[BoostCamp AI Tech / Pytorch] 이진 분류
이진 분류 모델의 학습 과정과 경사하강법 및 데이터 처리 과정을 다루는 포스트입니다.
이진 분류란 주어진 트레이닝 데이터를 사용하여 특징 변수와 목표 변수(두 가지 범주) 사잉의 관계를 학습하고 이를 바탕으로 트레이닝 데이터에 포함되지 않은 새로운 데이터를 사전에 정의된 두 가지 범주 중 하나로 분류하는 모델을 구축하는 과정이다.
- 붓꽃 종류 분류, Iris-versicolor(1) or Iris-setosa (0)
- 이메일 스팸 분류, Spam(1) or Ham(0)
트레이닝 데이터
붓꽃 종류에 대한 데이터셋이 있을 때, 특성 변수는 붓꽃 꽃잎 길이이고 목표 변수는 붓꽃의 종류이다.
트레이닝 데이터의 코드를 표현한면 다음과 같다.
1
2
3
4
5
6
7
import pandas as pd
# 트레이닝 데이터를 불러오기
df = pd.read_csv('Iris.csv', sep=",", header=0)[["PetalLengthCm", "Species"]]
# Species 열의 값이 Iris-setosa와 Iris-versicolor인 행만 필터
filtered_data = df[df['Species'].isin(['Iris_setosa', 'Iris-versicolor'])]
Iris_data의 경우, 목표 변수가 ‘Iris-setosa’ 또는 ‘Iris-versicolor’와 같이 텍스트 데이터(비정형 데이터)이므로 목표 변수를 이산형 레이블로 변환해야한다.
1
2
3
4
5
6
# 이산형 레이블로 변환
filtered_df.loc[:, 'Species'] = filtered_df['Species'].map({'Iris-setosa': 0, 'Iris-versicolor': 1})
# 특징 변수와 목표 변수 추출
x = filtered_df[['PetalLengthCm']].values
t = filtered_df['Species'].values.astype(int)
2차원 배열로 특성 변수를 만들어야 하는 이유는 데이터 표준화할 때 2차원 배열을 요구하기 때문이다.
데이터 분할
트레이닝 데이터: 데이터 모델을 학습시키는 데 사용테스트 데이터: 최종 모델의 성능을 평가하는 데 사용검증 데이터: 모델의 학습 과정 중 성능을 평가하는 데 사용되는 데이터로서, 모델의 1 에포크마다 과적합을 확인하기 위해 사용
분할 비율은 8:1:1 ~ 6:2:2 정도로 데이터를 분할한다.
데이터 분할 코드는 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 데이터 분할
from sklearn.model_selection import train_test_split
x_train, x_test, t_train, t_test = train_test_split(x, t, test_size=0.2, random_state=42)
# 데이터 표준화
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train) # 트레이닝 특징 변수 표준화
t_train = scaler.transform(t_train) # 테스트 특징 변수 표준화
# 데이터를 tensor로 변환
x_train = torch.tensor(x_train ,dtype=torch.float32)
x_test = torch.tensor(x_test, dtype=torch.float32)
t_train = torch.tesnor(t_train, dtype=torch.float32).unsqueeze(1)
t_test = torch.tensor(t_test, dtype=torch.float32).unsqueeze(1)
unsqueeze 함수를 사용하는 이유는 배치 처리를 위해서는 목표 변수의 형태가 [N, 1]이 되어야한다. 또한 손실 함수도 2차원 Tensor 형태를 가지므로 호환성을 위해 2차원 Tensor로 변환해야한다.
Dataset & DataLoader 클래스
Pytorch에서는 데이터의 전처리와 배치 처리를 용이할 수 있도록 Dataset과 DataLoader 클래스를 사용한다.
두 클래스를 가져오는 코드는 from torch.utils.data import Dataset, DataLoader이다.
여기서 배치(Batch)란 무엇일까?
배치는 머신러닝과 딥러닝에서 데이터를 처리하는 묶음 단위를 의미한다. 이러한 배치는 미니 배치 경사하강법 알고리즘에서 사용될 수 있다.

미니 배치 경사 하강법
경사 하강법의 단점인 로컬 미니마, 대규모 데이터셋의 계산 비용 문제와 확률적 경사하강법의 단점인 노이즈와 학습과정의 불안정을 해결하고 두 알고리즘의 장점을 취하기 위한 알고리즘이 미니 배치 경사 하강법이다.
미니 배치 경사 하강법은 각 데이터를 배치 단위로 묶기 때문에 확률적 경사하강법보다 노이즈가 적고, 전체 데이터를 헌 번에 사용하지 않기 때문에 경사하강법보다 계산 속도가 빠르다.
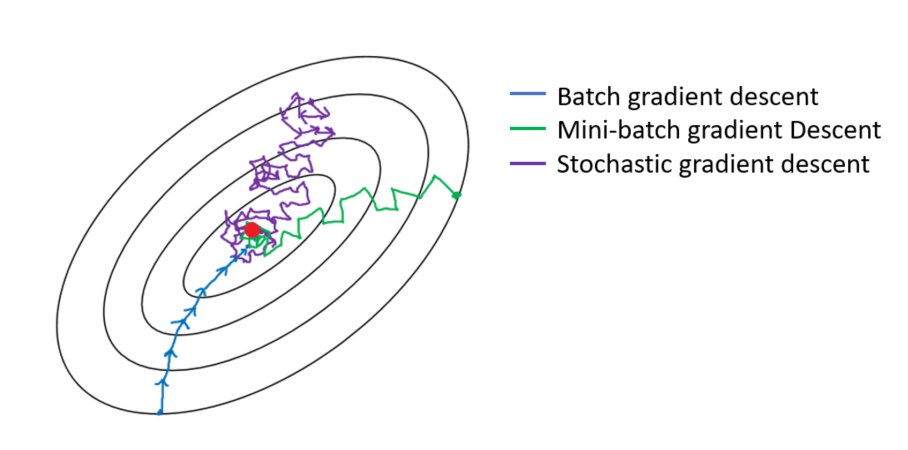
Dataset 클래스
Dataset 클래스는 데이터셋을 정의하는 기본 클래스이다.
CustomDataset 클래스: Dataset을 상속받아 사용자 정의 데이터셋 구축__init__메서드: 데이터 초기화__len__메서드: 데이터의 크기 반환__getitem__메서드: 특정 인덱스의 데이터 샘플을 반환
Dataset 클래스의 코드 표현은 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
from torch.utils.data import Dataset, DataLoader
Class IrisDataset(Dataset):
def __init__(self, features, labels):
self.features = features # 특징 변수
self.labels = labels # 목표 변수
def __len__(self):
return len(self.features) # 특징 변수의 개수
def __getitem(self, idx):
return self.features[idx], self.labels[idx]
DataLoader 클래스
DataLoader 클래스는 Dataset 인스턴스를 감싸서 배치 단위(batch_size)로 데이터를 로드하고, 데이터셋을 섞는(shuffle) 등의 작업을 수행한다.
- 모델 훈련 시에는 데이터의 순서에 따른 편향을 줄이기 위해 데이터를 섞음
- 모델 성능 평가 시에는 데이터의 순서를 유지하는 것이 일반적임
1
2
3
4
5
6
7
8
9
from torch.utils.data import Dataset, DataLoader
train_dataset = IrisDataset(x_train, t_train)
test_dataset = IrisDataset(x_test, t_test)
batch_size = 4
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
이진 분류 모델
이진 분류 모델로 로지스틱 회귀 알고리즘을 사용한다.
로지스틱 회귀 알고리즘란 트레이닝 데이터의 특성과 분포를 바탕으로 데이터를 잘 구분할 수 있는 최적의 결정 경계를 찾아, 시그모이드 함수를 통해 이 경계를 기준으로 데이터를 분류한다.
- 최적의 결정 경계를 찾기 위해서
선형 결정 경계를 찾아야 한다.- 특징 변수 $x$가 회귀의 입력으로 들어가서 $z = Wx + b$로 계산된다.
- 선형 결정 경계를 기준으로 위/아래, 좌/우 로 분류
시그모이드 함수는 비선형 함수로, 입력 값을 0과 1사이의 값으로 변환하는 함수이며 $z$가 시그모이드의 입력으로 들어간다.
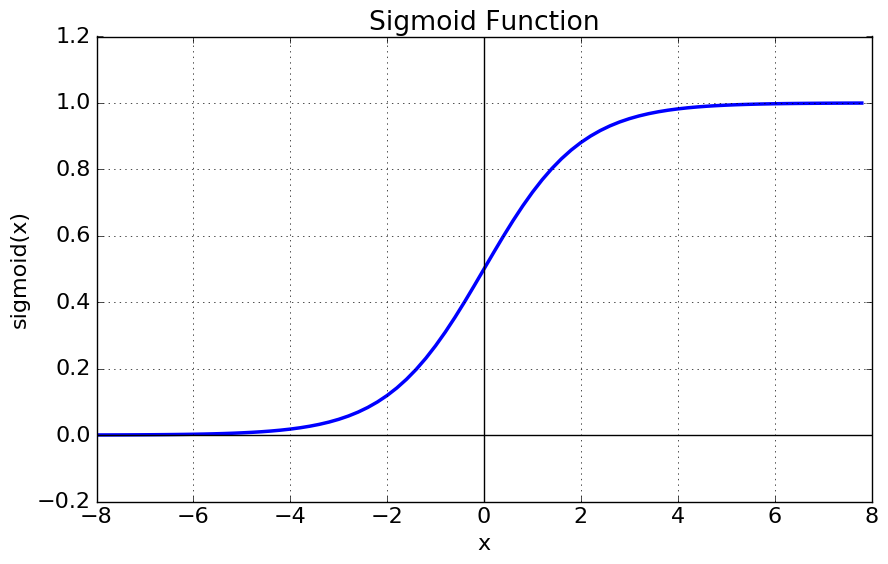
- 시그모이드 출력값이 0.5 이상이면 1로 0.5 미만이면 0으로 분류한다.
- 시그모이드 함수의 결과는 0과 1 사이의 값으로 계산되므로 그 결과를 확률로 해석이 가능하다.(0.64 → 64%)
위의 과정을 코드로 구현하면 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import torch
import torch.nn as nn
class BinaryClassificationModel(nn.Module):
def __init__(self):
super(BinaryClassificationMdoel, self).__init__()
self.layer_1 = nn.Linear(1, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
z = self.layer_1(x)
y = self.sigmoid(z)
return y
model = BinaryClassification()
이진 교차 엔트로피
이진 교차 엔트로피(Binary Cross Entropy, BCE)는 이진 분류 문제에서 모델의 예측 변수와 목표 변수 간의 차이를 측정하기 위해 사용되는 손실 함수이다.
이진 교차 엔트로피는 아래와 같은 함수식으로 표현할 수 있다.
\[E(w, b) = - \sum_{i=1}^n \{t_i log \ y_i + (1 - t_i) log \ (1 - y_i) \}\]이러한 함수식이 나온 이유를 알기 위해서는 조건부 확률과 로그 가능도 함수의 개념에 대해 알아야 한다.
조건부 확률
조건부 확률은 사건 A가 발생한 상황 하에서 다른 사건 B가 발생할 확률을 의미한다.
최대 가능도 추정(MLE)
어떤 데이터가 있을 때, 이 데이터셋을 가장 잘 설명할 수 있는 파라미터(모수)를 추정하는 방법론 또는 절차를 최대 가능도 추정(Maximum Likelihood Extimation) 라고 하며 데이터를 가장 잘 설명하는 모수를 찾기 위해 가능도 함수를 최대화하는 과정을 거친다.
MLE는 데이터 분포에 따라 모수의 값을 추정하는 과정 전체를 가리키며, 최대 가능도 추정 방법을 통해 실제로 계산된 구체적인 모수 값을 최대 가능도 추정치(Maximum Likelihood Estimate)라고 한다.
여기서 추정(Esimation)은 관찰된 데이터를 사용하여 모수의 값을 추정화는 과정을 말하며 이런 모수를 추정하는 이유는 다음과 같다.
- 모델이 주어진 데이터를 가장 잘 설명하도록 하기 위함
- 추정된 모수를 통해 모델을 해석하고 평가하며 최적의 모델을 선택
가능도는 주어인 데이터가 특정 모수 값 하에서 관찰될 확률을 의미한다. 이 값을 최대화하는 방법을 사용하여 모수를 추정한다.
가능도 함수를 그래프로 표현하면 다음과 같다.
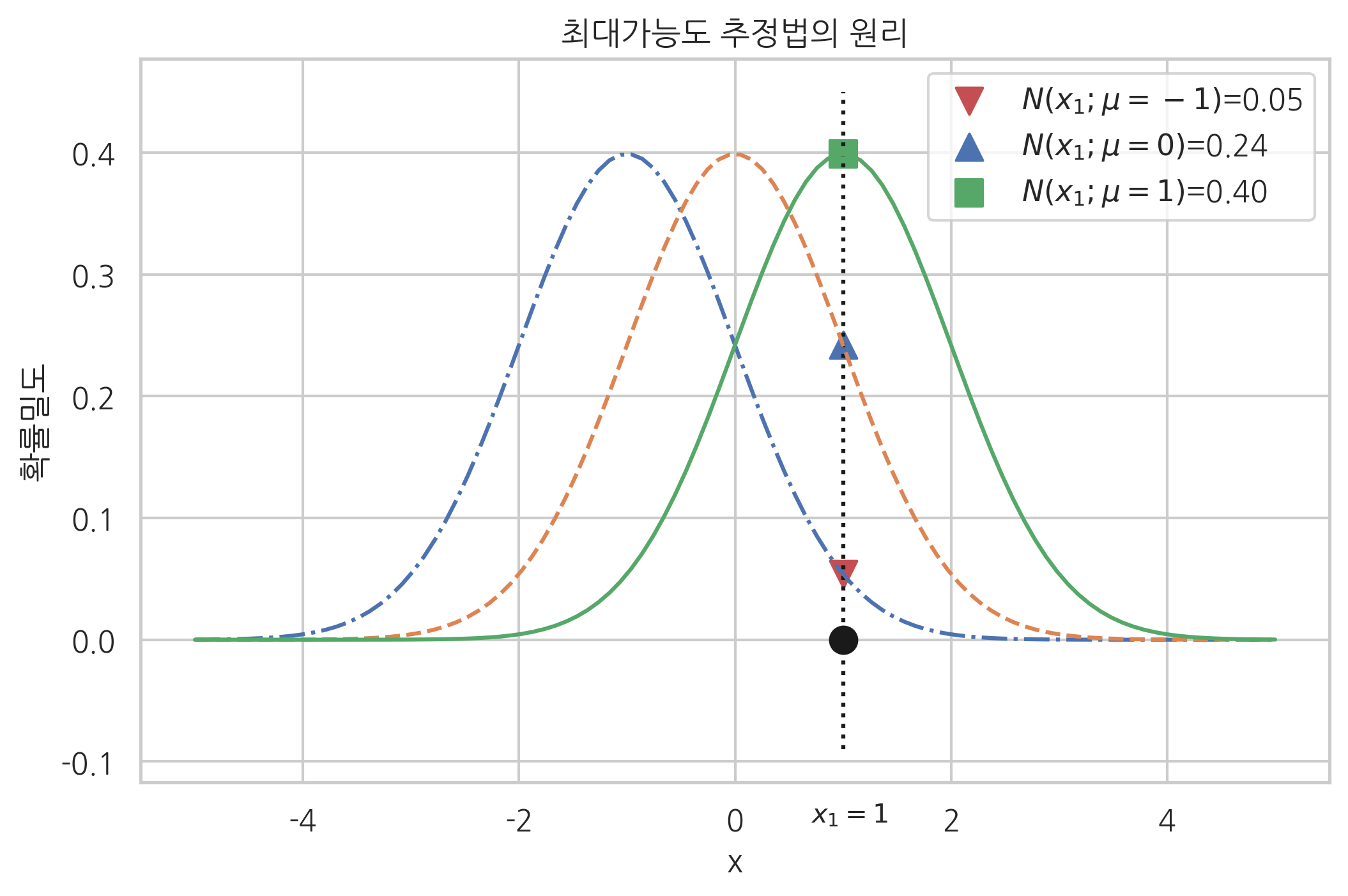
가능도 함수를 수식으로 표현하면 다음과 같이 표현할 수 있다.
\[L(\theta; x_0 = 1) = P(x_0 = 1 | \theta)\]데이터가 한 개가 아니라 여러 개인 경우 수식으로 표현하면 다음과 같다.
\[\begin{align*} L(\theta; X) &= P(x_1, x_2, \cdots, x_n) \\ &= P(x_1 | \theta) \cdot P(x_2 | \theta) \cdots P(x_n | \theta) \ (= L(\theta | x_1) \cdot L(\theta | x_2) \cdots L(\theta | x_n)) \\ &= \prod\nolimits_{i=1}^n P(x_i | \theta) (= \prod\nolimits_{i=1}^n L(\theta | x_i)) \end{align*}\]가능도 함수가 최대값이 되는 모수를 찾는 것이 다음의 목표이다.
\[\hat{\theta}_{MLE} = argmax_{\theta} L(\theta; x_0 = 1)\]최대값을 찾는 방법은 미분계수가 0이 되는 지점을 찾는 것이다.
즉, 찾고자하는 $\theta$ 에 대하여 로그를 취한 로그 가능도 함수를 편미분하고 그 값이 0이 되는 $\theta$를 찾는 과정을 통해 가능도 함수가 최대가 되는 $\theta$를 찾을 수 있다.
로그를 사용하는 이유는 데이터의 숫자 단위를 줄여주며 데이터가 독립일 경우, 곱셈과 나눗셈을 덧셈과 뺄샘으로 바꿔어준다. 또한 확률 값의 범위를 [0, 1]를 $(-\infty, 0]$ 로 확장해주기 때문이다.
이진 교차 엔트로피 유도
위의 개념을 통해 이진 교차 엔트로피는 아래와 같이 유도된다.
입력 값$x$에 대하여 출력 값이 1일 확률(T는 확률 분포)
\[P(T=1|x) = y = sigmoid(Wx + b)\]입력 값$x$에 대하여 출력 값이 0일 확률(T는 확률 분포)
\[P(T=0|x) = 1- P(T=1|x) = 1- y\]
위의 두 수식을 통합하면 아래와 같이 표현할 수 있다.
\[P(T=t|x) = y^t(1-y)^{1-t}\]만약 주어진 데이터가 여러 개이면 다음과 같다.
\[\prod_{i=1}^n P(T=t_i | x_i) = \prod_{i=1}^n y_i^{t_i}(1-y_i)^{1-t_i}\]여기에 로그를 씌우고 최대화 문제를 최소화 문제로 바꿔주기 위해 ‘-‘를 붙이면 아래와 같이 표현이 된다.
\[E(w, b) = -log(\prod{i=1}^n P(T=t_i|x_i)) = - \sum_{i=1}^n \{t_i log \ y_i + (1 - t_i) log \ (1 - y_i) \}\]이를 코드로 표현하면 loss_function = nn.BCELoss() 이다.
이진 분류 모델의 테스트
이진 분류 모델은 테스트는 트레이닝 데이터에 포함되지 않은 새로운 데이터를 사전에 정의된 두 가지 범주 중 하나로 분류한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import torch
# 테스트 데이터 코드
model.eval()
with torch.no_grad():
predictions = model(x_test)
predictions_labels = (predictions > 0.5).float()
# 예측 결과와 실제 라벨 출력 코드
actual_labels = t_test.numpy()
predicted_labels = predicted_labels.numpy()
print(predicted_labels.flatten()) # 비교하기 편하게 하기위해 1차원으로 변환
print(actual_labels.flatten())
# 예측 결과 시각화
plt.figure()
plt.scatter(range(len(actual_labels)), actual_labels, color='blue', label='Actual Labels')
plt.scatter(range(len(predicted_labels)), actual_labels, color='blue', label='Predicted Labels')
plt.legend()
plt.title('Actual vs Predicted Labels')
plt.show()
이 글은 비밀번호로 보호되어 있습니다.