표준정규분포 난수 Tensor로 변환
torch.randn_like(i) # tensor([-0.1718, -0.5145, 0.7640])
지정된 범위 내에서 초기화된 Tensor 생성
지정된 범위를 정하여 일정한 간격을 가지는 Tensor를 생성할 수 있다.
torch.arange(start=1, end=4, step=0.5)
초기화되지 않은 Tensor 생성
초기화 되지 않은 Tensor를 생성하는 방법도 존재한다.
여기서 초기화되지 않은 Tensor는 생성된 Tensor의 각 요소가 명시적으로 다른 특정한 값으로 설정되지 않았음을 의미하고 해당 Tensor는 메모리에 이미 존재하는 임의의 값들로 채워진다.
초기화되지 않은 Tensor을 사용한는 이유는 다음과 같다.
- 성능 향상: 초기 값을 설정하는 단계는 불필요한 자원을 소모
- 메모리 최적화: 불필요한 초기화는 메모리 사용량을 증가시키므로 필요한 계산만 사용하여 메모리 효율성을 높일 수 있음
대표적인 방법은 다음과 같다.
torch.empty(5)
위의 방법처럼 생성된 초기화 되지 않은 Tenso는 torch.fill_(3.0) 함수를 호출해 요소를 채울 수 있다.
list, Numpy 데이터로부터 Tensor 생성
Python의 List와 Numpy 데이터로부터 Tensor을 생성할 수 있다.
- List 데이터로부터 Tensor 생성
torch.tensor(l)
- Numpy 데이터로부터 Tensor 생성
torch.from_Numpy(u).float()float()를 붙이는 이유는 기본적으로 생성된 데이터가 정수형이기 때문에 변환이 필요함
List와 Numpy 차이점: List는 가변적인 컨테이너 데이터타입이며 연산 및 조작에 적합하지 않은 반면 Numpy는 대규모 다차원 배열 연산이 가능하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import numpy as np
s = [1, 2, 3, 4, 5]
u = np.array([[0, 1],
[2, 3]])
# list를 Tensor로 변환
torch.tensor(s) # tensor([1, 2, 3, 4, 5])
# Numpy를 Tensor로 변환
torch.from_numpy(u).float()
"""
tensor([[0., 1.,],
[2., 3.]])
"""
CPU Tensor 생성
- 정수형 CPU Tensor 생성
torch.IntTensor([1, 2, 3, 4])
- 실수형 CPU Tensor 생성
torch.FloatTensor([1, 2, 3, 4])
- 8비트 부호 없는 정수형 CPU Tensor 생성:
torch.ByteTensor - 16비트 부호 있는 정수형 CPU Tensor 생성:
torch.CharTensor - 64비트 부호 있는 정수형 CPU Tensor 생성:
torch.LongTensor - 64비트 부호 있는 실수형 CPU Tensor 생성:
torch.DoubleTensor
Tensor의 복제
Tensor를 복제하는 코드 표현으로 clone()과 detach()가 있다. 차이점은 detach()는 계산 그래프에서 분리하여 새로운 Tensor을 얻는다는 것이다.
1
2
3
4
5
6
import torch
x = torch.tensor([1, 2, 3, 4, 5])
y = x.clone()
z = x.detach()
CUDA Tensor 생성과 변환
GPU: 그래픽 처리 장치를 의미하며 대규모 데이터 처리와 복잡한 계산을 위해 사용된다.
- 데이터가 CPU에 있는지 GPU에 있는지를 확인할 수 있다.
a.device
- 현재 환경이 CUDA 기술을 사용할 수 있는지 확인하기 위해서는
torch.cuda.is_available()로 확인이 가능하다. - CUDA 이름을 확인할 때는
torch.cuda.get_device_name(device=0)를 사용한다. - Tensor를 GPU에 할당할 때 쓰는 코드는 다음과 같다.
torch.tensor([1, 2, 3, 4]).to('cuda')torch.tensor([1, 2, 3, 4]).cuda()
- GPU에 할당된 Tensor를 CPU Tensor로 변환하는 코드는 다음과 같다.
b.to(device='cpu')b.cpu()
Tensor의 indexing & slicing
Pytorch에서 index는 Tensor의 각각의 요소 값을 참조하기 위해서 사용한다.
2-D Tensor의 indexing을 표현할 때는 행과 열의 index를 모두 필요로 한다.
- ex. 0번째 index행, 1번째 index열의 요소:
b[0, 1]
Pytorch에서 slicing은 생성된 Tensor의 여러 개의 요소 값을 가져오기 위해서 사용한다.
1-D Tensor의 slicing 표현은 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
a = torch.tensor([10, 20, 30, 40, 50, 60])
print(a[1:4]) # a[-5:-2]와 동일
# tensor([20, 30, 40])
print(a[1:]) # a[-5:]와 동일
# tensor([20, 30, 40, 50, 60])
print(a[:])
# tensor([10, 20, 30, 40, 50, 60])
print(a[0:5:2]) # a[-6:-1:2] or a[:5:2]와 동일
# tensor([10, 30, 50])
2-D Tensor의 slicing은 아래와 같이 사용할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
b = torch.tensor([[10, 20, 30],
[40, 50, 60]])
print(b[0, 1:]) # b[0, -2:]와 동일
# tensor([20, 30])
print(b[:, 1:]) # b[:, -2:]와 동일
"""
tensor([[20, 30],
50, 60])
"""
print(b[1, ...]) # b[1, :] or b[-1, ...] or b[-1, :]
# tensor([40, 50, 60])
Tensor의 모양 변경
Pytorch에서는 여러 함수와 메서드를 활용하여 Tensor의 모양변경을 할 수 있다.
view() & reshape()
Pytorch에서 Tensor의 모양을 변경하는 메서드로 view()와 reshape()가 있다.
이 둘의 차이점은 view() 메서드는 Tensor의 메모리가 연속적으로 할당된 경우만 사용 가능하지만 reshape() 메서드는 연속적이지 않아도 사용가능하다.
이런 특징으로만 봤을 때, view()보다 유연성이 좋은 reshape()만을 사용해도 된다고 생각할 수도 있지만, reshape() 메서드는 성능 저하의 단점이 있다. 메모리의 연속성이 확실하고 성능이 중요한 경우는 view() 메서드를 사용하는 것이 좋다.
Tensor가 연속적인지 확인하는 코드로는 a.is_contiguous()가 있다. 만약 연속적이면 True를 연속적이지 않으면 False를 출력한다. 연속적인 Tensor로 변화시키려면 a.contiguous()를 사용하여 연속적인 Tensor를 생성할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import torch
c = torch.tensor([[0, 1, 2],
[3, 4, 5]])
d = c[:, :2]
# 연속성 확인
print(c.is_contiguous()) # True
print(d.is_contiguous()) # False
# view 메서드
d_contiguous = d.contiguous()
print(d_contiguous.view(1, -1)) # tensor([0, 1, 3, 4])
# reshape 메서드
print(d.reshape(1, -1)) # tensor([0, 1, 3, 4])
flatten()
Tensor를 평탄화하는 모양 변경 방법으로 flatten() 함수를 사용할 수 있다. flatten()함수는 특정 차원의 범위를 선택하여 평탄화하는 것도 가능하다.
이 함수는 다차원 데이터 처리에 유용하며 데이터를 신경망 모델에 적합한 형태로 전처리할 때 활용한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import torch
k = torch.randn(3, 2, 2)
l = torch.flatten(k) # k.flatten() 표현 가능
print(l.shape) # torch.Size([12])
l = torch.flatten(k, 1)
print(l.shape) # torch.Size([3, 4])
l = torch.flatten(k, 2)
print(l.shape) # torch.Size([3, 2, 2])
m = torch.flatten(k, 0, 1)
print(m.shape) # torch.Size([6, 2])
transpose()
transpose()는 Tensor의 특정한 두 차원의 축을 서로 바꾸는 메서드이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
s = torch.tensor([[[0, 1],
[2, 3],
[4, 5]],
[[6, 7],
[8, 9],
[10, 11]],
[[12, 13],
[14, 15],
[16, 17]]])
t = s.transpose(1, 2) # 1차원 축과 2차원 축을 변경
print(t)
"""
tensor([[[ 0, 2, 4],
[ 1, 3, 5]],
[[ 6, 8, 10],
[ 7, 9, 11]],
[[12, 14, 16],
[13, 15, 17]]])
"""
squeeze() & unsqueeze()
squeeze() 함수는 dim이 1인 특정 차원을 축소시키는 함수이며 unsqeeze() 함수는 반대로 dim이 1인 특정 차원을 확장시키는 함수이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
u = torch.randn(1, 1, 4)
# squeeze() 함수
w = torch.squeeze(u)
print(w.shape) # torch.Size([4])
w = torch.squeeze(u, dim = 1)
print(w. shape) # torch.Size([1, 4])
v = torch.randn(3, 4)
# unsqueeze() 함수
x = torch.unsqueeze(v, dim = 0)
print(x.shape) # torch.Size([1, 3, 4])
x = torch.unsqueeze(v, dim=1)
print(x.shape) # torch.Size([3, 1, 4])
x = torch.unsqueeze(v, dim=2)
print(x.shape) # torch.Size([3, 4, 1])
stack()
stack() 함수는 Tensor들을 결합할 때 사용한다.
이 때 Tensor들을 어떤 차원을 기준으로 결합할 지 지정할 수도 있다.

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
x = torch.tensor([[1, 2],
[3, 4]])
y = torch.tensor([[5, 6],
[7, 8]])
z = torch.tensor([[9, 10],
[11, 12]])
a = torch.stack((x, y, z))
print(a.shape) # torch.Size([3, 2, 2])
b = torch.stack((x, y, z), dim = 1)
print(b.shape) # torch.Size([2, 3, 2])
c = torch.stack((x, y, z), dim = 2)
print(c.shape) # torch.Size([2, 2, 3])
cat()
Tensor를 결합하는 함수로는 stack()과 cat()이 있다. 차이점은 stack()은 새로운 차원을 생성하지만, cat() 함수는 기존의 차원을 유지하면서 Tensor들을 연결한다.
Cat 함수 - 차원이 동일(2차원 → 3차원)

Stack 함수 - 새로운 차원 생성(2차원 → 3차원)

cat() 함수를 이용해 연결하려는 Tensor들은 모두 같은 차원을 가져야하며 어떤 차원을 기준으로 Tensor을 결합할 지 지정할 수 있지만, 주의할 점은 행의 개수(또는 열의 개수)가 동일해야한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import torch
a = torch.tensor([[0, 1],
[2, 3]])
b = torch.tensor([[-1, -2]])
# dim = 0을 기준으로 결합
print(torch.cat((a, b)))
"""
torch.tensor([[0, 1],
[2, 3],
[-1, -2]])
"""
# dim = 1을 기준으로 결합
print(torch.cat(a, b.reshape(2, 1)), 1) # 행의 개수를 맞추기 위해 reshape() 사용
"""
torch.tensor([[0, 1, -1],
[2, 3, -2]])
"""
expand()
expand() 메서드를 활용하면 Tensor의 크기를 확장할 수 있다. 이 때, 어떤 크기의 Tensor로 확장할 지 지정한다.
이 함수를 활용하려면 행 또는 열의 크기가 1이어야 가능하다.
1
2
3
4
5
6
7
8
9
10
import
a = torch.tensor([[2, 3, 4]])
b = a.expand(4, 3)
"""
tensor([[2, 3, 4],
[2, 3, 4],
[2, 3, 4],
[2, 3, 4]])
"""
repeat()
repeat() 메서드는 Tensor의 요소들을 반복해서 크기를 확장하는데 사용한다.
expand()와 다른 점은 Tensor의 차원 중 일부의 크기가 1이어야 하는 제한이 없다. 하지만, 추가 메모리를 할당하기 때문에 메모리를 할당하지 않는 expand() 메서드보다 메모리 효율성이 떨어진다.
1
2
3
4
5
6
7
8
9
10
11
12
13
import torch
h = torch.tensor([[1, 2],
[3, 4]])
i = h.repeat(2, 3) # dim = 0 축으로 2번 확장 + dim = 1 축으로 3번 확장
print(i)
"""
tensor([[1, 2, 1, 2, 1, 2],
[3, 4, 3, 4, 3, 4],
[1, 2, 1, 2, 1, 2],
[3, 4, 3, 4, 3, 4]])
"""
이 글은 비밀번호로 보호되어 있습니다.