[BoostCamp AI Tech / Pytorch] Tensor 연산 및 심화
Tensor의 기본 연산부터 벡터·행렬 연산, 노름과 유사도, 그리고 2차원 행렬 곱셈 및 활용까지 다루는 포스트입니다.
Tensor 기본 연산
Tensor의 기본 연산으로 산술 연산, 비교 연산, 논리 연산이 있다.
산술 연산
- 더하기 연산: 두 텐서의 각각의 요소를 더한다.
torch.add(a, b)- in-place 방식:
a.add_(b) - 크기가 다른 Tensor끼리 더하게 되면 크기가 작은 Tensor가 크기가 큰 Tensor의 동일한 크기로 확장하여 연산을 수행한다. 이를
Broadcasting이라고 말한다.
- 뺄셈 연산: 두 텐서의 각각의 요소를 뺀다.
torch.sub(a, b)- in-place 방식:
a.sub_(b) - 뺄셈에서도 Broadcasting이 일어나 크기가 다른 Tensor끼리 뺄 수 있다.
in-place 방식은 메모리를 절약할 수 있지만, autograd와의 호환성에서 문제를 일으킬 수 있다.
- 스칼라곱 연산: Tensor의 각 요소에 동일한 스칼라 값을 곱하는 연산을 의미한다.
- i는 스칼라, j는 Tensor:
torch.mul(i, j)
- i는 스칼라, j는 Tensor:
- 요소별 곱하기 연산: 두 텐서의 각각의 요소를 곱한다.
torch.mul(k, l)- in-place 방식:
k.mul(l) - 요소별 곱하기에서도 Broadcasting이 일어나 크기가 다른 Tensor끼리 요소별 곱셈을 할 수 있다.
- 요소별 나누기 연산: 두 텐서의 각각의 요소를 나눈다.
torch.div(o, p)- in-place 방식:
o.div_(p) - 요소별 나누기에서도 Broadcasting이 일어나 크기가 다른 Tensor끼리 요소별 나누기를 할 수 있다.
- 요소별 거듭제곱 연산: Tensor의 각각의 요소들을 다른 Tensor의 각각의 요소들의 값만큼 거듭제곱한다.
torch.pow(t, u), 이 때u는 텐서, 스칼라 모두 가능함.- in-place 방식:
t.pow_(u)
- 요소별 거듭제곱근 연산: 요소별 거듭제곱 연산에 사용된 함수를 그대로 사용함
torch.pow(t, 1/n)
비교 연산
- Tensor v의 요소들과 Tensor w의 대응요소들이 같은지를 비교하고 이를 Boolean Tensor로 출력
torch.eq(v, w)- 출력 예시:
tensor([True, False, True, True])
- Tensor v의 요소들과 Tensor w의 대응요소들이 다른지를 비교하고 이를 Boolean Tensor로 출력
torch.ne(v, w)
- Tensor v의 요소들과 Tensor w의 대응요소들 보다 큰지를 비교하고 이를 Boolean Tensor로 출력
torch.gt(v, w)
- Tensor v의 요소들과 Tensor w의 대응요소들이 크거나 같은지를 비교하고 이를 Boolean Tensor로 출력
torch.ge(v, w)
- Tensor v의 요소들과 Tensor w의 대응요소들이 작은지를 비교하고 이를 Boolean Tensor로 출력
torch.lt(v, w)
- Tensor v의 요소들과 Tensor w의 대응요소들이 작거나 같은지를 비교하고 이를 Boolean Tensor로 출력
torch.le(v, w)
논리 연산
기초적인 논리 연산으로는 논리곱(AND), 논리합(OR), 배타적 논리합(XOR) 연산이 있다.
- 논리곱: x와 y 모두 참일 때 참
torch.logical_and(x, y)
- 논리합: x 또는 y 둘 중 하나라도 참이면 참
torch.logical_or(x, y)
- 배타적 논리합: x 또는 y 중 하나만 참일 때 참
torch.logical_xor(x, y)
Tensor 벡터와 행렬 연산
Tensor의 노름
1-D Tensor의 크기를 비교할 때 요소의 개수가 더 많다고 해서 크기가 더 크다고 말할 수 있을까?
이를 정확하게 판단하기 위해서 사용되는 것이 Norm이다.
1-D Tensor의 노름에는 L1 노름, L2 노름 , L$\infty$ 노름가 있다.
L1-norm: 1-D Tensor에 포함된 요소의 절대값의 합으로 정의할 수 있다.- 맨해튼 노름이라고도 한다.
- $x = [x_1, x_2, \ldots, x_n]$ 일 때, 수식은 다음과 같음
torch.norm(a, p = 1), a는 Tensor
L2-norm: 1-D Tensor에 포함된 요소의 제곱합의 제곱근으로 정의할 수 있다.- 유클리드 노름이라고도 한다.
- $x = [x_1, x_2, \ldots, x_n]$ 일 때, 수식은 다음과 같음
torch.norm(a, p = 2), a는 Tensor
L-infinity: 1-D Tensor에 포함된 요소의 절대값 중 최대값으로 정의할 수 있다.- $x = [x_1, x_2, \ldots, x_n]$ 일 때, 수식은 다음과 같음
torch.norm(a, p = float('inf')), a는 Tensor
노름의 유형에 따라 각 노름이 1인 점들의 집합을 좌표평면에 표현하면 다음과 같다.

유사도
유사도란 두 1-D Tensor(=Vector)가 얼마나 유사한지에 대한 측정값을 의미한다.
이러한 유사도는 군집화 알고리즘(Clusting)에서 데이터들이 얼마나 유사한지를 판단하는 중요한 기준이 된다.
맨해튼 유사도: 두 1-D Tensor 사이의 맨해튼 거리를 역수로 변환하여 계산한 값- 맨해튼 거리의 값이 작아질 수록 맨해튼 유사도의 값이 커지며 유사도가 1에 가까울수록 두 Tensor가 유사하다고 판단함
- 맨해튼 거리 :
manhattan_distance = torch.norm(a - b, p = 1) - 맨해튼 유사도 :
1/(1 + manhattan_distance)
유클리드 유사도: 두 1-D Tensor 사이의 유클리드 거리를 역수로 변환하여 계산한 값- 두 Tensor 사이의 유클리드 거리의 값이 작아질수록 유클리드 유사도의 값은 커지며 유사도가 1에 가까울수록 두 Tensor가 유사하다고 판단
- 유클리드 거리 :
euclidean_distance = torch.norm(a - b, p = 2) - 유클리드 유사도 :
1 / (1 + euclidean_distance)
코사인 유사도: 두 1-D Tensor 사이의 각도를 측정하여 계산한 값- 코사인 유사도의 값이 1에 가까울수록 두 Tensor가 유사하다고 판단
- 1-D Tensor 사이의 각도는 내적(dot product or inner product)을 활용
Tensor의 내적
1-D Tensor의 내적은 두 1-D Tensor 사이의 관계를 하나의 0-D Tensor(=Scalar)로 변환하는 것이다.
- 두 1-D Tensor의 각 요소를 곱해서 더하는 방법
- $<x, y> = x_1 \cdot y_1 + x_2 \cdot y_2 + \cdots + x_n \cdot y_n$
torch.dot(x, y)- 두 1-D Tensor의 길이를 곱하는 방법
- $<x, y> = \lVert x \rVert _2 \lVert y \rVert _2 cos \theta$
위의 수식을 이용해 코사인 유사도 수식을 표현하면 아래와 같다.
\[cos(x, y) = \frac{<x, y>}{\lVert x \rVert _2 \lVert y \rVert _2}\]이를 코드로 표현하면
cosine_similarity = torch.dot(b, c) / (torch.norm(b, p = 2)) * (torch.norm(c, p = 2))
이다.
2-D Tensor의 행렬 곱셈 연산
2-D Tensor(=Matrix)의 행렬 곱셈은 두 행렬을 결합하여 새로운 행렬을 생성하는 연산이다.
이 연산은 신경망 구현에 핵심이 되는 연산이다.
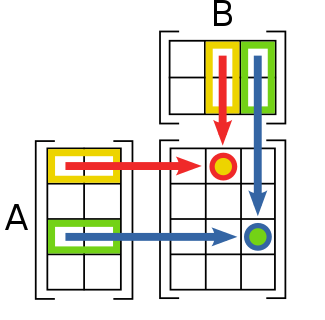
이를 간단히 수식으로 표현하면 다음과 같이 표현할 수 있다.
\[D \times E = \sum_l (f_{il} \cdot g_{li})\]2-D Tensor의 행렬 곱셈 연산을 코드로 구현하면 다음과 같이 구현할 수 있다.
D.matmul(E)D.mm(E)D@E
2-D Tensor의 행렬 곱셈 연산 활용
대표적으로는 흑백 이미지의 대칭 이동이 있으며 주어진 축을 기준으로 이미지를 뒤집는다.
1
2
3
4
5
6
7
8
9
10
11
import torch
G = torch.tensor([[255, 114, 140],
[39, 255, 46],
[61, 29, 255]])
H = torch.tensor([[0, 0, 1],
[0, 1, 0],
[1, 0, 0]])
I = G @ H # 좌우 대칭
K = H @ G # 상하 대칭
이 글은 비밀번호로 보호되어 있습니다.