[BoostCamp AI Tech / Pytorch] 선형 회귀
선형 회귀 모델의 학습 과정과 경사하강법 및 데이터 처리 과정을 다루는 포스트입니다.
선형 회귀란 주어진 트레이닝 데이터를 사용하여 특징 변수와 목표 변수 사이의 선형 관계를 분석하고, 이를 통해 모델을 학습시켜, 트레이닝 데이터에 포함되지 않은 새로운 데이터의 결과를 연속적인 숫자 값으로 예측하는 과정을 말한다.
대표적인 예로 임금 예측, 부동산 가격 예측이 있다.
트레이닝 데이터
만약 YearsExperience(연차)에 따른 임금(Salary) 데이터셋이 있을 때, 특징 변수는 YearsExperience이고 목표 변수는 Salary이다.
트레이닝 데이터를 불러오고 특징 변수와 목표 변수를 분리하는 코드는 아래와 같다.
1
2
3
4
5
6
7
import pandas as pd
# 구분자는 ',' 이며 0번째 행을 column 명으로 사용
data = pd.read_csv('Salary_dataset.csv', sep=',', header = 0)
x = data.iloc[:, 1].values
t = data.iloc[:, 2].values
상관 관계 분석
특징 변수와 목표 변수 간의 상관 관계를 분석하면 다음과 같은 정보를 얻을 수 있다.
- 두 변수 간의 선형 관계를 파악
- 그 관계가 양의 관계인지 또는 음의 관계인지 파악
- 높은 상관 관계를 가지는 특징 변수들을 파악(다중 선형 회귀 모델에서 필요)
- 특징 변수가 너무 많은 경우, 모델 구현에 필요하지 않은 변수를 제거하여 모델의 복잡성을 줄이고 성능을 높여줄 수 있다.
상관 관계 분석을 할 때 사용하는 수식은 표본상관계수이다.
표본상관계수는 두 변수가 함께 변화하는 정도를 각각 변화하는 정도로 나누어 두 변수 간의 관계를 파악한다.
이를 코드로 표현하면 np.corrcoef(x, t) 이다.
또한 코드의 결과값은 아래의 표를 참고하여 두 변수간의 상관관계의 정도를 파악하면 된다.

이를 산점도로 시각화하면 아래와 같으며 산점도 그래프를 얻기 위해서는 plt.scatter(x, t)를 사용하면 된다.

선형 회귀 모델 학습을 할 때는 데이터를 2치원 형태로 변환해야하며 이 변환은
view(-1, 1)을 통해 변환할 수 있다.
선형 회귀 모델 학습
선형 회귀 모델에서 학습이란 주어진 트레이닝 데이터의 특성을 가장 잘 표현할 수 있는 직선 $y = wx + b$의 기울기(가중치) $w$와 $y$절편(바이어스) $b$를 찾는 과정을 말한다.
신경망 관점에서 선형 회귀 모델은 입력층의 특징 변수가 출력층의 예측 변수로 mapping되는 과정이라고 말할 수 있다.
- 입력층
- 특징 변수들을 포함하며, 각 특징 변수는 하나의 뉴런에 대응한다.
- 각 뉴런의 가중치와 바이어스를 통해 출력층의 뉴런과 연결되며 이 떄 가중치와 바이어스를 파라미터라고 한다.
- 출력층
- 예측변수로, 선형 회귀 모델에서는 출력층이 단 하나의 뉴런으로 존재한다.
Pytorch에서 선형 회귀 모델을 구축할 때는 nn.Module 클래스에서 상속받아 생성할 수 있다.
nn.Module은 신경망의 모든 계층을 정의하기 위해 사용되는 기본 클래스로 이를 상속받아 신경망의 각 계층을 정의하고, 여러 계층들을 조합하여 복잡한 신경망 모델을 구축한다.
nn.Module의 장점은 일관성, 모듈화과 GPU 지원 뿐만 아니라 자동 미분과 최적화, 디버깅과 로깅 등 모델을 구축하는데 편리한 기능을 제공한다.
상속받는 코드 표현은 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
import torch
import torch.nn as nn
class LinearRegressionModel(nn.Module): # 클래스
def __init__(self): # 생성자 메서드
super(LinearRegressionModel, self).__init__() # 속성: 선형 계층 정의
self.linear = nn.Linear(1, 1)
def forward(self, x): # 메서드: 순전파 연산 정의
y = self.linear(x)
return y
model = LinearRegressionModel() # 인스턴스 생성
선형 회귀 모델의 성능은 오차를 이용하여 판단한다.
오차는 목표 변수 $t$와 예측 변수 $y$의 차이 $(t - y)$를 의미한다.
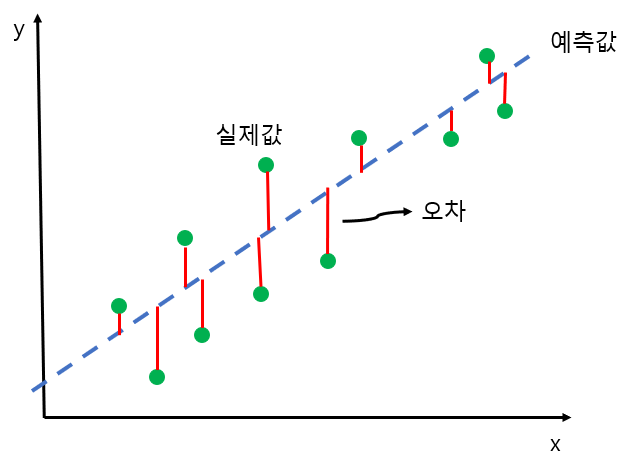
- 오차가 크다면 가중치 $w$와 바이어스 $b$의 값의 수정이 필요하다.
- 오차가 작다면 가중치 $w$와 바이어스 $b$의 값이 최적화되었다고 판단한다.
따라서, 선형 회귀 모델에서는 오차의 총합이 최소가 되는 $y = wx + b$ 함수의 가중치 $w$와 바이어스 $b$를 찾아야한다.
이러한 오차를 함수로 표현한 것을 손실 함수(loss function)라고 부른다.
이 때, 오차의 값들이 양수, 음수가 혼재할 수 있으므로 정확한 측정을 하기 위해서는 모든 오차에 절대값을 취하거나 오차에 제곱을 취해 음수를 없애주어야 한다.
특히, 오차의 제곱하는 방식은 오차를 크게 키우기 때문에 학습이 수월해진다. 또한 손실함수가 볼록함수 형태이기 때문에 다양한 최적화 기법을 적용할 수 있다.
이러한 방법을 평균제곱오차(Mean Squared Error)라고 하며 줄여서 MSE라고 한다.
위의 수식으로 부터 나온 결과값을 줄이는 방향으로 가중치($w$)와 바이어스($b$)를 줄여가야 한다.
이를 Pytorch 코드로 표현하면 loss_function = nn.MSELoss()이다.
경사하강법
경사하강법(Gradient Descent Algorithm)은 머신러닝 최적화(Optimization)알고리즘 중 하나로서, 주어진 손싫 함수에서 모델의 가중치와 바이어스의 최적의 값을 찾기 위해 사용한다.
작동 방식
트레이닝 데이터가 $(x_1, t_1) = (1, 0.5)$, $(x_2, t_2) = (2, 1)$, $(x_3, t_3) = (3, 1.5)$, $(x_4, t_4) = (4, 2)$와 같이 주어졌을 때, 가중치 $w$값의 변화에 따른 손실 값을 살펴보고, 그 값에서의 경사(기울기)를 확인하고자 함(계산 편의를 위해 바이어스는 0으로 가정)
가중치 $w$ 값에 따른 손실 함수의 수식을 표현하면 다음과 같다.
가중치 $w = -0.5$인 경우,
\[\begin{align*} l(-0.5, 0) &= \frac{1}{4} \sum_{i=1}^4 [t_i - (-0.5 \cdot + 0)]^2 \\ &= \frac{[0.5-(-0.5 \cdot 1 + 0)]^2 + [1 - (-0.5 \cdot 2 + 0)]^2 + [1.5 - (-0.5 \cdot 3 + 0)]^2 + [2 - (-0.5 \cdot 4 + 0)]^2}{4} \\ &= 7.5 \end{align*}\]가중치 $w = 0$인 경우,
\[\begin{align*} l(0, 0) &= \frac{1}{4} \sum_{i=1}^4 [t_i - (0 \cdot + 0)]^2 \\ &= \frac{[0.5-(0 \cdot 1 + 0)]^2 + [1 - (0 \cdot 2 + 0)]^2 + [1.5 - (0 \cdot 3 + 0)]^2 + [2 - (0 \cdot 4 + 0)]^2}{4} \\ &= 1.875 \end{align*}\]가중치 $w = 0.5$인 경우,
\[\begin{align*} l(0.5, 0) &= \frac{1}{4} \sum_{i=1}^4 [t_i - (0.5 \cdot + 0)]^2 \\ &= \frac{[0.5-(0.5 \cdot 1 + 0)]^2 + [1 - (0.5 \cdot 2 + 0)]^2 + [1.5 - (0.5 \cdot 3 + 0)]^2 + [2 - (0.5 \cdot 4 + 0)]^2}{4} \\ &= 0 \end{align*}\]가중치가 $w = 1$인 경우,
\[\begin{align*} l(1, 0) &= \frac{1}{4} \sum_{i=1}^4 [t_i - (1 \cdot + 0)]^2 \\ &= \frac{[0.5-(1 \cdot 1 + 0)]^2 + [1 - (1 \cdot 2 + 0)]^2 + [1.5 - (1 \cdot 3 + 0)]^2 + [2 - (1 \cdot 4 + 0)]^2}{4} \\ &= 1.875 \end{align*}\]
가중치 w값에 대한 경사(기울기)에 대한 수식을 표현하면 아래 그림과 같이 표현된다.
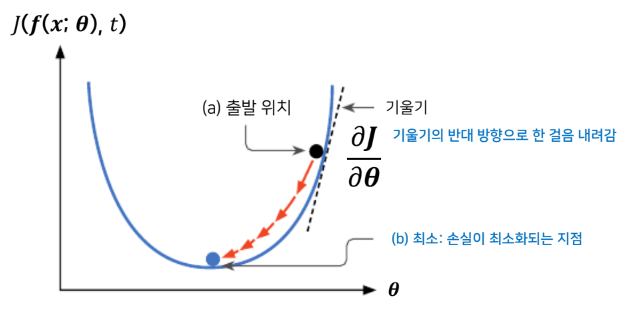
이를 $(w, l(w, b))$에서의 경사(기울기)에 대한 수식으로 표현하면 다음과 같다.
\[\begin{align*} \frac{\partial l(w, b)}{\partial w} &= \frac{\partial l(w, b)}{\partial y} \frac{\partial y}{\partial w} \\ &= \frac{1}{n} \cdot (-2) \sum_{i=1}^n (t_i - y_i) \frac{\partial y}{\partial w} \\ &= \frac{1}{n} \cdot (-2) \sum_{i=1}^n (t_i - y_i) \cdot x_i \end{align*}\]현재 손실 값에 대한 경사(기울기)를 자동 미분을 사용하여 계산하는 코드는 loss.backward() 이다. 이러한 경사값을 계산하는 과정을 역전파라고 한다.
이를 이용해서 가중치 $w$값을 업데이트할 수 있으며 이를 수식으로 표현하면 다음과 같이 표현한다.
\[w^{*} = w - \alpha \frac{\partial l (w, b)}{\partial w}\]여기서 $\alpha$는 학습률을 의미한다.
학습률은 하이퍼 파라미터로 모델이 학습할 때 가중치가 업데이트되는 크기를 결정한다. 학습률은 모델과 데이터에 따라 달라지기 때문에 실험과 검증을 통해 최적의 값을 찾는 것이 중요하다.
학습률에 따른 그래프를 표현하면 아래처럼 표현된다.

가중치 $w$값 업데이트를 수식으로 표현하면 다음과 같다.
\[\begin{align*} w^{*} &= w - \alpha \frac{\partial l (w, b)}{\partial w}\\ &= w - \alpha \frac{\partial l(w, b)}{\partial y} \frac{\partial y}{\partial w} \\ &= w - \alpha \bigg( \frac{1}{n} \cdot (-2) \sum_{i=1}^n (t_i - y_i) \cdot x_i \bigg) \end{align*}\]이를 코드로 표현하면 optimizer.step() 이다.
이 과정을 지속하여 가중치 $w$의 값을 지속적으로 업데이트해나간다. 이 때, 학습과정에서 경사값이 누적이 되기 때문에 정확한 경사값을 구하기 위해서는 optimizer.zero_grad()를 통해 계산된 경사(기울기)를 초기화해야한다.
위의 과정을 반복하여 기울기의 값이 0이 되면 손실 함수의 값의 최소값에 도달할 수 있다.
하지만 경사하강법에는 2가지 문제점을 가지고 있다.
- 대규모 데이터셋의 계산 비용 문제: 경사하강법은 전체 데이터셋을 사용하기 때문에 계산 비용이 매우 크다.
- 전체 데이터셋을 이용해서 가중치와 바이어스를 최적화하는 방식을
batch 경사하강법이라고 한다.
- 전체 데이터셋을 이용해서 가중치와 바이어스를 최적화하는 방식을
- 로컬 미니마(locial minima): 모델 학습 과정에서 손실 함수 값이 전체 함수에서 가장 낮은 전역 최소값(global minimum)이 아닌 주변 값들보다 낮은 지역적인 최소값에 머물 수 있다.
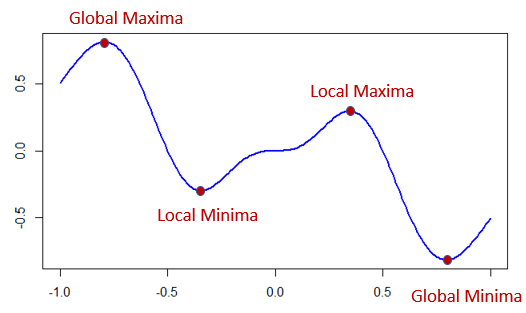
확률적 경사하강법
경사하강법의 문제점의 대안으로 확률적 경사하강법(stochastic gradient descent)이 등장했다.
확률적 경사하강법은 각각의 데이터 포인트마다 오차를 계산하여 가중치 $w$와 바이어스 $b$를 업데이트하는 최적화 알고리즘이다.
- 모든 데이터의 오차 계산이 아닌, 각각의 데이터 포인트마다 오차를 계산하는 방식으로 접근하여 계산량이 적다.
- 각 데이터 포인트의 기울기를 계산하는 과정에서 노이즈가 포함이 되며 이는 최적화 과정에서 로컬 미니마를 탈출하고 더 나은 글로벌 미니마에 도달하는데 용이하다.
확률적 경사하강법을 코드로 표현하면 다음과 같다.
- Pytorch의 최적화 모델의 코드 표현:
import torch.optim as optim - Pytorch에서 확률적 경사하강법 코드 표현:
optimizer = optim.SGD(model.parameters(), lr=0.01)
확률적 경사하강법을 수식으로 표현하면 다음과 같다.
\[\begin{align*} w^{*} &= w - \alpha \frac{\partial l (w, b)}{\partial w}\\ &= w - \alpha \textcolor{blue}{\bigg( \frac{1}{n} \cdot (-2)(t_i - y_i) \cdot x_i \bigg)} \end{align*}\]확률적 경사하강법에서도 경사하강법에서 사용한 코드를 그대로 사용한다.
에폭
에폭이란 모델이 전체 데이터셋을 한 번 완전히 학습하는 과정을 의미한다.
- ex. 데이터셋에 30개의 데이터가 있고, 에폭 수가 1이면, 모델은 30개의 데이터를 한 번 학습
에폭을 통해 동일한 데이터셋으로 여러 번의 에폭을 통해 모델을 반복 학습하며 이 때, 각 에폭마다 모델의 가중치 $w$값이 업데이트 되므로, 여러 번의 에폭을 통해 모델의 성능이 향상될 수 있다.
하지만 에폭 수가 너무 많으면 과적합(overfitting)될 수 있으므로 주의해야한다.
과적합(overfitting): 모델이 트레이닝 데이터에 너무 맞춰져서 새로운 데이터에 대한 일반화 능력이 떨어지는 현상
에폭은 num_epochs = 1000로 지정할 수 있다.
에폭을 반복하며 예측 변수와 손실 값을 계산하는 코드는 다음과 같다.
1
2
3
for epoch in range(num_epochs):
y = model(x_tensor)
loss = loss_function(y, t_tensor)
데이터 표준화
학습을 통해 얻은 손실값이 큰 경우 이를 해결하기 위한 방안으로 여러 가지가 있다.
- 학습률 낮추기
- 데이터에 노이지가 많거나 이상치가 존재할 수 있으므로 시각화하여 이상치를 확인하고 처리
- 에폭 수를 늘려보기
하지만 위의 세가지를 실행해도 해결되지 않는 경우기 있다.
이럴 때, 사용할 수 있는 방법으로 데이터 표준화가 있다.
데이터 표준화는 특징 변수의 값과 목표 변수 값이 차이가 클 때 두 변수의 평균을 0, 분산을 1로 맞추어 표준화하는 과정을 의미하며 이 과정은 데이터의 분포는 같지만 변수들의 값만 변한다.
데이터를 표준화하는 코드는 다음과 같다.
- 데이터를 표준화하는 모듈
from sklearn.preprocessing import StandardScaler
- StandardScaler 객체를 생성하는 코드
scaler_x = StandardScaler()
- 데이터를 표준화하는 코드
x_scaled = scaler_x.fit_transform(x.reshape(-1, 1))
모델 테스트
모델 테스트는 트레이닝 데이터에 포함되지 않은 새로운 데이터의 결과를 연속적인 숫자 값으로 예측한다.
테스트 데이터의 코드 표현은 아래와 같다.
- 테스트 데이터를 입력받아 예측된 연봉을 반환하는 함수 코드
def predict_test_data(test_data)
- 테스트 데이터를 표준화하는 코드
test_scaled = scaler_x.transform(test_data.reshape(-1, 1))
- 표준화한 테스트 데이터를 Pytorch Tensor로 변환하는 코드
test_tensor = torch.tensor(test_scaled, dtype=torch.float32).view(-1, 1).to(device)
모델을 평가 모드로 전환하는 코드
1 2 3
model.eval() with torch.no_grad(): predictions_scaled = model(test_tensor)
- 예측된 결과의 표준화를 해제하는 코드
predictions = scaler_t_inverse_transform(predictions_scaled.cpu().numpy())
이 글은 비밀번호로 보호되어 있습니다.